溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了TDengine+Grafana如何實現數據可視化,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
在搞懂了基本的功能后,便上線了TDengine版的監控系統,但是發現,在grafana中居然不能“group by”,只能通過寫where多條語句將多個短信狀態數據放到一個儀表盤里,如圖:
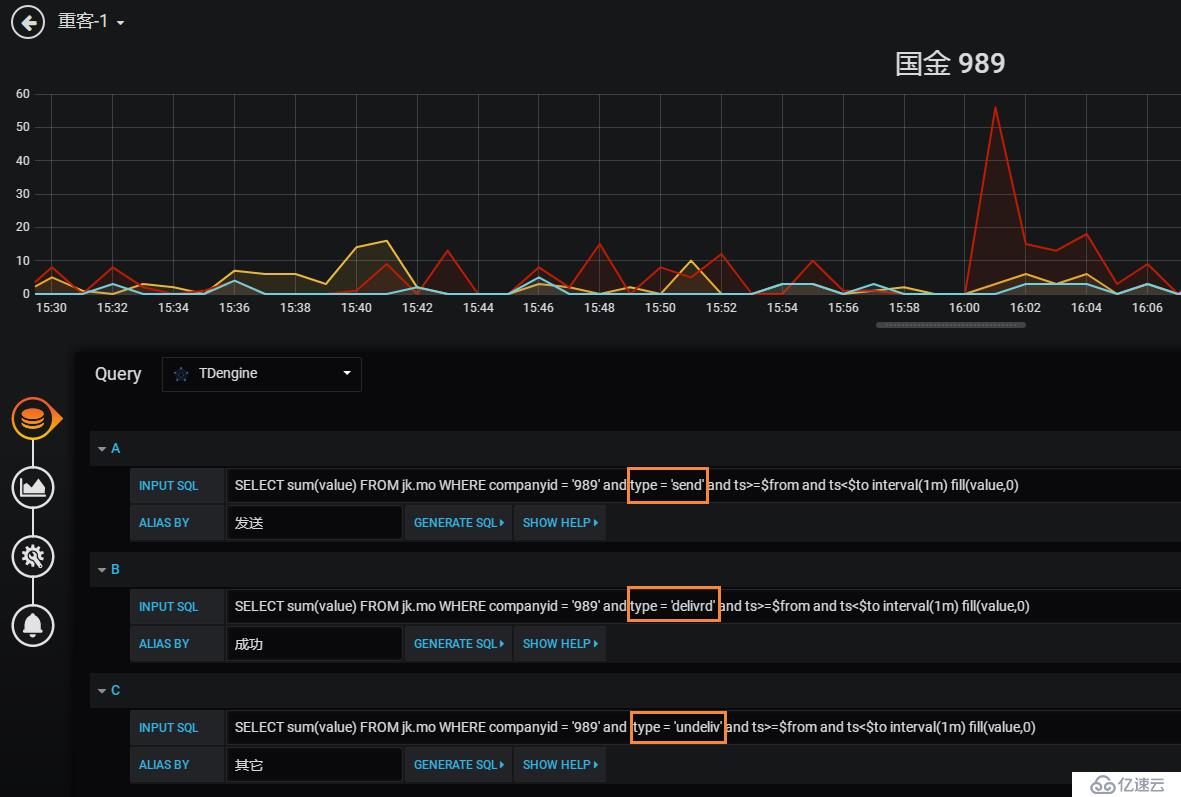
如果where條件有更多,這樣的方法就太笨,并且靈活性太差。
于是,開始仔細研究官方文檔,搞懂了“超級表”、“連續查詢“等,在這個過程中遇到過不少問題,在這里做一下記錄(測試環境,數據是模擬產生的)。
一、安裝和運行
測試環境
cat /etc/redhat-release CentOS Linux release 7.7.1908 (Core)
安裝很簡單:
rpm -ivh tdengine-1.6.3.1-3.x86_64.rpm
配置都用默認的(未改配置文件)
啟動TDengine:
systemctl start taosd
二、建庫、建表
在命令行輸入“taos”
taos>
以下建庫、建表操作都在此提示符下進行
創建數據庫
create database jk keep 365 precision 'us';
說明:
keep 365表示該庫保存365天內的數據,365天之前的數據會被自動清除(因為是時序數據庫,所以不能對庫中的表進行delete操作);
precision ‘us’表示數據庫中的時間戳精度為“微秒”,(默認是毫秒,也可以顯示寫為precision ‘ms’), 經測試,此處用單引號和雙引號都是可以的,但是不能沒有引號。
配置文件中已經不支持時間精度的配置,必須在建庫的時候指定(測試了很多配置都不生效,Issues后得到的官方回復)
TDengine的設計初衷是用于物聯網,設備的信息采集精度到“毫秒”已經足夠用,但我司的短信平臺會有突發大量數據產生,為了避免可能會導致的數據丟失,將精度設置為“微秒”,經測試,效果很好,測試的模擬數據插入時間戳都用“now”獲取,下圖左側為“毫秒”精度,能看到有“0 row(s)”的情況出現,表示有數據未插入, 右側為“微秒”精度,未見未插入數據。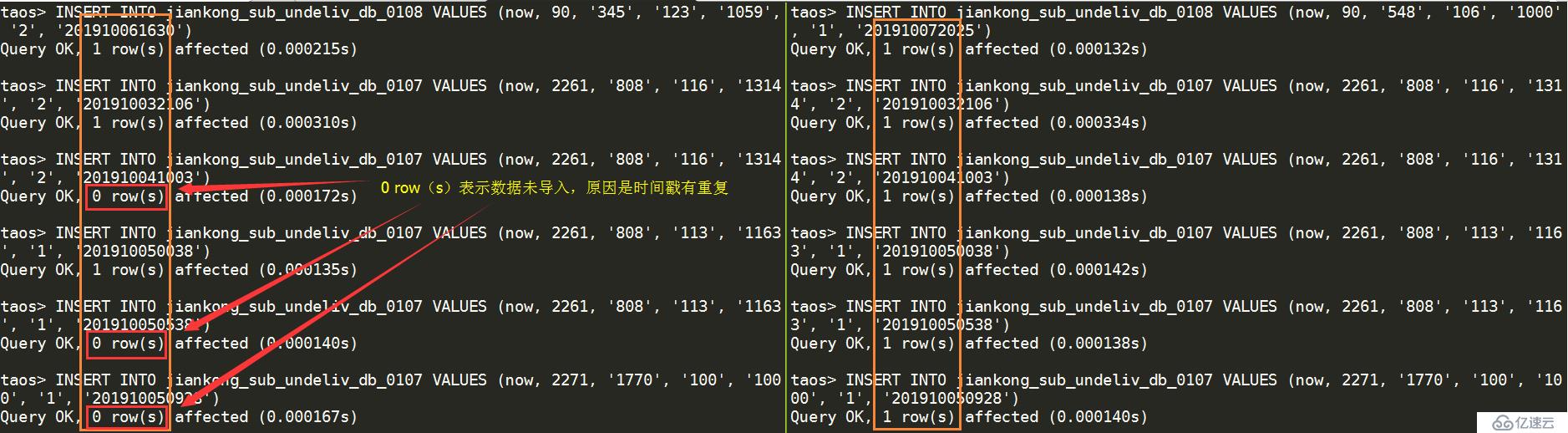
2. 創建超級表
進入數據庫“jk”
taos> use jk; Database changed.
create table jiankong (ts timestamp, gatewayid binary(6), companyid binary(20), provinceid binary(10), cityid binary(10), value int, timestr binary(30)) tags(type binary(10), subtype binary(10));
短信系統中有3種type,幾百種subtype,所以將這些靜態信息(或者簡單地理解為需要將進行group by的字段設置為tag)
解釋一下超級表:
STable是同一類型數據采集點的抽象,是同類型采集實例的集合,包含多張數據結構一樣的子表。
每個STable為其子表定義了表結構和一組標簽:表結構即表中記錄的數據列及其數據類型;標簽名和數據類型由STable定義,標簽值記錄著每個子表的靜態信息,用以對子表進行分組過濾。
子表本質上就是普通的表,由一個時間戳主鍵和若干個數據列組成,每行記錄著具體的數據,數據查詢操作與普通表完全相同;但子表與普通表的區別在于每個子表從屬于一張超級表,并帶有一組由STable定義的標簽值。
針對所有的通過STable創建的子表進行多表聚合查詢,支持按照全部的TAG值進行條件過濾(where),并可將結果按照TAGS中的值進行聚合(group by),暫不支持針對binary類型的模糊匹配過濾。
標簽數據(或者叫標簽值)直接關聯到每個子表,相同的標簽值(一個或者多個,最多6個)定位到一個子表(用“寫數據時自動建表”的方式,可以將“相同的標簽值”對應到多個子表)。
tag值支持中文,需要將tag類型設置為NCHAR(在其他測試中已經驗證過)。
3. 創建子表(子表就是普通表,表結構完全由超級表定義):
create table jiankong_sub_send using jiankong tags ('send', 'send');
create table jiankong_sub_delivrd using jiankong tags ('delivrd', 'delivrd');
create table jiankong_sub_undeliv_db_0108 using jiankong tags ('undeliv', 'DB:0108');
create table jiankong_sub_undeliv_db_0107 using jiankong tags ('undeliv', 'DB:0107');
create table jiankong_sub_undeliv_balance using jiankong tags ('undeliv', 'BALANCE');
create table jiankong_sub_undeliv_id_0076 using jiankong tags ('undeliv', 'ID:0076');
create table jiankong_sub_undeliv_ib_0008 using jiankong tags ('undeliv', 'IB:0008');相同類型的type和subtype的組合創建為一個子表(只是進行測試,所以并沒有將所有的幾百個subtype都進行建表)
4. 插入數據
INSERT INTO jiankong_sub_send VALUES (now, 3034, '1564', '109', '1272', '2', '201909231530') INSERT INTO jiankong_sub_delivrd VALUES (now, 3034, '1564', '109', '1272', '2', '201909231530') INSERT INTO jiankong_sub_undeliv_balance VALUES (now, 1179, '152', '106', '1000', '1', '201910071113') INSERT INTO jiankong_sub_undeliv_id_0076 VALUES (now, 1165, '1785', '111', '1226', '1', '201910071415') INSERT INTO jiankong_sub_undeliv_ib_0008 VALUES (now, 1165, '1785', '127', '1000', '2', '201910061727') INSERT INTO jiankong_sub_undeliv_db_0108 VALUES (now, 90, '548', '123', '1237', '1', '201910061127') INSERT INTO jiankong_sub_undeliv_db_0107 VALUES (now, 2261, '808', '116', '1314', '2', '201910032106')
以上是對上述創建的7個子表分別插入模擬數據,由于模擬大量數據,所以需要寫shell腳本(也可以用其他方式)進行數據灌入。
寫入數據時不能直接對STable操作,而是要對每張子表進行操作。
5. 數據庫、表結構等查詢
查詢數據庫信息:
taos> show databases; name | created time | ntables | vgroups |replica| days | keep1,keep2,keep(D) | tables | rows | cache(b) | ablocks |tblocks| ctime(s) | clog | comp |time precision| status | ============================================================================================================================================================================================================================================== log | 19-11-18 16:37:14.025| 4| 1| 1| 10|30,30,30 | 32| 1024| 2048| 2.00000| 32| 3600| 1| 2|us |ready | jk | 19-11-18 16:48:19.867| 10| 1| 1| 10|365,365,365 | 1024| 4096| 16384| 4.00000| 100| 3600| 1| 2|us |ready | Query OK, 1 row(s) in set (0.002487s)
查詢超級表:
taos> show stables; name | created_time |columns| tags | tables | ==================================================================================================================== jiankong | 19-11-18 16:48:41.540| 7| 2| 7| Query OK, 1 row(s) in set (0.002140s)
查詢超級表的表結構:
taos> describe jiankong; Field | Type | Length | Note | ======================================================================================================= ts |TIMESTAMP | 8| | gatewayid |BINARY | 6| | companyid |BINARY | 20| | provinceid |BINARY | 10| | cityid |BINARY | 10| | value |INT | 4| | timestr |BINARY | 30| | type |BINARY | 10|tag | subtype |BINARY | 10|tag | Query OK, 9 row(s) in set (0.001301s)
可以在Note列看到“tag”,表示是此列是標簽
查詢子表:
taos> show tables; table_name | created_time |columns| stable | ================================================================================================================================================================= jiankong_sub_delivrd | 19-11-18 16:49:17.009| 7|jiankong | jiankong_sub_undeliv_ib_0008 | 19-11-18 16:49:17.025| 7|jiankong | jiankong_sub_undeliv_db_0108 | 19-11-18 16:49:17.016| 7|jiankong | jiankong_sub_undeliv_db_0107 | 19-11-18 16:49:17.018| 7|jiankong | jiankong_sub_undeliv_id_0076 | 19-11-18 16:49:17.023| 7|jiankong | jiankong_sub_send | 19-11-18 16:49:17.003| 7|jiankong | jiankong_sub_undeliv_balance | 19-11-18 16:49:17.021| 7|jiankong | Query OK, 10 row(s) in set (0.007001s)
查詢具體的子表的表結構:
taos> describe jiankong_sub_undeliv_db_0108; Field | Type | Length | Note | ========================================================================================================= ts |TIMESTAMP | 8| | gatewayid |BINARY | 6| | companyid |BINARY | 20| | provinceid |BINARY | 10| | cityid |BINARY | 10| | value |INT | 4| | timestr |BINARY | 30| | type |BINARY | 10|undeliv | subtype |BINARY | 10|DB:0108 | Query OK, 9 row(s) in set (0.001195s)
可以在Note列看到“undeliv”(超級表中的type字段)和“DB:0108"(超級表中的subtype字段),這2個靜態標簽值確定了這個子表
6. 數據查詢
對type進行分組聚合查詢:
taos> select sum(value) from jk.jiankong group by type; sum(value) | type | ================================= 11827688|delivrd | 55566578|send | 46687487|undeliv | Query OK, 3 row(s) in set (0.018251s)
對subtype進行分組聚合查詢:
taos> taos> select sum(value) from jk.jiankong group by subtype; sum(value) | subtype | ================================= 9317|BALANCE | 65219|DB:0107 | 2077691|DB:0108 | 2804417|IB:0008 | 41730843|ID:0076 | 11827688|delivrd | 55566578|send | Query OK, 7 row(s) in set (0.013978s)
對type和subtype進行分組聚合查詢:
taos> select sum(value) from jk.jiankong group by type, subtype; sum(value) | type | subtype | ============================================ 11827688|delivrd |delivrd | 55566578|send |send | 9317|undeliv |BALANCE | 65219|undeliv |DB:0107 | 2077691|undeliv |DB:0108 | 2804417|undeliv |IB:0008 | 41730843|undeliv |ID:0076 | Query OK, 7 row(s) in set (0.732830s)
按天對type和subtype進行分組聚合查詢:
taos> select sum(value) from jk.jiankong interval(1d) group by type, subtype; ts | sum(value) | type | subtype | ====================================================================== 19-11-18 00:00:00.000000| 1760800|delivrd |delivrd | 19-11-19 00:00:00.000000| 14768|delivrd |delivrd | 19-11-20 00:00:00.000000| 3290720|delivrd |delivrd | 19-11-21 00:00:00.000000| 4973640|delivrd |delivrd | 19-11-22 00:00:00.000000| 1787760|delivrd |delivrd | 19-11-18 00:00:00.000000| 36976790|send |send | 19-11-19 00:00:00.000000| 310128|send |send | 19-11-20 00:00:00.000000| 9482760|send |send | 19-11-21 00:00:00.000000| 6470940|send |send | 19-11-22 00:00:00.000000| 2325960|send |send | 19-11-18 00:00:00.000000| 6200|undeliv |BALANCE | 19-11-19 00:00:00.000000| 52|undeliv |BALANCE | 19-11-20 00:00:00.000000| 1590|undeliv |BALANCE | 19-11-21 00:00:00.000000| 1085|undeliv |BALANCE | 19-11-22 00:00:00.000000| 390|undeliv |BALANCE | 19-11-18 00:00:00.000000| 43400|undeliv |DB:0107 | 19-11-19 00:00:00.000000| 364|undeliv |DB:0107 | 19-11-20 00:00:00.000000| 11130|undeliv |DB:0107 | 19-11-21 00:00:00.000000| 7595|undeliv |DB:0107 | 19-11-22 00:00:00.000000| 2730|undeliv |DB:0107 | 19-11-18 00:00:00.000000| 1382600|undeliv |DB:0108 | 19-11-19 00:00:00.000000| 11596|undeliv |DB:0108 | 19-11-20 00:00:00.000000| 354570|undeliv |DB:0108 | 19-11-21 00:00:00.000000| 241955|undeliv |DB:0108 | 19-11-22 00:00:00.000000| 86970|undeliv |DB:0108 | 19-11-18 00:00:00.000000| 1866200|undeliv |IB:0008 | 19-11-19 00:00:00.000000| 15652|undeliv |IB:0008 | 19-11-20 00:00:00.000000| 478590|undeliv |IB:0008 | 19-11-21 00:00:00.000000| 326585|undeliv |IB:0008 | 19-11-22 00:00:00.000000| 117390|undeliv |IB:0008 | 19-11-18 00:00:00.000000| 27769800|undeliv |ID:0076 | 19-11-19 00:00:00.000000| 232908|undeliv |ID:0076 | 19-11-20 00:00:00.000000| 7121610|undeliv |ID:0076 | 19-11-21 00:00:00.000000| 4859715|undeliv |ID:0076 | 19-11-22 00:00:00.000000| 1746810|undeliv |ID:0076 | Query OK, 35 row(s) in set (0.023865s)
此處interval是聚合時間段的長度, 最短時間間隔10毫秒(10a)
未建超級表時,對普通表進行分組聚合查詢,會報錯:
taos> select sum(value) from jk.jiankong group by type; TSDB error: invalid SQL: group by only available for STable query
7. 寫數據時自動建子表
我們有另外一個需求,由于要監控的靜態數據多達幾百個,而且具有不確定性,所以無法全部在建庫、建表的時候創建所有子表,這個功能完全解決了我們的這個問題。
以下是官網的文檔摘錄:
在某些特殊場景中,用戶在寫數據時并不確定某個設備的表是否存在,此時可使用自動建表語法來實現寫入數據時用超級表定義的表結構自動創建不存在的子表,若該表已存在則不會建立新表。
注意:自動建表語句只能自動建立子表而不能建立超級表,這就要求超級表已經被事先定義好。自動建表語法跟insert/import語法非常相似,唯一區別是語句中增加了超級表和標簽信息。具體語法如下:
INSERT INTO <tb_name> USING <stb_name> TAGS (<tag1_value>, ...) VALUES (field_value, ...) (field_value, ...) ...;
對比,用create創建子表:
create table jiankong_sub_send using jiankong tags ('send', 'send');
三、安裝和配置garafana
安裝
在官網https://grafana.com/grafana/download下載grafana的rpm安裝包后,進行安裝:
rpm -ivh grafana-6.4.4-1.x86_64.rpm
2. copy TDengine的Grafana插件到Grafana的插件目錄
TDengine的Grafana插件在安裝包的/usr/local/taos/connector/grafana目錄下
cp -r /usr/local/taos/connector/grafana/tdengine/ /var/lib/grafana/plugins
3. 啟動Grafana
systemctl start grafana-server
4. 在瀏覽器中通過host:3000登錄Grafana服務器
默認用戶名和密碼都是admin

5. 添加TDengine數據源
在最下方找到“TDengine”
Name:“TDengine”(可以是其他名字)
Host:測試服務器地址“http://192.168.8.66:6020”
User: 默認為“root”
Password:默認為“taosdata”
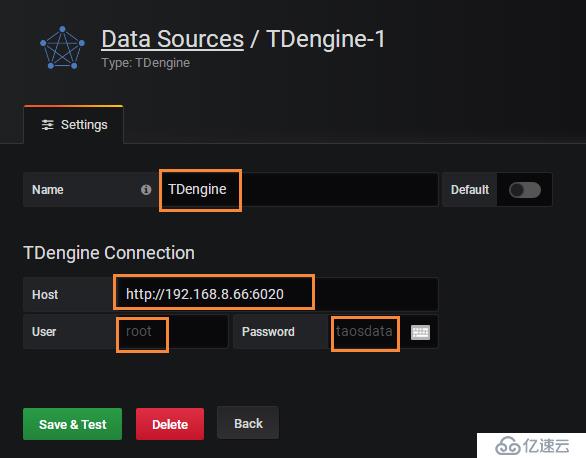
測試一下:

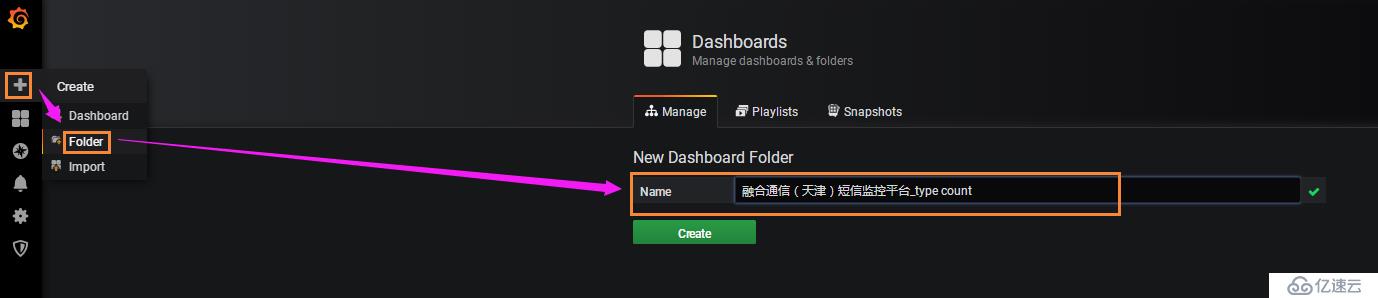
6. 添加Folder
將相同類型需要監控的儀表盤(dashboard)放到一個Folder中
7. 添加Dashboard
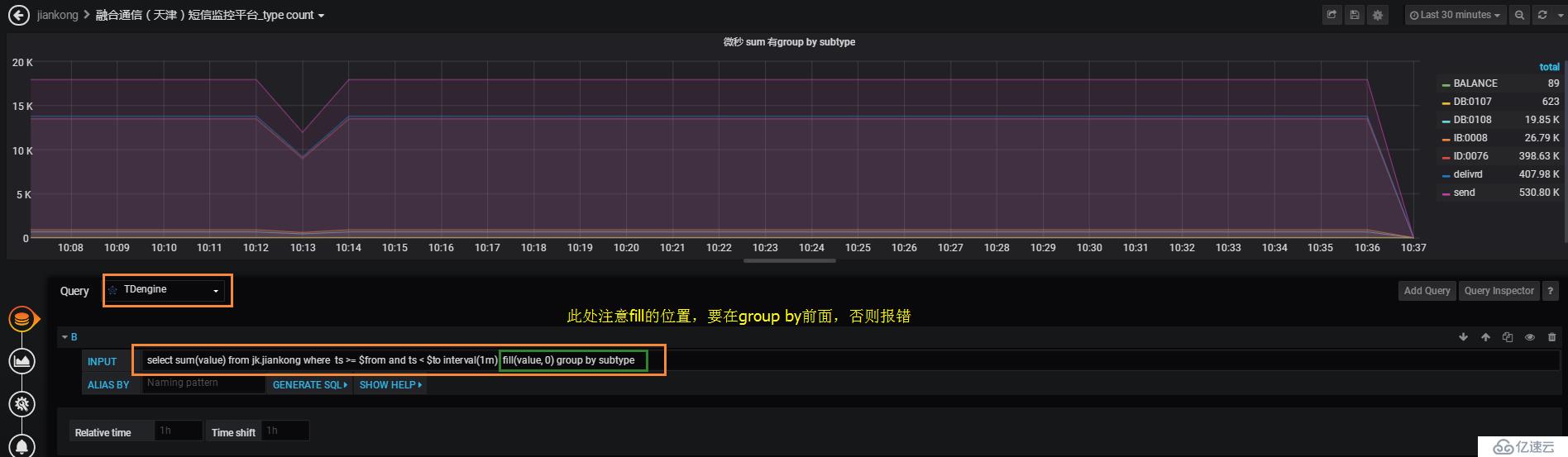
進入剛才創建的Folder后,創建Dashboard
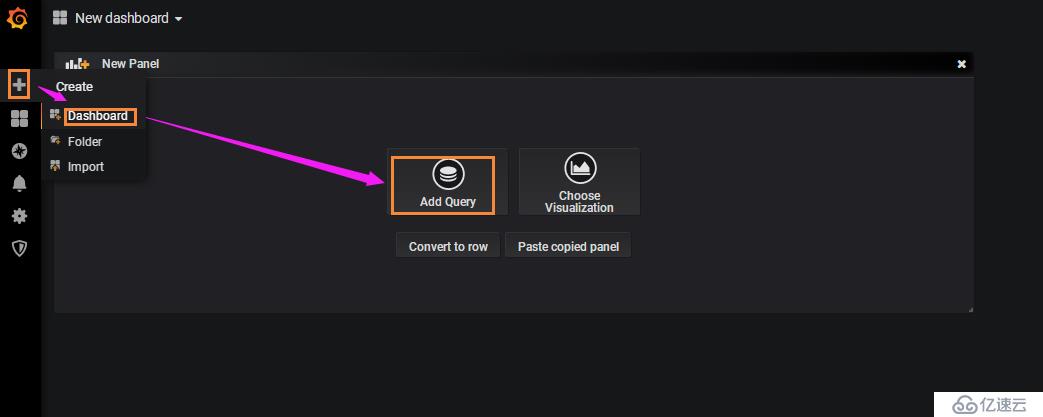
INPUT處的sql語句,要注意fill的位置,需要在group by前面,否則報錯
配置圖形顯示
可以根據需求進行曲線圖,表格,儀表盤等的選擇
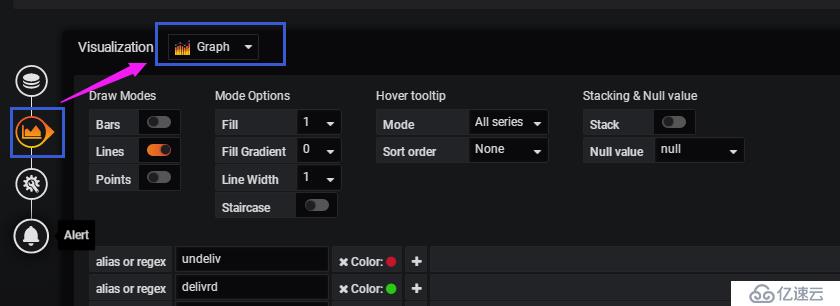

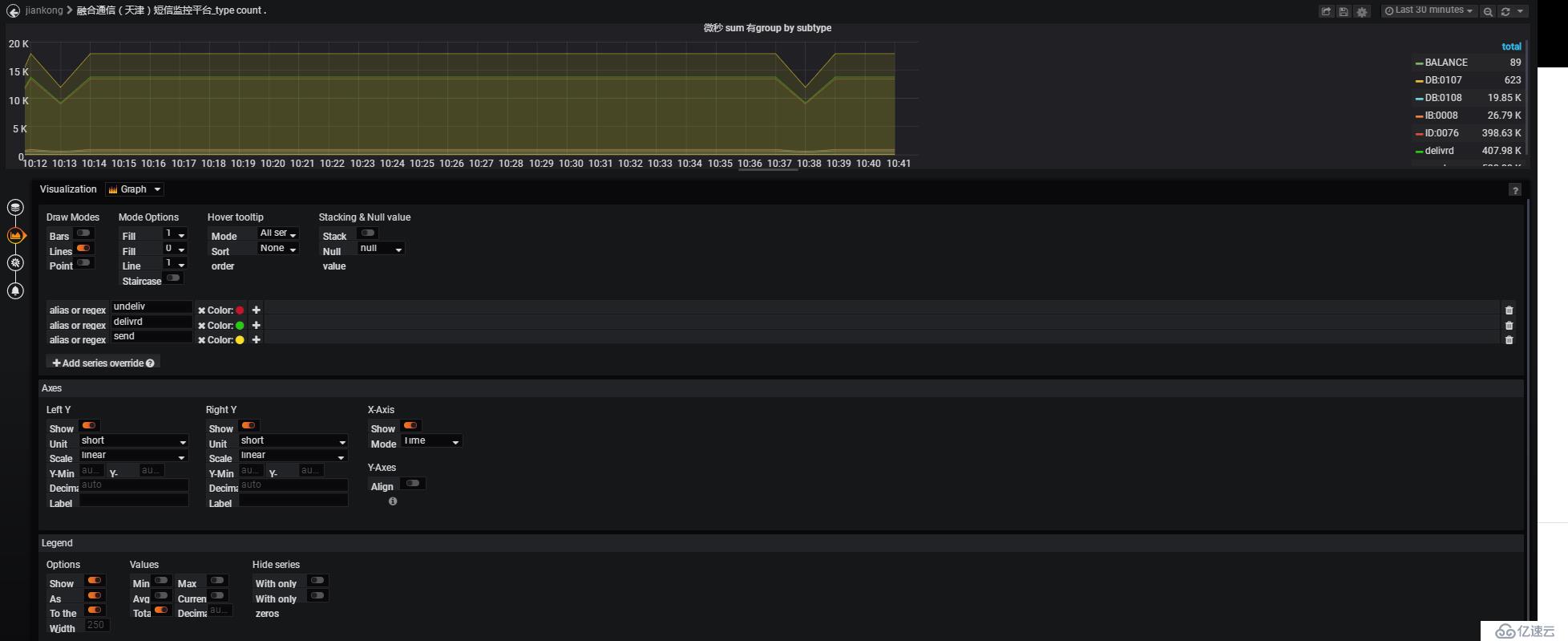
在這里配置“曲線圖”,圖示下方是具體的圖形顯示細則,如:標線、是否填充,對顯示的字段進行曲線顏色的自定義等
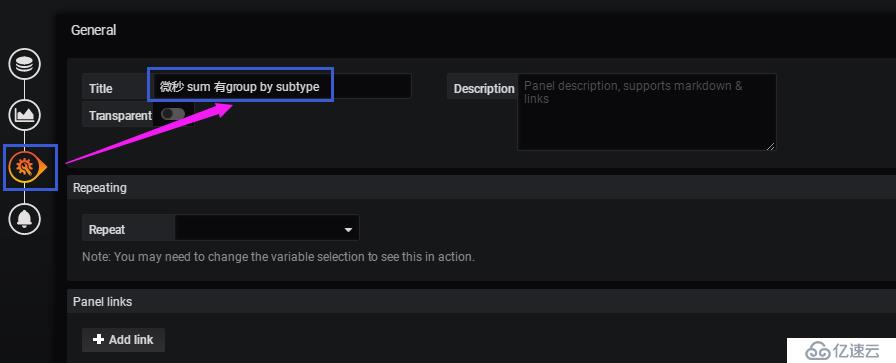
給此儀表盤起個一看就懂的名字:
8. 配置了6個儀表盤
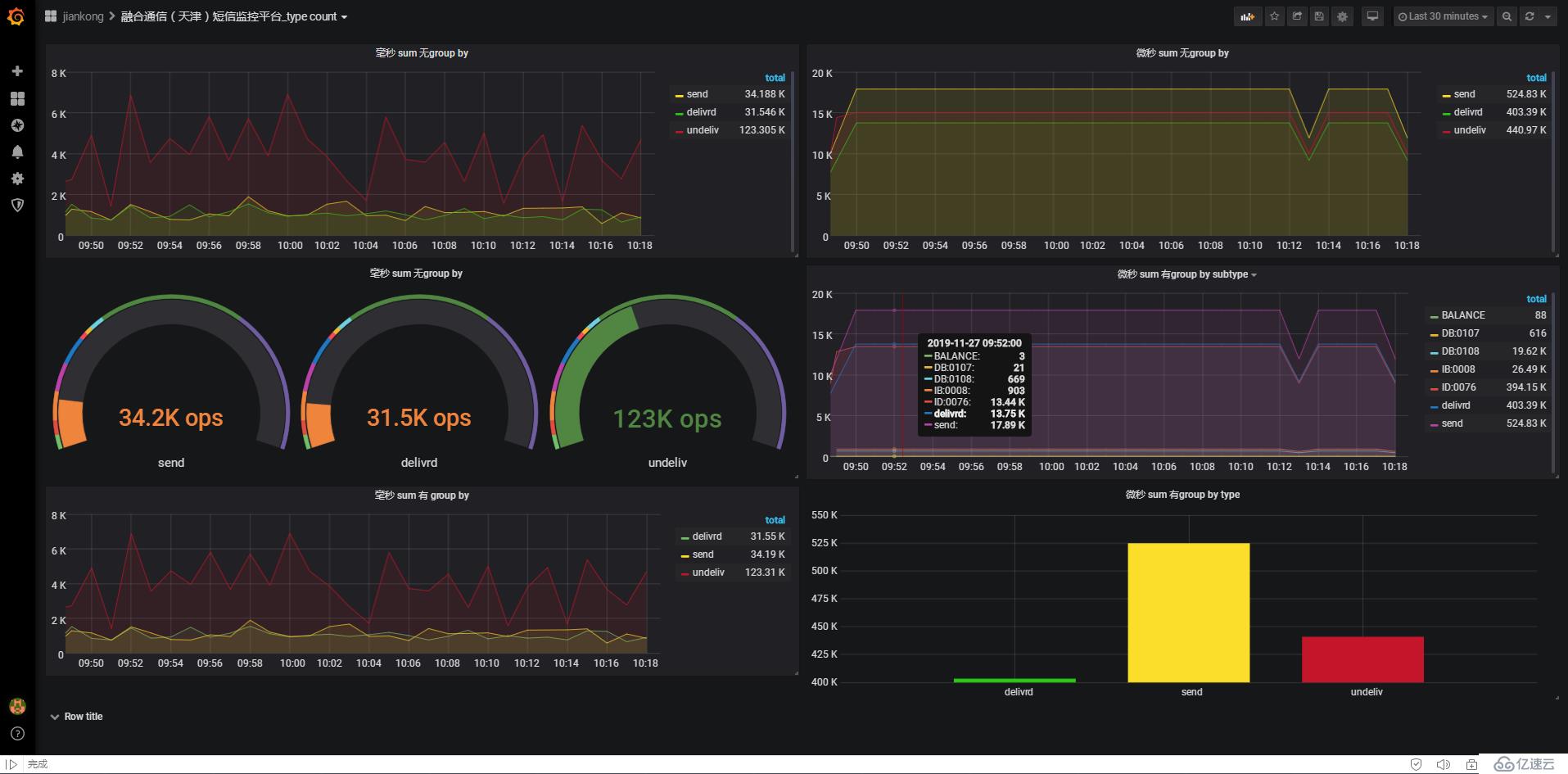
9. 無group by和有group by的實例
無group by,需要寫多條sql,通過where條件去區分,如果分類多就很麻煩且不靈活
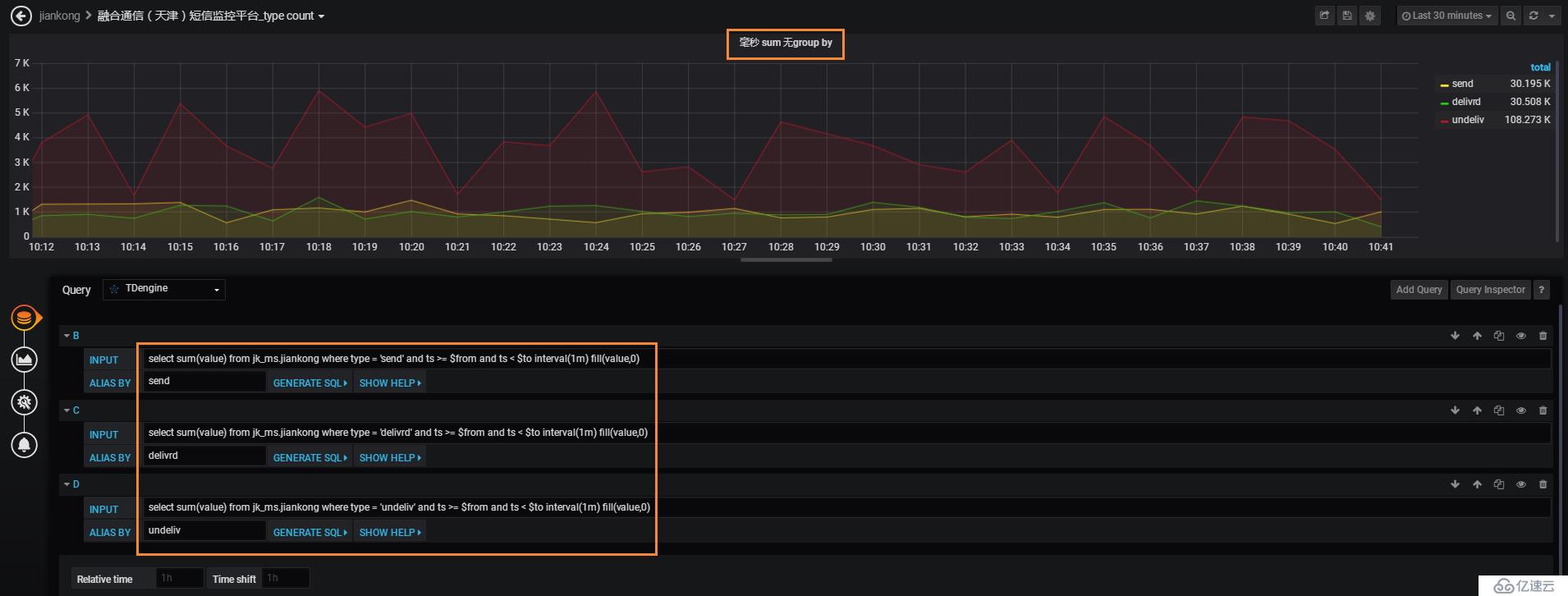
有group by,一條sql就解決問題了:
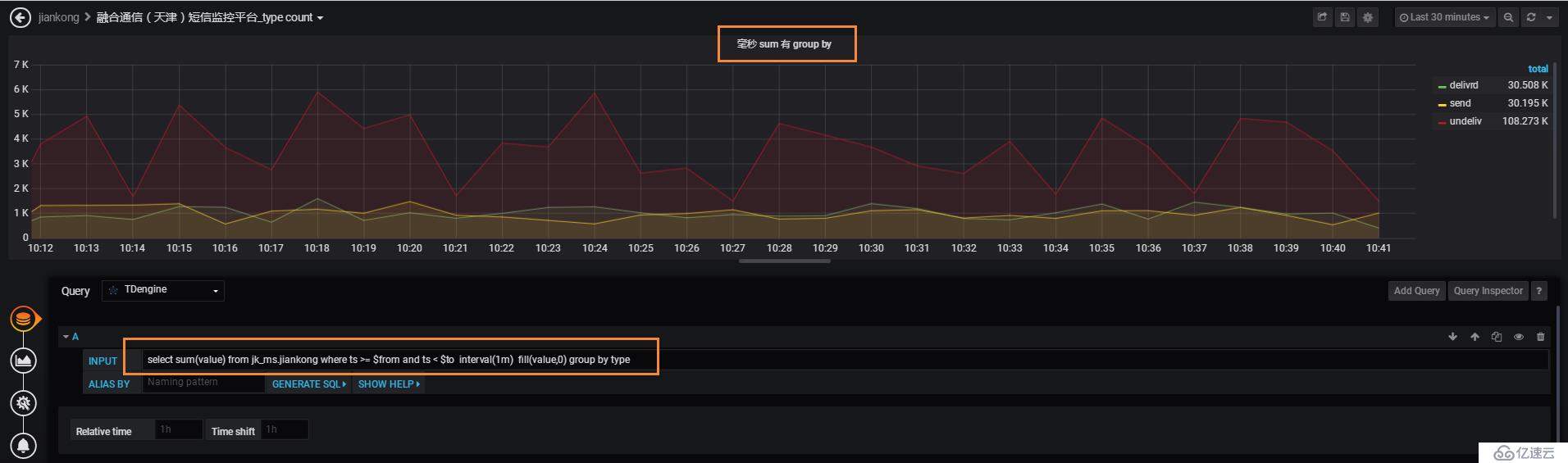
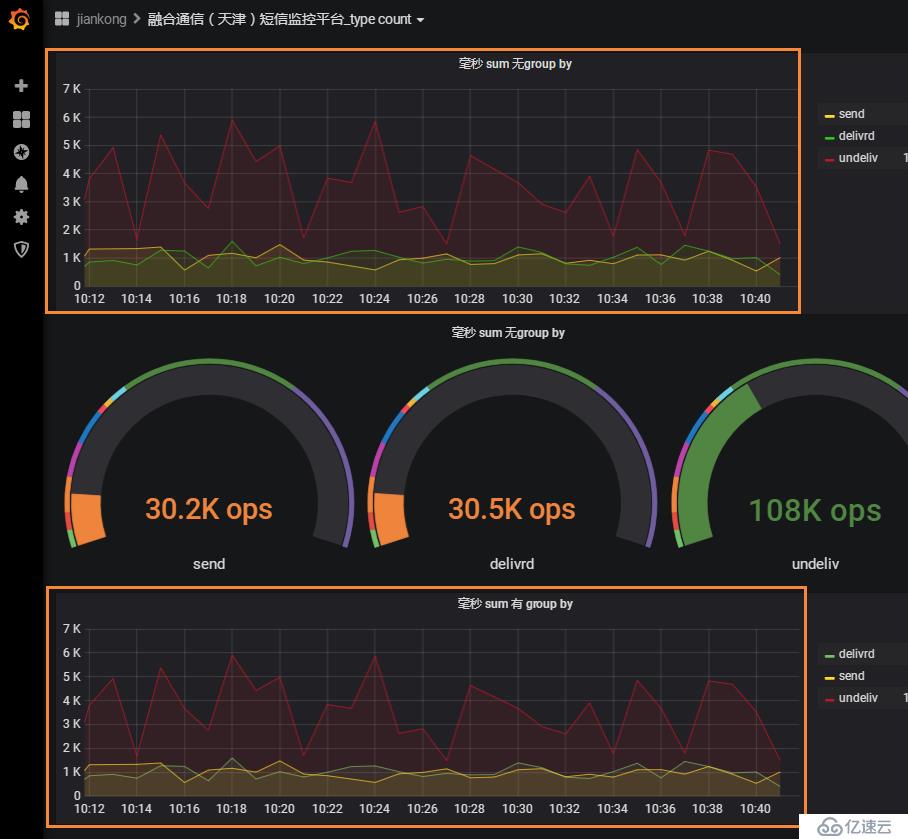
下圖是有無group by的曲線趨勢對比,可以看到是一模一樣的
四、高級功能初探和一些聯想
1. 連續查詢(Continuous Query)----用戶級別的預計算
TDengine的“預計算”的概念我覺得非常的棒,官網文檔摘錄如下:
為有效地提升查詢處理的性能,針對物聯網數據的不可更改的特點,TDengine采用在每個保存的數據塊上,都記錄下該數據塊中數據的最大值、最小值、和等統計數據。如果查詢處理涉及整個數據塊的全部數據,則直接使用預計算結果,不再讀取數據塊的內容。由于預計算模塊的大小遠小于磁盤上存儲的具體數據的大小,對于磁盤IO為瓶頸的查詢處理,使用預計算結果可以極大地減小讀取IO,并加速查詢處理的流程。
連續查詢的官網文檔摘錄如下:
基于滑動窗口的流式計算(Stream)
連續查詢是TDengine定期自動執行的查詢,采用滑動窗口的方式進行計算,是一種簡化的時間驅動的流式計算。針對庫中的表或超級表,TDengine可提供定期自動執行的連續查詢,用戶可讓TDengine推送查詢的結果,也可以將結果再寫回到TDengine中。每次執行的查詢是一個時間窗口,時間窗口隨著時間流動向前滑動。在定義連續查詢的時候需要指定時間窗口(time window, 參數interval )大小和每次前向增量時間(forward sliding times, 參數sliding)。
其中,將結果再寫回到TDengine中的方式其實就是一種用戶級別的預計算,這樣由TDengine按照用戶定義的時間窗口和時間增量進行后臺的計算,在用戶查詢數據的時候,直接從回寫的表中讀取數據,速度就會非常快。
創建連續查詢:
taos> create table test_stream_sum as select sum(value) from jiankong interval(20s) sliding(10s) group by type, subtype; Query OK, 1 row(s) affected (0.000983s)
上述連續查詢,sql的select部分實際的輸出結果為:
taos> select sum(value) from jiankong interval(20s) group by type, subtype; ts | sum(value) | type | subtype | ====================================================================== 19-11-18 16:50:40.000000| 9088|delivrd |delivrd | 19-11-18 16:51:00.000000| 31808|delivrd |delivrd | 19-11-18 16:51:20.000000| 15904|delivrd |delivrd | 19-11-18 16:52:20.000000| 12212|delivrd |delivrd | 19-11-18 16:52:40.000000| 31524|delivrd |delivrd | 19-11-18 16:53:00.000000| 31524|delivrd |delivrd | 19-11-18 16:53:20.000000| 31808|delivrd |delivrd | 19-11-18 16:53:40.000000| 31240|delivrd |delivrd | 19-11-18 16:54:00.000000| 31524|delivrd |delivrd | 19-11-18 16:54:20.000000| 31524|delivrd |delivrd | 19-11-18 16:54:40.000000| 31240|delivrd |delivrd | 19-11-18 16:55:00.000000| 31524|delivrd |delivrd | 19-11-18 16:55:20.000000| 28400|delivrd |delivrd | 19-11-18 16:55:40.000000| 31808|delivrd |delivrd | 19-11-18 16:56:00.000000| 31524|delivrd |delivrd | 19-11-18 16:56:20.000000| 31240|delivrd |delivrd | 19-11-18 16:56:40.000000| 31524|delivrd |delivrd | 19-11-18 16:57:00.000000| 32092|delivrd |delivrd | 19-11-18 16:57:20.000000| 31240|delivrd |delivrd | 19-11-18 16:57:40.000000| 32092|delivrd |delivrd | 19-11-18 16:58:00.000000| 31240|delivrd |delivrd | 19-11-18 16:58:20.000000| 22720|delivrd |delivrd | 19-11-18 16:50:40.000000| 190848|send |send |
自動創建的連續查詢的表中實際的數據為:
taos> select * from test_stream_sum; ts | sum_value_ | ================================================ 19-11-18 17:17:30.000000| 2556| 19-11-18 17:17:40.000000| 18460| 19-11-18 17:17:50.000000| 15904| 19-11-18 17:18:00.000000| 15620| Query OK, 4 row(s) in set (0.000431s)
上述結果并不是期待的結果,沒有按照我定義的group by字段進行聚合查詢顯示。
于是github Issues, taos的攻城獅回復“連續查詢目前還不能很好的支持 group by,這個問題已經在我們的計劃列表里,后續會完善這方面的功能”,原因是“因為這樣回寫后,新表的時間戳主鍵可能出現相同(不同的group by字段會有相同的時間),就會沖突了,所以暫時不支持”。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“TDengine+Grafana如何實現數據可視化”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





