溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
有這樣一個場景,在HBase中需要分頁查詢,同時根據某一列的值進行過濾。
不同于RDBMS天然支持分頁查詢,HBase要進行分頁必須由自己實現。據我了解的,目前有兩種方案, 一是《HBase權威指南》中提到的用PageFilter加循環動態設置startRow實現,詳細見這里。但這種方法效率比較低,且有冗余查詢。因此京東研發了一種用額外的一張表來保存行序號的方案。 該種方案效率較高,但實現麻煩些,需要維護一張額外的表。
不管是方案也好,人也好,沒有最好的,只有最適合的。
在我司的使用場景中,對于性能的要求并不高,所以采取了第一種方案。本來使用的美滋滋,但有一天需要在分頁查詢的同時根據某一列的值進行過濾。根據列值過濾,自然是用SingleColumnValueFilter(下文簡稱SCVFilter)。代碼大致如下,只列出了本文主題相關的邏輯,
Scan?scan?=?initScan(xxx); FilterList?filterList=new?FilterList(); scan.setFilter(filterList); filterList.addFilter(new?PageFilter(1)); filterList.addFilter(new?SingleColumnValueFilter(FAMILY,ISDELETED,?CompareFilter.CompareOp.EQUAL,?Bytes.toBytes(false)));
數據如下
row1?????????????????column=f:content,?timestamp=1513953705613,?value=content1 ?row1?????????????????column=f:isDel,?timestamp=1513953705613,?value=1 ?row1?????????????????column=f:name,?timestamp=1513953725029,?value=name1 ?row2?????????????????column=f:content,?timestamp=1513953705613,?value=content2 ?row2?????????????????column=f:isDel,?timestamp=1513953744613,?value=0 ?row2?????????????????column=f:name,?timestamp=1513953730348,?value=name2 ?row3?????????????????column=f:content,?timestamp=1513953705613,?value=content3 ?row3?????????????????column=f:isDel,?timestamp=1513953751332,?value=0 ?row3?????????????????column=f:name,?timestamp=1513953734698,?value=name3
在上面的代碼中。向scan添加了兩個filter:首先添加了PageFilter,限制這次查詢數量為1,然后添加了一個SCVFilter,限制了只返回isDeleted=false的行。
上面的代碼,看上去無懈可擊,但在運行時卻沒有查詢到數據!
剛好最近在看HBase的代碼,就在本地debug了下HBase服務端Filter相關的查詢流程。
首先看下HBase Filter的流程,見圖:
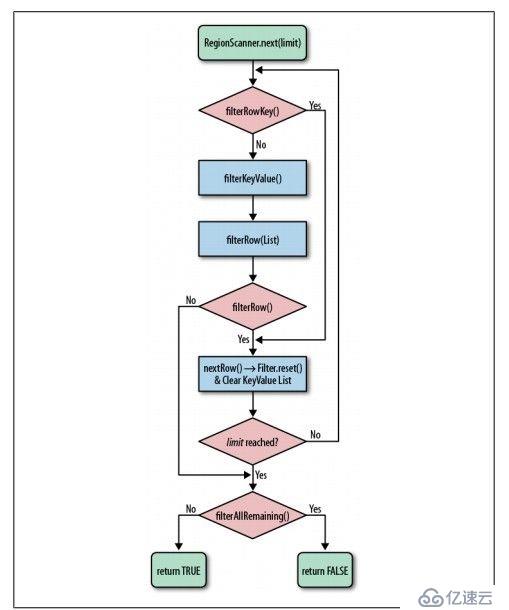
然后再看PageFilter的實現邏輯。
public?class?PageFilter?extends?FilterBase?{
??private?long?pageSize?=?Long.MAX_VALUE;
??private?int?rowsAccepted?=?0;
??/**
???*?Constructor?that?takes?a?maximum?page?size.
???*
???*?@param?pageSize?Maximum?result?size.
???*/
??public?PageFilter(final?long?pageSize)?{
????Preconditions.checkArgument(pageSize?>=?0,?"must?be?positive?%s",?pageSize);
????this.pageSize?=?pageSize;
??}
??public?long?getPageSize()?{
????return?pageSize;
??}
??@Override
??public?ReturnCode?filterKeyValue(Cell?ignored)?throws?IOException?{
????return?ReturnCode.INCLUDE;
??}
?
??public?boolean?filterAllRemaining()?{
????return?this.rowsAccepted?>=?this.pageSize;
??}
??public?boolean?filterRow()?{
????this.rowsAccepted++;
????return?this.rowsAccepted?>?this.pageSize;
??}
??
}其實很簡單,內部有一個計數器,每次調用filterRow的時候,計數器都會+1,如果計數器值大于pageSize,filterrow就會返回true,那之后的行就會被過濾掉。
再看SCVFilter的實現邏輯。
public?class?SingleColumnValueFilter?extends?FilterBase?{
??private?static?final?Log?LOG?=?LogFactory.getLog(SingleColumnValueFilter.class);
??protected?byte?[]?columnFamily;
??protected?byte?[]?columnQualifier;
??protected?CompareOp?compareOp;
??protected?ByteArrayComparable?comparator;
??protected?boolean?foundColumn?=?false;
??protected?boolean?matchedColumn?=?false;
??protected?boolean?filterIfMissing?=?false;
??protected?boolean?latestVersionOnly?=?true;
?
??/**
???*?Constructor?for?binary?compare?of?the?value?of?a?single?column.??If?the
???*?column?is?found?and?the?condition?passes,?all?columns?of?the?row?will?be
???*?emitted.??If?the?condition?fails,?the?row?will?not?be?emitted.
???*?<p>
???*?Use?the?filterIfColumnMissing?flag?to?set?whether?the?rest?of?the?columns
???*?in?a?row?will?be?emitted?if?the?specified?column?to?check?is?not?found?in
???*?the?row.
???*
???*?@param?family?name?of?column?family
???*?@param?qualifier?name?of?column?qualifier
???*?@param?compareOp?operator
???*?@param?comparator?Comparator?to?use.
???*/
??public?SingleColumnValueFilter(final?byte?[]?family,?final?byte?[]?qualifier,
??????final?CompareOp?compareOp,?final?ByteArrayComparable?comparator)?{
????this.columnFamily?=?family;
????this.columnQualifier?=?qualifier;
????this.compareOp?=?compareOp;
????this.comparator?=?comparator;
??}
?
???
??@Override
??public?ReturnCode?filterKeyValue(Cell?c)?{
????if?(this.matchedColumn)?{
??????//?We?already?found?and?matched?the?single?column,?all?keys?now?pass
??????return?ReturnCode.INCLUDE;
????}?else?if?(this.latestVersionOnly?&&?this.foundColumn)?{
??????//?We?found?but?did?not?match?the?single?column,?skip?to?next?row
??????return?ReturnCode.NEXT_ROW;
????}
????if?(!CellUtil.matchingColumn(c,?this.columnFamily,?this.columnQualifier))?{
??????return?ReturnCode.INCLUDE;
????}
????foundColumn?=?true;
????if?(filterColumnValue(c.getValueArray(),?c.getValueOffset(),?c.getValueLength()))?{
??????return?this.latestVersionOnly??ReturnCode.NEXT_ROW:?ReturnCode.INCLUDE;
????}
????this.matchedColumn?=?true;
????return?ReturnCode.INCLUDE;
??}
?
??
??private?boolean?filterColumnValue(final?byte?[]?data,?final?int?offset,
??????final?int?length)?{
????int?compareResult?=?this.comparator.compareTo(data,?offset,?length);
????switch?(this.compareOp)?{
????case?LESS:
??????return?compareResult?<=?0;
????case?LESS_OR_EQUAL:
??????return?compareResult?<?0;
????case?EQUAL:
??????return?compareResult?!=?0;
????case?NOT_EQUAL:
??????return?compareResult?==?0;
????case?GREATER_OR_EQUAL:
??????return?compareResult?>?0;
????case?GREATER:
??????return?compareResult?>=?0;
????default:
??????throw?new?RuntimeException("Unknown?Compare?op?"?+?compareOp.name());
????}
??}
??public?boolean?filterRow()?{
????//?If?column?was?found,?return?false?if?it?was?matched,?true?if?it?was?not
????//?If?column?not?found,?return?true?if?we?filter?if?missing,?false?if?not
????return?this.foundColumn??!this.matchedColumn:?this.filterIfMissing;
??}
???
?
}在HBase中,對于每一行的每一列都會調用到filterKeyValue,SCVFilter的該方法處理邏輯如下:
1.?如果已經匹配過對應的列并且對應列的值符合要求,則直接返回INCLUE,表示這一行的這一列要被加入到結果集 2.?否則如latestVersionOnly為true(latestVersionOnly代表是否只查詢最新的數據,一般為true),并且已經匹配過對應的列(但是對應的列的值不滿足要求),則返回EXCLUDE,代表丟棄該行 3.?如果當前列不是要匹配的列。則返回INCLUDE,否則將matchedColumn置為true,代表以及找到了目標列 4.?如果當前列的值不滿足要求,在latestVersionOnly為true時,返回NEXT_ROW,代表忽略當前行還剩下的列,直接跳到下一行 5.?如果當前列的值滿足要求,將matchedColumn置為true,代表已經找到了對應的列,并且對應的列值滿足要求。這樣,該行下一列再進入這個方法時,到第1步就會直接返回,提高匹配效率
再看filterRow方法,該方法調用時機在filterKeyValue之后,對每一行只會調用一次。
SCVFilter中該方法邏輯很簡單:
1.?如果找到了對應的列,如其值滿足要求,則返回false,代表將該行加入到結果集,如其值不滿足要求,則返回true,代表過濾該行 2.?如果沒找到對應的列,返回filterIfMissing的值。
是不是因為將PageFilter添加到SCVFilter的前面,當判斷第一行的時候,調用PageFilter的filterRow,導致PageFilter的計數器+1,但是進行到SCVFilter的filterRow的時候,該行又被過濾掉了,在檢驗下一行時,因為PageFilter計數器已經達到了我們設定的pageSize,所以接下來的行都會被過濾掉,返回結果沒有數據。
在FilterList中,先加入SCVFilter,再加入PageFilter
Scan?scan?=?initScan(xxx); FilterList?filterList=new?FilterList(); scan.setFilter(filterList); filterList.addFilter(new?SingleColumnValueFilter(FAMILY,ISDELETED,?CompareFilter.CompareOp.EQUAL,? Bytes.toBytes(false))); filterList.addFilter(new?PageFilter(1));
結果是我們期望的第2行的值。
當要將PageFilter和其他Filter使用時,最好將PageFilter加入到FilterList的末尾,否則可能會出現結果個數小于你期望的數量。
(其實正常情況PageFilter返回的結果數量可能大于設定的值,因為服務器集群的PageFilter是隔離的。)
其實,在排查問題的過程中,并沒有這樣順利,因為問題出在線上,所以我在本地查問題時自己造了一些測試數據,令人驚訝的是,就算我先加入SCVFilter,再加入PageFilter,返回的結果也是符合預期的。
測試數據如下:
row1?????????????????column=f:isDel,?timestamp=1513953705613,?value=1 ?row1?????????????????column=f:name,?timestamp=1513953725029,?value=name1 ?row2?????????????????column=f:isDel,?timestamp=1513953744613,?value=0 ?row2?????????????????column=f:name,?timestamp=1513953730348,?value=name2 ?row3?????????????????column=f:isDel,?timestamp=1513953751332,?value=0 ?row3?????????????????column=f:name,?timestamp=1513953734698,?value=name3
當時在本地一直不能復現問題。很是苦惱,最后竟然發現使用SCVFilter查詢的結果還和數據的列的順序有關。
在服務端,HBase會對客戶端傳遞過來的filter封裝成FilterWrapper。
class?RegionScannerImpl?implements?RegionScanner?{
????RegionScannerImpl(Scan?scan,?List<KeyValueScanner>?additionalScanners,?HRegion?region)
????????throws?IOException?{
??????this.region?=?region;
??????this.maxResultSize?=?scan.getMaxResultSize();
??????if?(scan.hasFilter())?{
????????this.filter?=?new?FilterWrapper(scan.getFilter());
??????}?else?{
????????this.filter?=?null;
??????}
????}
???....
}在查詢數據時,在HRegion的nextInternal方法中,會調用FilterWrapper的filterRowCellsWithRet方法
FilterWrapper相關代碼如下:
/**
?*?This?is?a?Filter?wrapper?class?which?is?used?in?the?server?side.?Some?filter
?*?related?hooks?can?be?defined?in?this?wrapper.?The?only?way?to?create?a
?*?FilterWrapper?instance?is?passing?a?client?side?Filter?instance?through
?*?{@link?org.apache.hadoop.hbase.client.Scan#getFilter()}.
?*?
?*/
?
final?public?class?FilterWrapper?extends?Filter?{
??Filter?filter?=?null;
??public?FilterWrapper(?Filter?filter?)?{
????if?(null?==?filter)?{
??????//?ensure?the?filter?instance?is?not?null
??????throw?new?NullPointerException("Cannot?create?FilterWrapper?with?null?Filter");
????}
????this.filter?=?filter;
??}
?
??public?enum?FilterRowRetCode?{
????NOT_CALLED,
????INCLUDE,?????//?corresponds?to?filter.filterRow()?returning?false
????EXCLUDE??????//?corresponds?to?filter.filterRow()?returning?true
??}
??
??public?FilterRowRetCode?filterRowCellsWithRet(List<Cell>?kvs)?throws?IOException?{
????this.filter.filterRowCells(kvs);
????if?(!kvs.isEmpty())?{
??????if?(this.filter.filterRow())?{
????????kvs.clear();
????????return?FilterRowRetCode.EXCLUDE;
??????}
??????return?FilterRowRetCode.INCLUDE;
????}
????return?FilterRowRetCode.NOT_CALLED;
??}
?
}這里的kvs就是一行數據經過filterKeyValue后沒被過濾的列。
可以看到當kvs不為empty時,filterRowCellsWithRet方法中會調用指定filter的filterRow方法,上面已經說過了,PageFilter的計數器就是在其filterRow方法中增加的。
而當kvs為empty時,PageFilter的計數器就不會增加了。再看我們的測試數據,因為行的第一列就是SCVFilter的目標列isDeleted。回顧上面SCVFilter的講解我們知道,當一行的目標列的值不滿足要求時,該行剩下的列都會直接被過濾掉!
對于測試數據第一行,走到filterRowCellsWithRet時kvs是empty的。導致PageFilter的計數器沒有+1。還會繼續遍歷剩下的行。從而使得返回的結果看上去是正常的。
而出問題的數據,因為在列isDeleted之前還有列content,所以當一行的isDeleted不滿足要求時,kvs也不會為empty。因為列content的值已經加入到kvs中了(這些數據要調用到SCVFilter的filterrow的時間會被過濾掉)。
從實現上來看HBase的Filter的實現還是比較粗糙的。效率也比較感人,不考慮網絡傳輸和客戶端內存的消耗,基本上和你在客戶端過濾差不多。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





