溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
常用的SQL數據庫的數據都是存在磁盤中的,雖然在數據庫底層也做了對應的緩存來減少數據庫的IO壓力,但由于數據庫的緩存一般是針對查詢的內容,而且粒度也比較小,一般只有表中的數據沒有發生變動的時候,數據庫的緩存才會產生作用,但這并不能減少業務邏輯對數據庫的增刪改操作的IO壓力,因此緩存技術應運而生,該技術實現了對熱點數據的高速緩存,可以大大緩解后端數據庫的壓力。
主流應用架構
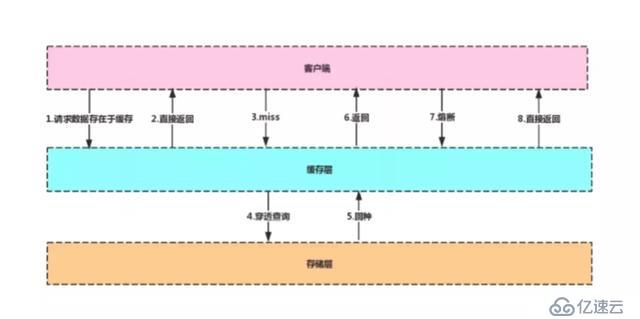
客戶端在對數據庫發起請求時,先到緩存層查看是否有所需的數據,如果緩存層存有客戶端所需的數據,則直接從緩存層返回,否則進行穿透查詢,對數據庫進行查詢,如果在數據庫中查詢到該數據,則將該數據回寫到緩存層,以便下次客戶端再次查詢能夠直接從緩存層獲取數據。
緩存中間件 -- Memcache和Redis的區別
Memcache:代碼層類似Hash
1.支持簡單數據類型
2.不支持數據持久化存儲
3.不支持主從
4.不支持分片
Redis
1.數據類型豐富
2.支持數據磁盤持久化存儲
3.支持主從
4.支持分片
為什么Redis能這么快
Redis的效率很高,官方給出的數據是100000+QPS(query per second),這是因為:
1.Redis完全基于內存,絕大部分請求是純粹的內存操作,執行效率高。
2.Redis使用單進程單線程模型的(K,V)數據庫,將數據存儲在內存中,存取均不會受到硬盤IO的限制,因此其執行速度極快,另外單線程也能處理高并發請求,還可以避免頻繁上下文切換和鎖的競爭,如果想要多核運行也可以啟動多個實例。
3.數據結構簡單,對數據操作也簡單,Redis不使用表,不會強制用戶對各個關系進行關聯,不會有復雜的關系限制,其存儲結構就是鍵值對,類似于HashMap,HashMap最大的優點就是存取的時間復雜度為O(1)。
4.Redis使用多路I/O復用模型,為非阻塞IO(非阻塞IO會另寫一篇解釋,可以先行百度)。
注:Redis采用的I/O多路復用函數:epoll/kqueue/evport/select
選用策略:
1.因地制宜,優先選擇時間復雜度為O(1)的I/O多路復用函數作為底層實現。
2.由于select要遍歷每一個IO,所以其時間復雜度為O(n),通常被作為保底方案。
3.基于react設計模式監聽I/O事件。
String
最基本的數據類型,其值最大可存儲512M,二進制安全(Redis的String可以包含任何二進制數據,包含jpg對象等)。
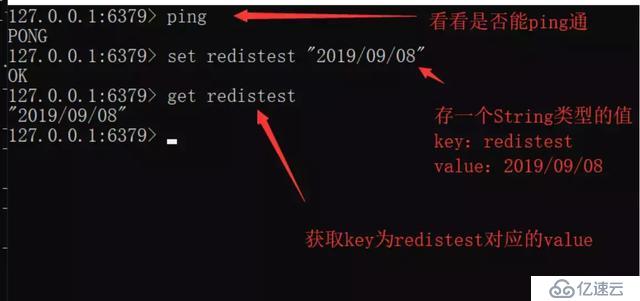
注:如果重復寫入key相同的鍵值對,后寫入的會將之前寫入的覆蓋。
Hash
String元素組成的字典,適用于存儲對象。

List
列表,按照String元素插入順序排序。其順序為后進先出。由于其具有棧的特性,所以可以實現如“最新消息排行榜”這類的功能。

Set
String元素組成的無序集合,通過哈希表實現(增刪改查時間復雜度為O(1)),不允許重復。
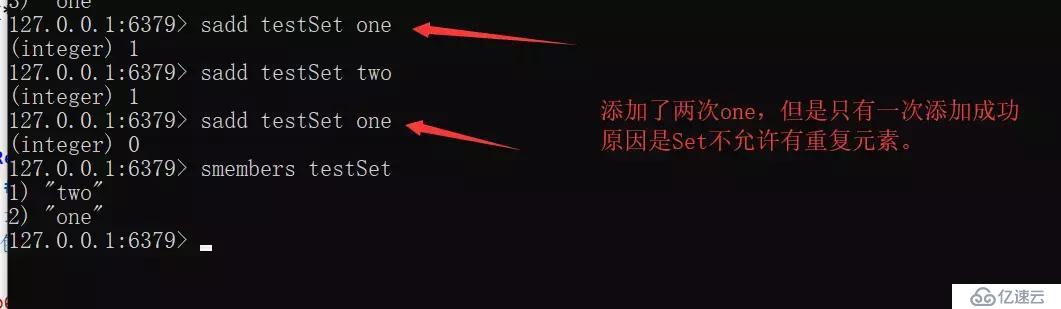
另外,當我們使用smembers遍歷set中的元素時,其順序也是不確定的,是通過hash運算過后的結果。Redis還對集合提供了求交集、并集、差集等操作,可以實現如同共同關注,共同好友等功能。
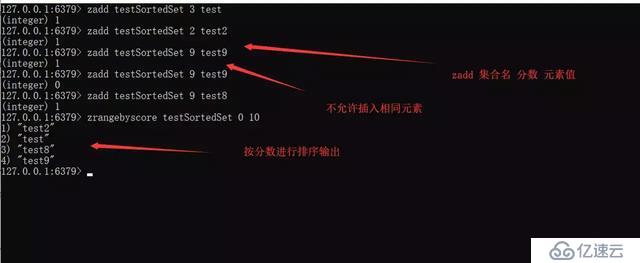
Sorted Set
通過分數來為集合中的成員進行從小到大的排序。
更高級的Redis類型
用于計數的HyperLogLog、用于支持存儲地理位置信息的Geo。
從海量Key里查詢出某一個固定前綴的Key
假設redis中有十億條key,如何從這么多key中找到固定前綴的key?
方法1:使用KEYS [pattern]:查找所有符合給定模式pattern的key
使用keys [pattern]指令可以找到所有符合pattern條件的key,但是keys會一次性返回所有符合條件的key,所以會造成redis的卡頓,假設redis此時正在生產環境下,使用該命令就會造成隱患,另外如果一次性返回所有key,對內存的消耗在某些條件下也是巨大的。 例:
keys test* //返回所有以test為前綴的key
方法2:使用SCAN cursor [MATCH pattern] [COUNT count]
cursor:游標 MATCH pattern:查詢key的條件 count:返回的條數 SCAN是一個基于游標的迭代器,需要基于上一次的游標延續之前的迭代過程。SCAN以0作為游標,開始一次新的迭代,直到命令返回游標0完成一次遍歷。此命令并不保證每次執行都返回某個給定數量的元素,甚至會返回0個元素,但只要游標不是0,程序都不會認為SCAN命令結束,但是返回的元素數量大概率符合count參數。另外,SCAN支持模糊查詢。 例:
SCAN 0 MATCH test* COUNT 10 //每次返回10條以test為前綴的key
如何通過Redis實現分布式鎖
分布式鎖
分布式鎖是控制分布式系統之間共同訪問共享資源的一種鎖的實現。如果一個系統,或者不同系統的不同主機之間共享某個資源時,往往需要互斥,來排除干擾,滿足數據一致性。
分布式鎖需要解決的問題如下:
1.互斥性:任意時刻只有一個客戶端獲取到鎖,不能有兩個客戶端同時獲取到鎖。
2.安全性:鎖只能被持有該鎖的客戶端刪除,不能由其它客戶端刪除。
3.死鎖:獲取鎖的客戶端因為某些原因而宕機繼而無法釋放鎖,其它客戶端再也無法獲取鎖而導致死鎖,此時需要有特殊機制來避免死鎖。
4.容錯:當各個節點,如某個redis節點宕機的時候,客戶端仍然能夠獲取鎖或釋放鎖。
如何使用redis實現分布式鎖
使用SETNX實現
SETNX key value:如果key不存在,則創建并賦值。該命令時間復雜度為O(1),如果設置成功,則返回1,否則返回0。

由于SETNX指令操作簡單,且是原子性的,所以初期的時候經常被人們作為分布式鎖,我們在應用的時候,可以在某個共享資源區之前先使用SETNX指令,查看是否設置成功,如果設置成功則說明前方沒有客戶端正在訪問該資源,如果設置失敗則說明有客戶端正在訪問該資源,那么當前客戶端就需要等待。但是如果真的這么做,就會存在一個問題,因為SETNX是長久存在的,所以假設一個客戶端正在訪問資源,并且上鎖,那么當這個客戶端結束訪問時,該鎖依舊存在,后來者也無法成功獲取鎖,這個該如何解決呢?
由于SETNX并不支持傳入EXPIRE參數,所以我們可以直接使用EXPIRE指令來對特定的key來設置過期時間。
用法:EXPIRE key seconds

程序:
RedisService?redisService?=?SpringUtils.getBean(RedisService.class);
long?status?=?redisService.setnx(key,"1");
if(status?==?1){
?redisService.expire(key,expire);
?doOcuppiedWork();
}這段程序存在的問題:假設程序運行到第二行出現異常,那么程序來不及設置過期時間就結束了,則key會一直存在,等同于鎖一直被持有無法釋放。出現此問題的根本原因為:原子性得不到滿足。
解決:從Redis2.6.12版本開始,我們就可以使用Set操作,將Setnx和expire融合在一起執行,具體做法如下。
SET?KEY?value?[EX?seconds]?[PX?milliseconds]?[NX|XX]
EX second:設置鍵的過期時間為second秒。
PX millisecond:設置鍵的過期時間為millisecond毫秒。
NX:只在鍵不存在時,才對鍵進行設置操作。
XX:只在鍵已經存在時,才對鍵進行設置操作。
注:SET操作成功完成時才會返回OK,否則返回nil。
有了SET我們就可以在程序中使用類似下面的代碼實現分布式鎖了:
RedisService?redisService?=?SpringUtils.getBean(RedisService.class);
String?result?=?redisService.set(lockKey,requestId,SET_IF_NOT_EXIST,SET_WITH_EXPIRE_TIME,expireTime);
if("OK.equals(result)"){
?doOcuppiredWork();
}如何實現異步隊列
使用Redis中的List作為隊列
使用上文所說的Redis的數據結構中的List作為隊列 Rpush生產消息,LPOP消費消息。
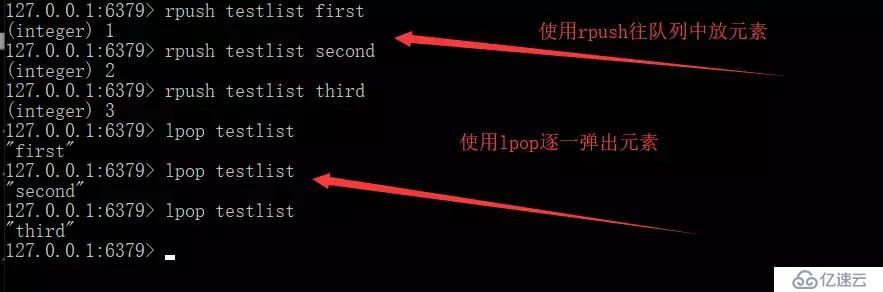
此時我們可以看到,該隊列是使用rpush生產隊列,使用lpop消費隊列。在這個生產者-消費者隊列里,當lpop沒有消息時,證明該隊列中沒有元素,并且生產者還沒有來得及生產新的數據。
缺點:lpop不會等待隊列中有值之后再消費,而是直接進行消費。
彌補:可以通過在應用層引入Sleep機制去調用LPOP重試。
使用BLPOP key [key...] timeout
BLPOP key [key ...] timeout:阻塞直到隊列有消息或者超時。
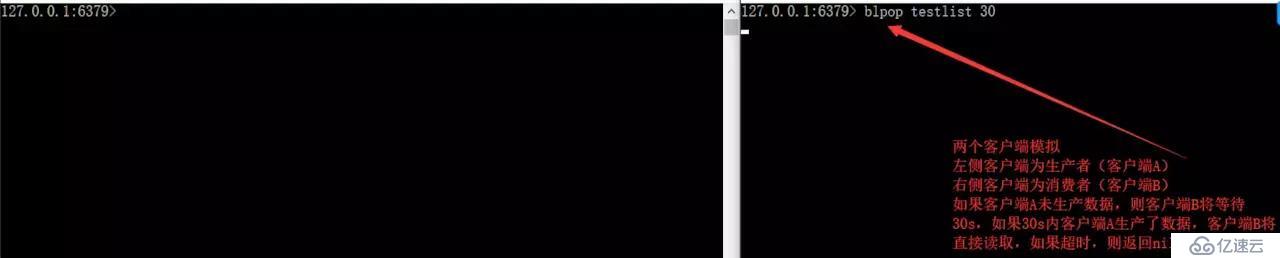
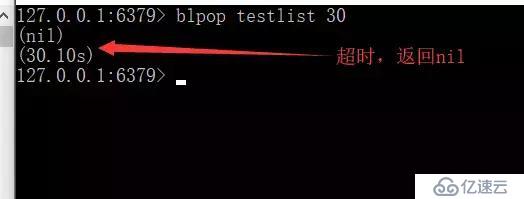

缺點:按照此種方法,我們生產后的數據只能提供給各個單一消費者消費能否實現生產一次就能讓多個消費者消費呢?
pub/sub:主題訂閱者模式
發送者(pub)發送消息,訂閱者(sub)接收消息。 訂閱者可以訂閱任意數量的頻道
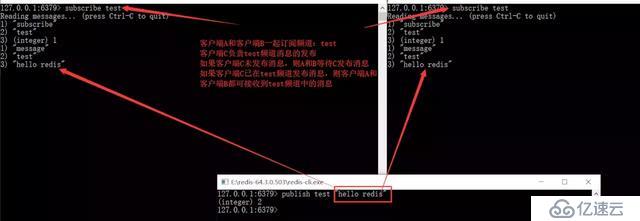
pub/sub模式的缺點:
消息的發布是無狀態的,無法保證可達。對于發布者來說,消息是“即發即失”的,此時如果某個消費者在生產者發布消息時下線,重新上線之后,是無法接收該消息的,要解決該問題需要使用專業的消息隊列,如kafka...此處不再贅述。
Redis持久化
什么是持久化
持久化,即將數據持久存儲,而不因斷電或其它各種復雜外部環境影響數據的完整性。由于Redis將數據存儲在內存而不是磁盤中,所以內存一旦斷電,Redis中存儲的數據也隨即消失,這往往是用戶不期望的,所以Redis有持久化機制來保證數據的安全性。
Redis如何做持久化
Redis目前有兩種持久化方式,即RDB和AOF,RDB是通過保存某個時間點的全量數據快照實現數據的持久化,當恢復數據時,直接通過rdb文件中的快照,將數據恢復。
RDB(快照)持久化:保存某個時間點的全量數據快照
RDB持久化會在某個特定的間隔保存那個時間點的全量數據的快照。 RDB配置文件: redis.conf:
?save?900?1?#在900s內如果有1條數據被寫入,則產生一次快照。 ?save?300?10?#在300s內如果有10條數據被寫入,則產生一次快照 ?save?60?10000?#在60s內如果有10000條數據被寫入,則產生一次快照 ?stop-writes-on-bgsave-error?yes? ?#stop-writes-on-bgsave-error?: ?如果為yes則表示,當備份進程出錯的時候, ?主進程就停止進行接受新的寫入操作,這樣是為了保護持久化的數據一致性的問題。
RDB的創建與載入
SAVE:阻塞Redis的服務器進程,直到RDB文件被創建完畢。SAVE命令很少被使用,因為其會阻塞主線程來保證快照的寫入,由于Redis是使用一個主線程來接收所有客戶端請求,這樣會阻塞所有客戶端請求。
BGSAVE:該指令會Fork出一個子進程來創建RDB文件,不阻塞服務器進程,子進程接收請求并創建RDB快照,父進程繼續接收客戶端的請求。子進程在完成文件的創建時會向父進程發送信號,父進程在接收客戶端請求的過程中,在一定的時間間隔通過輪詢來接收子進程的信號。我們也可以通過使用lastsave指令來查看bgsave是否執行成功,lastsave可以返回最后一次執行成功bgsave的時間。
自動化觸發RDB持久化的方式
1.根據redis.conf配置里的SAVE m n 定時觸發(實際上使用的是BGSAVE)
2.主從復制時,主節點自動觸發。
3.執行Debug Reload
4.執行Shutdown且沒有開啟AOF持久化。
BGSAVE的原理
啟動:
1.檢查是否存在子進程正在執行AOF或者RDB的持久化任務。如果有則返回false。
2.調用Redis源碼中的rdbSaveBackground方法,方法中執行fork()產生子進程執行rdb操作。
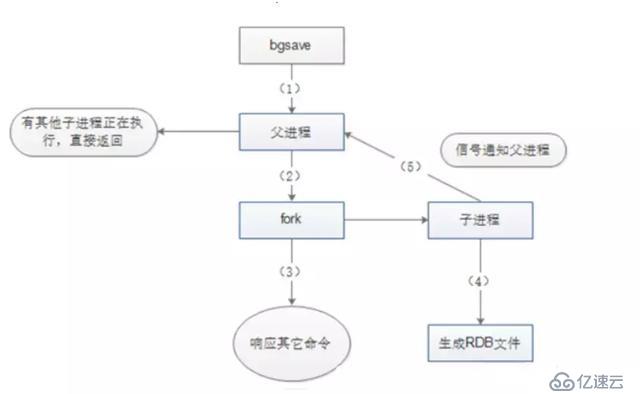
3.關于fork()中的Copy-On-Write
fork()在linux中創建子進程采用Copy-On-Write(寫時拷貝技術),即如果有多個調用者同時要求相同資源(如內存或磁盤上的數據存儲),他們會共同獲取相同的指針指向相同的資源,直到某個調用者試圖修改資源的內容時,系統才會真正復制一份專用副本給調用者,而其它調用者所見到的最初的資源仍然保持不變。
RDB持久化方式的缺點
1.內存數據全量同步,數據量大的狀況下,會由于I/O而嚴重影響性能。
2.可能會因為Redis宕機而丟失從當前至最近一次快照期間的數據。
AOF(Append-Only-File)持久化:保存寫狀態
AOF持久化是通過保存Redis的寫狀態來記錄數據庫的。相對RDB來說,RDB持久化是通過備份數據庫的狀態來記錄數據庫,而AOF持久化是備份數據庫接收到的指令。
1.AOF記錄除了查詢以外的所有變更數據庫狀態的指令。
2.以增量的形式追加保存到AOF文件中。
開啟AOF持久化
1.打開redis.conf配置文件,將appendonly屬性改為yes。
2.修改appendfsync屬性,該屬性可以接收三種參數,分別是always,everysec,no,always表示總是即時將緩沖區內容寫入AOF文件當中,everysec表示每隔一秒將緩沖區內容寫入AOF文件,no表示將寫入文件操作交由操作系統決定,一般來說,操作系統考慮效率問題,會等待緩沖區被填滿再將緩沖區數據寫入AOF文件中。
?appendonly?yes ?#appendsync?always ?appendfsync?everysec ?#?appendfsync?no
日志重寫解決AOF文件不斷增大的問題
隨著寫操作的不斷增加,AOF文件會越來越大。假設遞增一個計數器100次,如果使用RDB持久化方式,我們只要保存最終結果100即可,而AOF持久化方式需要記錄下這100次遞增操作的指令,而事實上要恢復這條記錄,只需要執行一條命令就行,所以那一百條命令實際可以精簡為一條。Redis支持這樣的功能,在不中斷前臺服務的情況下,可以重寫AOF文件,同樣使用到了COW(寫時拷貝)。重寫過程如下:
1.調用fork(),創建一個子進程。
2.子進程把新的AOF寫到一個臨時文件里,不依賴原來的AOF文件。
3.主進程持續將新的變動同時寫到內存和原來的AOF里。
4.主進程獲取子進程重寫AOF的完成信號,往新AOF同步增量變動。
5.使用新的AOF文件替換掉舊的AOF文件。
AOF和RDB的優缺點
RDB優點:全量數據快照,文件小,恢復快。
RDB缺點:無法保存最近一次快照之后的數據。
AOF優點:可讀性高,適合保存增量數據,數據不易丟失。
AOF缺點:文件體積大,恢復時間長。
RDB-AOF混合持久化方式
redis4.0之后推出了此種持久化方式,RDB作為全量備份,AOF作為增量備份,并且將此種方式作為默認方式使用。
在上述兩種方式中,RDB方式是將全量數據寫入RDB文件,這樣寫入的特點是文件小,恢復快,但無法保存最近一次快照之后的數據,AOF則將redis指令存入文件中,這樣又會造成文件體積大,恢復時間長等弱點。
在RDB-AOF方式下,持久化策略首先將緩存中數據以RDB方式全量寫入文件,再將寫入后新增的數據以AOF的方式追加在RDB數據的后面,在下一次做RDB持久化的時候將AOF的數據重新以RDB的形式寫入文件。這種方式既可以提高讀寫和恢復效率,也可以減少文件大小,同時可以保證數據的完整性。在此種策略的持久化過程中,子進程會通過管道從父進程讀取增量數據,在以RDB格式保存全量數據時,也會通過管道讀取數據,同時不會造成管道阻塞。可以說,在此種方式下的持久化文件,前半段是RDB格式的全量數據,后半段是AOF格式的增量數據。此種方式是目前較為推薦的一種持久化方式。
Redis數據的恢復
RDB和AOF文件共存情況下的恢復流程
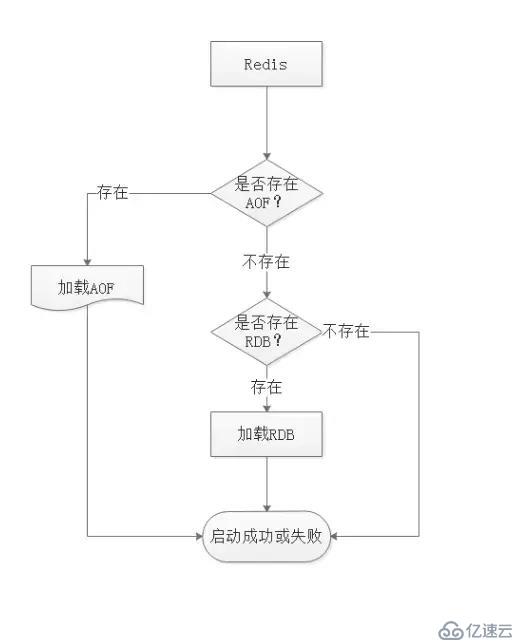
從圖可知,Redis啟動時會先檢查AOF是否存在,如果AOF存在則直接加載AOF,如果不存在AOF,則直接加載RDB文件。
Pineline
Pipeline和Linux的管道類似,它可以讓Redis批量執行指令。
Redis基于請求/響應模型,單個請求處理需要一一應答。如果需要同時執行大量命令,則每條命令都需要等待上一條命令執行完畢后才能繼續執行,這中間不僅僅多了RTT,還多次使用了系統IO。Pipeline由于可以批量執行指令,所以可以節省多次IO和請求響應往返的時間。但是如果指令之間存在依賴關系,則建議分批發送指令。
Redis的同步機制
主從同步原理
Redis一般是使用一個Master節點來進行寫操作,而若干個Slave節點進行讀操作,Master和Slave分別代表了一個個不同的RedisServer實例,另外定期的數據備份操作也是單獨選擇一個Slave去完成,這樣可以最大程度發揮Redis的性能,為的是保證數據的弱一致性和最終一致性。另外,Master和Slave的數據不是一定要即時同步的,但是在一段時間后Master和Slave的數據是趨于同步的,這就是最終一致性。
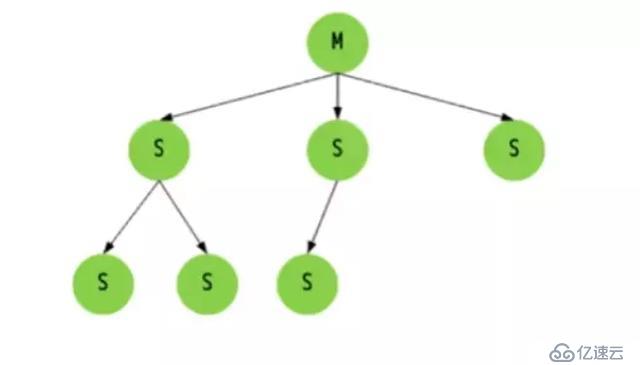
全同步過程
1.Slave發送sync命令到Master。
2.Master啟動一個后臺進程,將Redis中的數據快照保存到文件中。
3.Master將保存數據快照期間接收到的寫命令緩存起來。
4.Master完成寫文件操作后,將該文件發送給Slave。
5.使用新的AOF文件替換掉舊的AOF文件。
6.Master將這期間收集的增量寫命令發送給Slave端。
增量同步過程
1.Master接收到用戶的操作指令,判斷是否需要傳播到Slave。
2.將操作記錄追加到AOF文件。
3.將操作傳播到其它Slave:1.對齊主從庫;2.往響應緩存寫入指令。
4.將緩存中的數據發送給Slave。
Redis Sentinel(哨兵)
主從模式弊端:當Master宕機后,Redis集群將不能對外提供寫入操作。Redis Sentinel可解決這一問題。
解決主從同步Master宕機后的主從切換問題:
1.監控:檢查主從服務器是否運行正常。
2.提醒:通過API向管理員或者其它應用程序發送故障通知。
3.自動故障遷移:主從切換(在Master宕機后,將其中一個Slave轉為Master,其他的
Slave從該節點同步數據)。
Redis集群
原理:如何從海量數據里快速找到所需?
分片
按照某種規則去劃分數據,分散存儲在多個節點上。通過將數據分到多個Redis服務器上,來減輕單個Redis服務器的壓力。
一致性Hash算法
既然要將數據進行分片,那么通常的做法就是獲取節點的Hash值,然后根據節點數求模,但這樣的方法有明顯的弊端,當Redis節點數需要動態增加或減少的時候,會造成大量的Key無法被命中。所以Redis中引入了一致性Hash算法。該算法對2^32 取模,將Hash值空間組成虛擬的圓環,整個圓環按順時針方向組織,每個節點依次為0、1、2...2^32-1,之后將每個服務器進行Hash運算,確定服務器在這個Hash環上的地址,確定了服務器地址后,對數據使用同樣的Hash算法,將數據定位到特定的Redis服務器上。如果定位到的地方沒有Redis服務器實例,則繼續順時針尋找,找到的第一臺服務器即該數據最終的服務器位置。
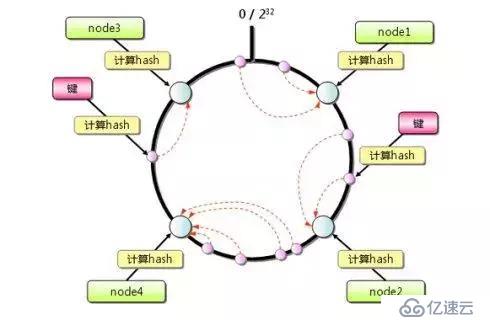
Hash環的數據傾斜問題
Hash環在服務器節點很少的時候,容易遇到服務器節點不均勻的問題,這會造成數據傾斜,數據傾斜指的是被緩存的對象大部分集中在Redis集群的其中一臺或幾臺服務器上。
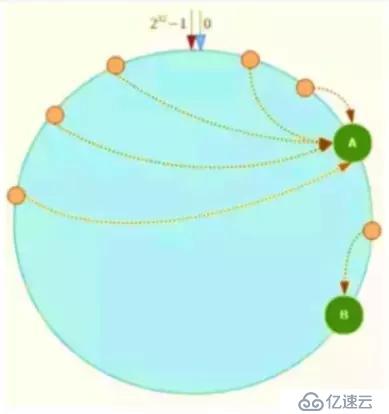
如上圖,一致性Hash算法運算后的數據大部分被存放在A節點上,而B節點只存放了少量的數據,久而久之A節點將被撐爆。
針對這一問題,可以引入虛擬節點解決。簡單地說,就是為每一個服務器節點計算多個Hash,每個計算結果位置都放置一個此服務器節點,稱為虛擬節點,可以在服務器IP或者主機名后放置一個編號實現。
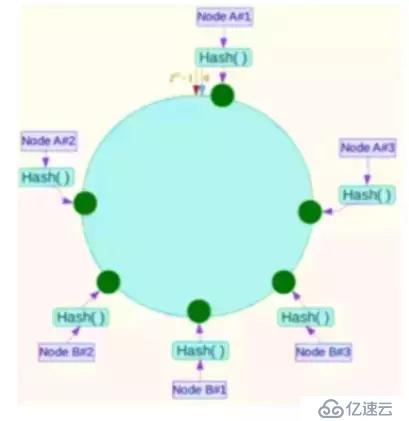
例如上圖:將NodeA和NodeB兩個節點分為Node A#1-A#3 NodeB#1-B#3。
結語
這篇準(tou)備(lan)了相當久的時間,因為有些東西總感覺自己拿不準不敢往上寫,差點自閉,就算現在發出來了也感覺有很多地方是需要改動的。如果有同學覺得哪里寫的不對勁的,評論區或者私聊我...嗯,我不要你覺得,我要我覺得。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





