溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
認識事務
1.1 為什么需要數據庫事務
轉賬是生活中常見的操作,比如從A賬戶轉賬100元到B賬號。站在用戶角度而言,這是一個邏輯上的單一操作,然而在數據庫系統中,至少會分成兩個步驟來完成:
將A賬戶的金額減少100元
將B賬戶的金額增加100元。
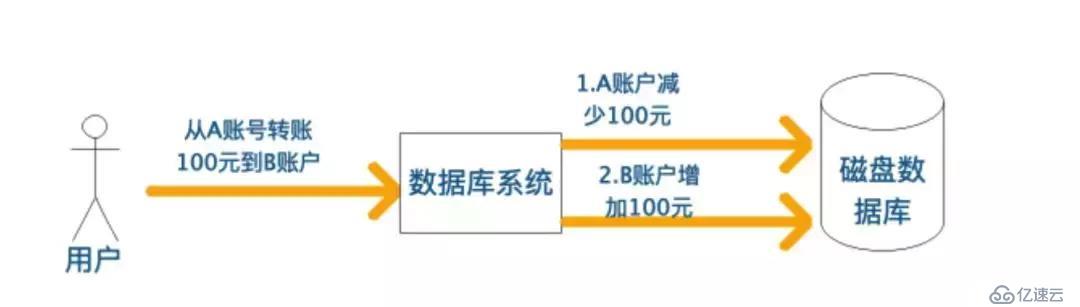
在這個過程中可能會出現以下問題:
轉賬操作的第一步執行成功,A賬戶上的錢減少了100元,但是第二步執行失敗或者未執行便發生系統崩潰,導致B賬戶并沒有相應增加100元。
轉賬操作剛完成就發生系統崩潰,系統重啟恢復時丟失了崩潰前的轉賬記錄。
同時又另一個用戶轉賬給B賬戶,由于同時對B賬戶進行操作,導致B賬戶金額出現異常。
為了便于解決這些問題,需要引入數據庫事務的概念。
1.2 什么是數據庫事務
定義:數據庫事務是構成單一邏輯工作單元的操作集合,一個典型的數據庫事務如下所示:

關于事務的定義有幾點需要解釋下:
數據庫事務可以包含一個或多個數據庫操作,但這些操作構成一個邏輯上的整體。
構成邏輯整體的這些數據庫操作,要么全部執行成功,要么全部不執行。
構成事務的所有操作,要么全都對數據庫產生影響,要么全都不產生影響,即不管事務是否執行成功,數據庫總能保持一致性狀態。
以上即使在數據庫出現故障以及并發事務存在的情況下依然成立。
1.3 事務如何解決問題
對于上面的轉賬例子,可以將轉賬相關的所有操作包含在一個事務中

當數據庫操作失敗或者系統出現崩潰,系統能夠以事務為邊界進行恢復,不會出現A賬戶金額減少而B賬戶未增加的情況。
當有多個用戶同時操作數據庫時,數據庫能夠以事務為單位進行并發控制,使多個用戶對B賬戶的轉賬操作相互隔離。
事務使系統能夠更方便的進行故障恢復以及并發控制,從而保證數據庫狀態的一致性。
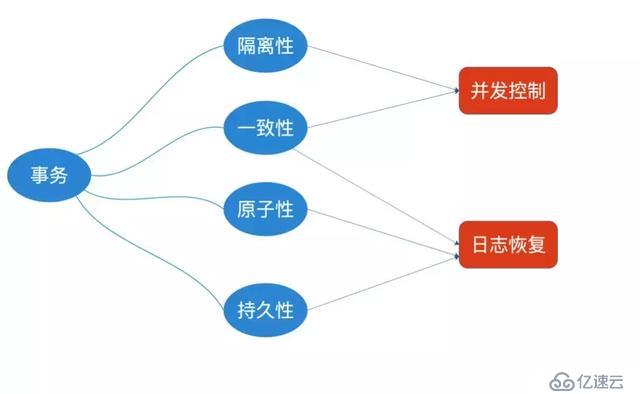
1.4 事務的ACID特性以及實現原理
原子性(Atomicity):事務中的所有操作作為一個整體像原子一樣不可分割,要么全部成功,要么全部失敗。
一致性(Consistency):事務的執行結果必須使數據庫從一個一致性狀態到另一個一致性狀態。
一致性狀態是指:
系統的狀態滿足數據的完整性約束(主碼,參照完整性,check約束等)
系統的狀態反應數據庫本應描述的現實世界的真實狀態,比如轉賬前后兩個賬戶的金額總和應該保持不變。
隔離性(Isolation):并發執行的事務不會相互影響,其對數據庫的影響和它們串行執行時一樣。
比如多個用戶同時往一個賬戶轉賬,最后賬戶的結果應該和他們按先后次序轉賬的結果一樣。
持久性(Durability):事務一旦提交,其對數據庫的更新就是持久的。任何事務或系統故障都不會導致數據丟失。
在事務的ACID特性中,C即一致性是事務的根本追求,而對數據一致性的破壞主要來自兩個方面:
事務的并發執行
事務故障或系統故障
數據庫系統是通過并發控制技術和日志恢復技術來避免這種情況發生的。
并發控制技術保證了事務的隔離性,使數據庫的一致性狀態不會因為并發執行的操作被破壞。
日志恢復技術保證了事務的原子性,使一致性狀態不會因事務或系統故障被破壞。
同時使已提交的對數據庫的修改不會因系統崩潰而丟失,保證了事務的持久性。
并發異常與并發控制
2.1 常見的并發異常
在講解并發控制技術前,先簡單介紹下數據庫常見的并發異常。
臟寫,臟寫是指事務回滾了其他事務對數據項的已提交修改,比如下面這種情況

在事務1對數據A的回滾,導致事務2對A的已提交修改也被回滾了。
丟失更新。丟失更新是指事務覆蓋了其他事務對數據的已提交修改,導致這些修改好像丟失了一樣。

事務1和事務2讀取A的值都為10,事務2先將A加上10并提交修改,之后事務2將A減少10并提交修改,A的值最后為,導致事務2對A的修改好像丟失了一樣
臟讀。臟讀是指一個事務讀取了另一個事務未提交的數據

在事務1對A的處理過程中,事務2讀取了A的值,但之后事務1回滾,導致事務2讀取的A是未提交的臟數據。
不可重復讀,指一個事務對同一數據的讀取結果前后不一致。
臟讀和不可重復讀的區別在于:前者讀取的是事務未提交的臟數據,后者讀取的是事務已經提交的數據,只不過因為數據被其他事務修改過導致前后兩次讀取的結果不一樣
比如下面這種情況
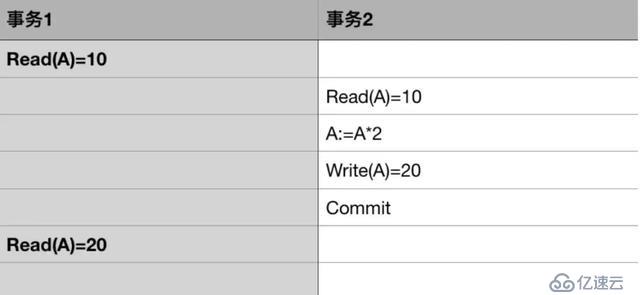
由于事務2對A的已提交修改,事務1前后兩次讀取的結果不一致。
幻讀。幻讀是指事務讀取某個范圍的數據時,因為其他事務的操作導致前后兩次讀取的結果不一致。
幻讀和不可重復讀的區別在于,不可重復讀是針對確定的某一行數據而言,而幻讀是針對不確定的多行數據。
因而幻讀通常出現在帶有查詢條件的范圍查詢中,比如下面這種情況:

事務1查詢A<5的數據,由于事務2插入了一條A=4的數據,導致事務1兩次查詢得到的結果不一樣
2.2 事務的隔離級別
事務具有隔離性,理論上來說事務之間的執行不應該相互產生影響,其對數據庫的影響應該和它們串行執行時一樣。
然而完全的隔離性會導致系統并發性能很低,降低對資源的利用率,因而實際上對隔離性的要求會有所放寬,這也會一定程度造成對數據庫一致性要求降低
SQL標準為事務定義了不同的隔離級別,從低到高依次是
讀未提交(READ UNCOMMITTED)
讀已提交(READ COMMITTED)
可重復讀(REPEATABLE READ)
串行化(SERIALIZABLE)
事務的隔離級別越低,可能出現的并發異常越多,但是通常而言系統能提供的并發能力越強。
不同的隔離級別與可能的并發異常的對應情況如下表所示
有一點需要強調,這種對應關系只是理論上的,對于特定的數據庫實現不一定準確
比如mysql的Innodb存儲引擎通過Next-Key Locking技術在可重復讀級別就消除了幻讀的可能。
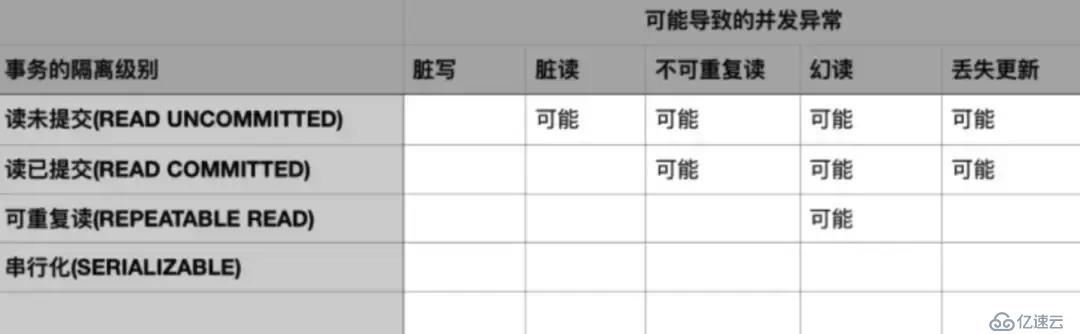
所有事務隔離級別都不允許出現臟寫,而串行化可以避免所有可能出現的并發異常,但是會極大的降低系統的并發處理能力。
2.3 事務隔離性的實現—常見的并發控制技術
并發控制技術是實現事務隔離性以及不同隔離級別的關鍵,實現方式有很多。按照其對可能沖突的操作采取的不同策略可以分為樂觀并發控制和悲觀并發控制兩大類。
樂觀并發控制:對于并發執行可能沖突的操作,假定其不會真的沖突,允許并發執行,直到真正發生沖突時才去解決沖突,比如讓事務回滾。
悲觀并發控制:對于并發執行可能沖突的操作,假定其必定發生沖突,通過讓事務等待(鎖)或者中止(時間戳排序)的方式使并行的操作串行執行。
2.3.1 基于封鎖的并發控制
核心思想:對于并發可能沖突的操作,比如讀-寫,寫-讀,寫-寫,通過鎖使它們互斥執行。
鎖通常分為共享鎖和排他鎖兩種類型
共享鎖(S):事務T對數據A加共享鎖,其他事務只能對A加共享鎖但不能加排他鎖。
排他鎖(X):事務T對數據A加排他鎖,其他事務對A既不能加共享鎖也不能加排他鎖
基于鎖的并發控制流程:
事務根據自己對數據項進行的操作類型申請相應的鎖(讀申請共享鎖,寫申請排他鎖)
申請鎖的請求被發送給鎖管理器。鎖管理器根據當前數據項是否已經有鎖以及申請的和持有的鎖是否沖突決定是否為該請求授予鎖。
若鎖被授予,則申請鎖的事務可以繼續執行;若被拒絕,則申請鎖的事務將進行等待,直到鎖被其他事務釋放。
可能出現的問題:
死鎖:多個事務持有鎖并互相循環等待其他事務的鎖導致所有事務都無法繼續執行。
饑餓:數據項A一直被加共享鎖,導致事務一直無法獲取A的排他鎖。
對于可能發生沖突的并發操作,鎖使它們由并行變為串行執行,是一種悲觀的并發控制。
2.3.2 基于時間戳的并發控制
核心思想:對于并發可能沖突的操作,基于時間戳排序規則選定某事務繼續執行,其他事務回滾。
系統會在每個事務開始時賦予其一個時間戳,這個時間戳可以是系統時鐘也可以是一個不斷累加的計數器值,當事務回滾時會為其賦予一個新的時間戳,先開始的事務時間戳小于后開始事務的時間戳。
每一個數據項Q有兩個時間戳相關的字段:
W-timestamp(Q):成功執行write(Q)的所有事務的最大時間戳
R-timestamp(Q):成功執行read(Q)的所有事務的最大時間戳
時間戳排序規則如下:
假設事務T發出read(Q),T的時間戳為TS
若TS(T)<w-timestamp(q),則t需要讀入的q已被覆蓋。此
read操作將被拒絕,T回滾。
若TS(T)>=W-timestamp(Q),則執行read操作,同時把R-timestamp(Q)設置為TS(T)與R-timestamp(Q)中的最大值
假設事務T發出write(Q)
若TS(T)<r-timestamp(q),write操作被拒絕,t回滾
若TS(T)<w-timestamp(q),則write操作被拒絕,t回滾
其他情況:系統執行write操作,將W-timestamp(Q)設置為TS(T)
基于時間戳排序和基于鎖實現的本質一樣:對于可能沖突的并發操作,以串行的方式取代并發執行,因而它也是一種悲觀并發控制。
它們的區別主要有兩點:
基于鎖是讓沖突的事務進行等待,而基于時間戳排序是讓沖突的事務回滾。
基于鎖沖突事務的執行次序是根據它們申請鎖的順序,先申請的先執行;而基于時間戳排序是根據特定的時間戳排序規則。
2.3.3 基于有效性檢查的并發控制
核心思想:事務對數據的更新首先在自己的工作空間進行,等到要寫回數據庫時才進行有效性檢查,對不符合要求的事務進行回滾。
基于有效性檢查的事務執行過程會被分為三個階段:
讀階段:數據項被讀入并保存在事務的局部變量中。所有write操作都是對局部變量進行,并不對數據庫進行真正的更新。
有效性檢查階段:對事務進行有效性檢查,判斷是否可以執行write操作而不違反可串行性。如果失敗,則回滾該事務。
寫階段:事務已通過有效性檢查,則將臨時變量中的結果更新到數據庫中。
有效性檢查通常也是通過對事務的時間戳進行比較完成的,不過和基于時間戳排序的規則不一樣。
該方法允許可能沖突的操作并發執行,因為每個事務操作的都是自己工作空間的局部變量,直到有效性檢查階段發現了沖突才回滾。因而這是一種樂觀的并發策略。
2.3.4 基于快照隔離的并發控制
快照隔離是多版本并發控制(mvcc)的一種實現方式。
其核心思想是:數據庫為每個數據項維護多個版本(快照),每個事務只對屬于自己的私有快照進行更新,在事務真正提交前進行有效性檢查,使得事務正常提交更新或者失敗回滾。
由于快照隔離導致事務看不到其他事務對數據項的更新,為了避免出現丟失更新問題,可以采用以下兩種方案避免:
先提交者獲勝:對于執行該檢查的事務T,判斷是否有其他事務已經將更新寫入數據庫,是則T回滾否則T正常提交。
先更新者獲勝:通過鎖機制保證第一個獲得鎖的事務提交其更新,之后試圖更新的事務中止。
事務間可能沖突的操作通過數據項的不同版本的快照相互隔離,到真正要寫入數據庫時才進行沖突檢測。因而這也是一種樂觀并發控制。
故障與故障恢復
3.1 為什么需要故障恢復技術
數據庫運行過程中可能會出現故障,這些故障包括事務故障和系統故障兩大類
事務故障:比如非法輸入,系統出現死鎖,導致事務無法繼續執行。
系統故障:比如由于軟件漏洞或硬件錯誤導致系統崩潰或中止。
這些故障可能會對事務和數據庫狀態造成破壞,因而必須提供一種技術來對各種故障進行恢復,保證數據庫一致性,事務的原子性以及持久性。
數據庫通常以日志的方式記錄數據庫的操作從而在故障時進行恢復,因而可以稱之為日志恢復技術。
3.2 事務的執行過程以及可能產生的問題
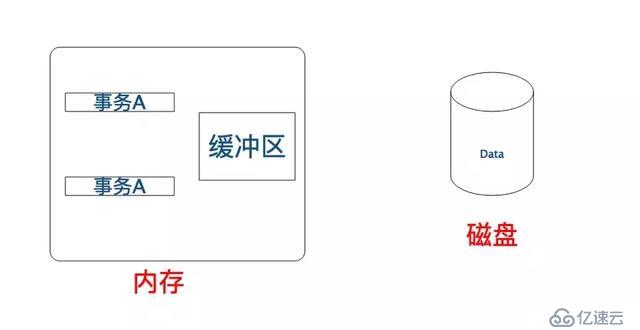
事務的執行過程可以簡化如下:
系統會為每個事務開辟一個私有工作區
事務讀操作將從磁盤中拷貝數據項到工作區中,在執行寫操作前所有的更新都作用于工作區中的拷貝.
事務的寫操作將把數據輸出到內存的緩沖區中,等到合適的時間再由緩沖區管理器將數據寫入到磁盤。
由于數據庫存在立即修改和延遲修改,所以在事務執行過程中可能存在以下情況:
在事務提交前出現故障,但是事務對數據庫的部分修改已經寫入磁盤數據庫中。這導致了事務的原子性被破壞。
在系統崩潰前事務已經提交,但數據還在內存緩沖區中,沒有寫入磁盤。系統恢復時將丟失此次已提交的修改。這是對事務持久性的破壞。
3.3 日志的種類和格式
<T,X,V1,V2>:描述一次數據庫寫操作,T是執行寫操作的事務的唯一標識,X是要寫的數據項,V1是數據項的舊值,V2是數據項的新值。
<T,X,V1>:對數據庫寫操作的撤銷操作,將事務T的X數據項恢復為舊值V1。在事務恢復階段插入。
<T start>: 事務T開始
<T commit>: 事務T提交
<T,abort>: 事務T中止
關于日志,有以下兩條規則
系統在對數據庫進行修改前會在日志文件末尾追加相應的日志記錄。
當一個事務的commit日志記錄寫入到磁盤成功后,稱這個事務已提交,但事務所做的修改可能并未寫入磁盤
3.4 日志恢復的核心思想
撤銷事務undo:將事務更新的所有數據項恢復為日志中的舊值,事務撤銷完畢時將插入一條<T abort>記錄。
重做事務redo:將事務更新的所有數據項恢復為日志中的新值。
事務正常回滾/因事務故障中止將進行redo,系統從崩潰中恢復時將先進行redo再進行undo。
以下事務將進行undo:日志中只包括<T start>記錄,但既不包括<T commit>記錄也不包括<T abort>記錄.
以下事務將進行redo:日志中包括<T start>記錄,也包括<T commit>記錄或<T abort>記錄。
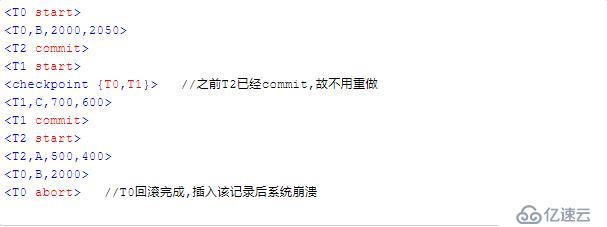
假設系統從崩潰中恢復時日志記錄如下

由于T0既有start記錄又有commit記錄,將會對事務T0進行重做,執行相應的redo操作。
由于T1只有start記錄,將會對T1進行撤銷,執行相應的undo操作,撤銷完畢將寫入一條abort記錄。
3.5 事務故障中止/正常回滾的恢復流程
從后往前掃描日志,對于事務T的每個形如<T,X,V1,V2>的記錄,將舊值V1寫入數據項X中。
往日志中寫一個特殊的只讀記錄<T,X,V1>,表示將數據項恢復成舊值V1,這是一個只讀的補償記錄,不需要根據它進行undo。
一旦發現<T start>日志記錄,就停止繼續掃描,并往日志中寫一個
<T abort>日志記錄。

3.6 系統崩潰時的恢復過程(帶檢查點)
檢查點是形如<checkpoint L>的特殊的日志記錄,L是寫入檢查點記錄時還未提交的事務的集合
系統保證在檢查點之前已經提交的事務對數據庫的修改已經寫入磁盤,不需要進行redo。檢查點可以加快恢復的過程。
系統奔潰時的恢復過程分為兩個階段:重做階段和撤銷階段。
重做階段:
系統從最后一個檢查點開始正向的掃描日志,將要重做的事務的列表undo-list設置為檢查點日志記錄中的L列表。
發現<T,X,V1,V2>的更新記錄或<T,X,V>的補償撤銷記錄,就重做該操作。
發現<T start>記錄,就把T加入到undo-list中。
發現<T abort>或<T commit>記錄,就把T從undo-list中去除。
撤銷階段:
系統從尾部開始反向掃描日志
發現屬于undo-list中的事務的日志記錄,就執行undo操作
發現undo-list中事務的T的<T start>記錄,就寫入一條<T abort>記錄,
并把T從undo-list中去除。
undo-list為空,則撤銷階段結束
總結:先將日志記錄中所有事務的更新按順序重做一遍,在針對需要撤銷的事務按相反的順序執行其更新操作的撤銷操作。
3.6.1 一個系統崩潰恢復的例子
恢復前的日志如下,寫入最后一條日志記錄后系統崩潰

總結
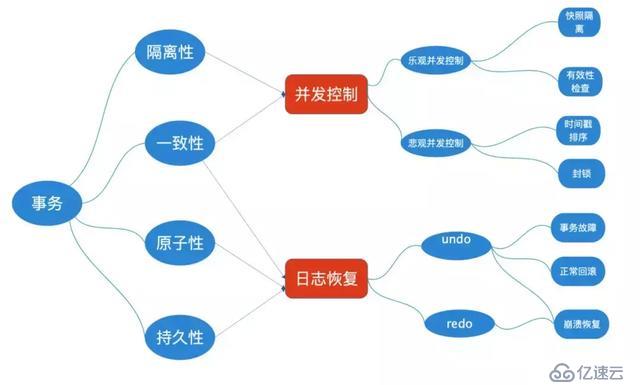
事務是數據庫系統進行并發控制的基本單位,是數據庫系統進行故障恢復的基本單位,從而也是保持數據庫狀態一致性的基本單位。
ACID是事務的基本特性,數據庫系統是通過并發控制技術和日志恢復技術來對事務的ACID進行保證的,從而可以得到如下的關于數據庫事務的概念體系結構。
?
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





