溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
分頁應該是極為常見的數據展現方式了,一般在數據集較大而無法在單個頁面中呈現時會采用分頁的方法。
各種前端UI組件在實現上也都會支持分頁的功能,而數據交互呈現所相應的后端系統、數據庫都對數據查詢的分頁提供了良好的支持。
以幾個流行的數據庫為例:
查詢表 t_data 第 2 頁的數據(假定每頁 5 條)
MySQL 的做法:
select * from t_data limit 5,5PostGreSQL 的做法:
select * from t_data limit 5 offset 5db.t_data.find().limit(5).skip(5);盡管每種數據庫的語法不盡相同,通過一些開發框架封裝的接口,我們可以不需要熟悉這些差異。如 SpringData 提供的分頁接口:
public interface PagingAndSortingRepository<T, ID extends Serializable>
extends CrudRepository<T, ID> {
Page<T> findAll(Pageable pageable);
}這樣看來,開發一個分頁的查詢功能是非常簡單的。
然而萬事皆不可能盡全盡美,盡管上述的數據庫、開發框架提供了基礎的分頁能力,在面對日益增長的海量數據時卻難以應對,一個明顯的問題就是查詢性能低下!
那么,面對千萬級、億級甚至更多的數據集時,分頁功能該怎么實現?
下面,我以 MongoDB 作為背景來探討幾種不同的做法。
就是最常規的方案,假設 我們需要對文章 articles 這個表(集合) 進行分頁展示,一般前端會需要傳遞兩個參數:
按照這個做法的查詢方式,如下圖所示:
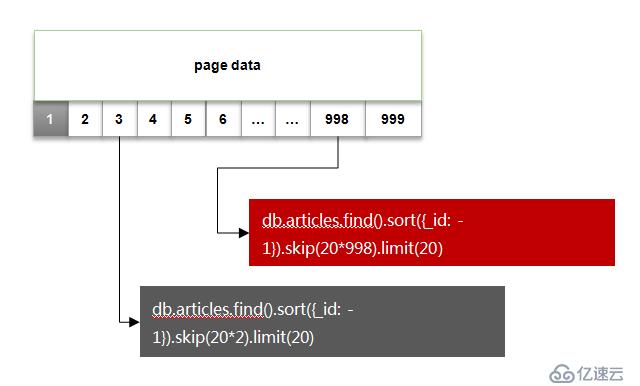
因為是希望最后創建的文章顯示在前面,這里使用了_id 做降序排序。
其中紅色部分語句的執行計劃如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : []
},
"winningPlan" : {
"stage" : "SKIP",
"skipAmount" : 19960,
"inputStage" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"[MaxKey, MinKey]"
]
...
}可以看到隨著頁碼的增大,skip 跳過的條目也會隨之變大,而這個操作是通過 cursor 的迭代器來實現的,對于cpu的消耗會比較明顯。
而當需要查詢的數據達到千萬級及以上時,會發現響應時間非常的長,可能會讓你幾乎無法接受!
或許,假如你的機器性能很差,在數十萬、百萬數據量時已經會出現瓶頸
既然傳統的分頁方案會產生 skip 大量數據的問題,那么能否避免呢?答案是可以的。
改良的做法為:
如下圖所示:
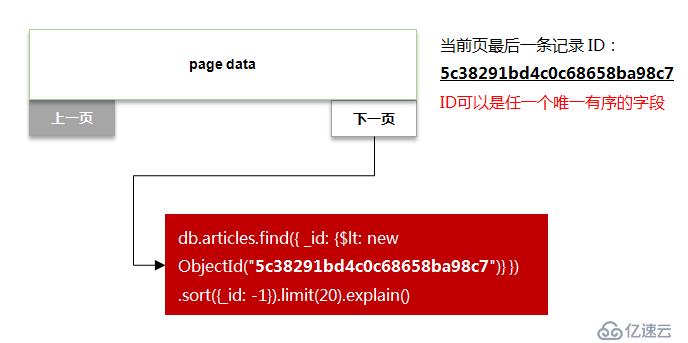
修改后的語句執行計劃如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"_id" : {
"$lt" : ObjectId("5c38291bd4c0c68658ba98c7")
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"(ObjectId('5c38291bd4c0c68658ba98c7'), ObjectId('000000000000000000000000')]"
]
...
}可以看到,改良后的查詢操作直接避免了昂貴的 skip 階段,索引命中及掃描范圍也是非常合理的!
為了對比這兩種方案的性能差異,下面準備了一組測試數據。
測試方案
準備10W條數據,以每頁20條的參數從前往后翻頁,對比總體翻頁的時間消耗
db.articles.remove({});
var count = 100000;
var items = [];
for(var i=1; i<=count; i++){
var item = {
"title" : "論年輕人思想建設的重要性-" + i,
"author" : "王小兵-" + Math.round(Math.random() * 50),
"type" : "雜文-" + Math.round(Math.random() * 10) ,
"publishDate" : new Date(),
} ;
items.push(item);
if(i%1000==0){
db.test.insertMany(items);
print("insert", i);
items = [];
}
}傳統翻頁腳本
function turnPages(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentPage = 0;
//輪詢翻頁
while(currentPage < pageTotal){
var list = db.articles.find({}, {_id:1}).sort({_id: -1}).skip(currentPage*pageSize).limit(pageSize);
dl = list.toArray();
//沒有更多記錄
if(dl.length == 0){
break;
}
currentPage ++;
//printjson(dl)
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/1000).toFixed(2)
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}改良翻頁腳本
function turnPageById(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentId = 0;
var currentPage = 0;
while(currentPage ++ < pageTotal){
//以上一頁的ID值作為起始值
var condition = currentId? {_id: {$lt: currentId}}: {};
var list = db.articles.find(condition, {_id:1}).sort({_id: -1}).limit(pageSize);
dl = list.toArray();
//沒有更多記錄
if(dl.length == 0){
break;
}
//記錄最后一條數據的ID
currentId = dl[dl.length-1]._id;
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/1000).toFixed(2)
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}以100、500、1000、3000頁數的樣本進行實測,結果如下:

可見,當頁數越大(數據量越大)時,改良的翻頁效果提升越明顯!
這種分頁方案其實采用的就是時間軸(TImeLine)的模式,實際應用場景也非常的廣,比如Twitter、微博、朋友圈動態都可采用這樣的方式。
而同時除了上述的數據庫之外,HBase、ElastiSearch 在Range Query的實現上也支持這種模式。
時間軸(TimeLine)的模式通常是做成“加載更多”、上下翻頁這樣的形式,但無法自由的選擇某個頁碼。
那么為了實現頁碼分頁,同時也避免傳統方案帶來的 skip 性能問題,我們可以采取一種折中的方案。
這里參考Google搜索結果頁作為說明:

通常在數據量非常大的情況下,頁碼也會有很多,于是可以采用頁碼分組的方式。
以一段頁碼作為一組,每一組內數據的翻頁采用ID 偏移量 + 少量的 skip 操作實現
具體的操作如下圖所示:

實現步驟
對頁碼進行分組(groupSize=8, pageSize=20),每組為8個頁碼;
提前查詢 end_offset,同時獲得本組頁碼數量:
db.articles.find({ _id: { $lt: start_offset } }).sort({_id: -1}).skip(20*8).limit(1)隨著物聯網,大數據業務的白熱化,一般企業級系統的數據量也會呈現出快速的增長。而傳統的數據庫分頁方案在海量數據場景下很難滿足性能的要求。
在本文的探討中,主要為海量數據的分頁提供了幾種常見的優化方案(以MongoDB作為實例),并在性能上做了一些對比,旨在提供一些參考。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





