溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
讓我們快樂的開始到結束-經過漫長的搜索,我們設法在我們的一個日志偵聽器中發現了Netty內存泄漏,并能夠在服務崩潰之前及時解決并修復問題。
備份一下,讓我們提供一些背景信息。
Logz.io的日志偵聽器充當從我們的用戶收集的數據的入口,然后被推送到我們的Kafka實例。 它們是基于Netty的Dockerized Java服務,旨在處理極高的吞吐量。
網絡內存泄漏并非罕見。 過去,我們分享了從ByteBuf內存泄漏中汲取的一些經驗教訓,并且還會出現其他類型的內存問題,尤其是在處理大量數據時。 手動調整未使用對象的清理過程非常棘手,并且消耗內存的情況是許多傷痕累累的工程團隊遇到的情況(不相信我嗎?
但是,在每天要處理數百萬條日志消息的生產環境中,這些事件冒著被忽視的風險,直到災難來臨和內存用完為止。 然后,他們非常受關注。
那么,在這種情況下如何識別Netty內存泄漏?
答案就是Logz.io的Cognitive Insights,該技術將機器學習與眾包相結合,可以準確地揭示此類事件。 它通過識別日志和技術論壇中的討論之間的相關性并將它們標記為Kibana中的事件來工作。 然后,它將它們與可操作的信息一起顯示,這些信息可用于調試并防止將來發生同一事件。
在相關日子(即1月15日),我們的系統記錄了超過4億條日志消息。 在這些消息中,Cognitive Insights識別了由偵聽器服務生成的一條日志消息-NettyBufferLeak。
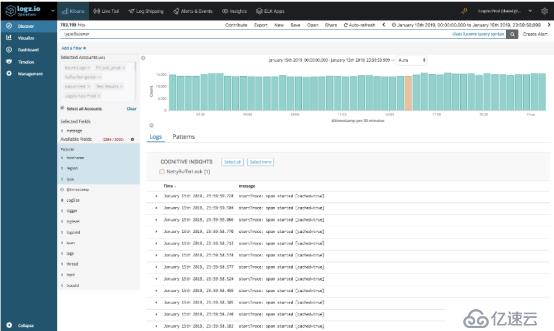
打開洞察力,揭示了更多細節。 事實證明,該事件在最近一周內發生了四次,并且該特定事件已在Netty的技術文檔中進行了討論。
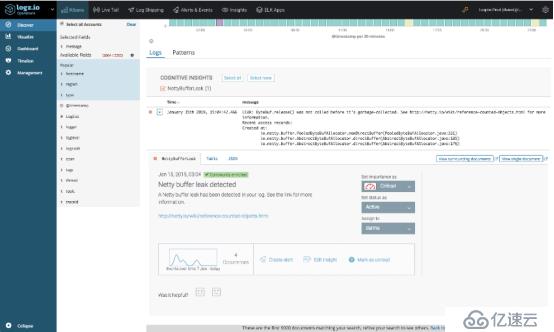
通過查看消息中包含的實際堆棧跟蹤,我們的團隊能夠了解泄漏的原因并進行修復。
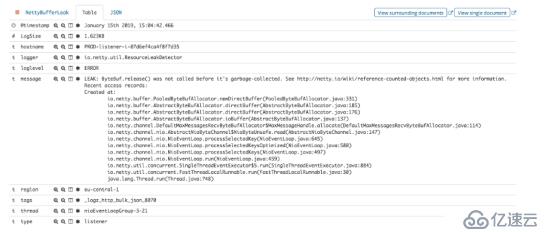
盡管有針對失敗的偵聽器的故障安全機制,但Logz.io不能承受這種情況,因此,我們寧愿避免喚醒一位待命的工程師。
為防止將來發生類似的內存泄漏,我們根據見解中提供給我們的信息執行了許多措施。 首先,我們根據特定的日志消息創建了測試,洞察力浮出水面,然后使用它們來驗證我們對漏洞的修復未生成日志。 其次,如果此確切事件將來發生,我們將創建警報以通知我們。
4、結論
在日志分析領域,工程師面臨的最大挑戰之一是如何在大海撈針中找到針頭并識別出單個日志消息,這表明環境中的某些內容已損壞并將使我們的服務崩潰。通常,事件不會在被攝入系統中的大數據流中被忽略。
有多種方法可用來克服這一挑戰,一種流行的方法是異常檢測。確定正常行為的基準,并偏離該基準觸發警報。盡管在某些情況下足夠了,但傳統的異常檢測系統很可能無法識別Netty內存泄漏,這是一個非常緩慢和逐漸的事件,隨著時間的推移會間歇性地發生泄漏。
利用特定日志消息和網絡上大量技術知識之間的關聯性,可以幫助您發現那些本來不會引起注意的關鍵事件。我們的許多用戶已經為此目的而利用了Cognitive Insights,接下來我將介紹一些我們幫助發現的事件的示例。
?
文章寫到這里,如有不足之處歡迎補充評論。
抽絲剝繭細說架構那些事--優銳課
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





