溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
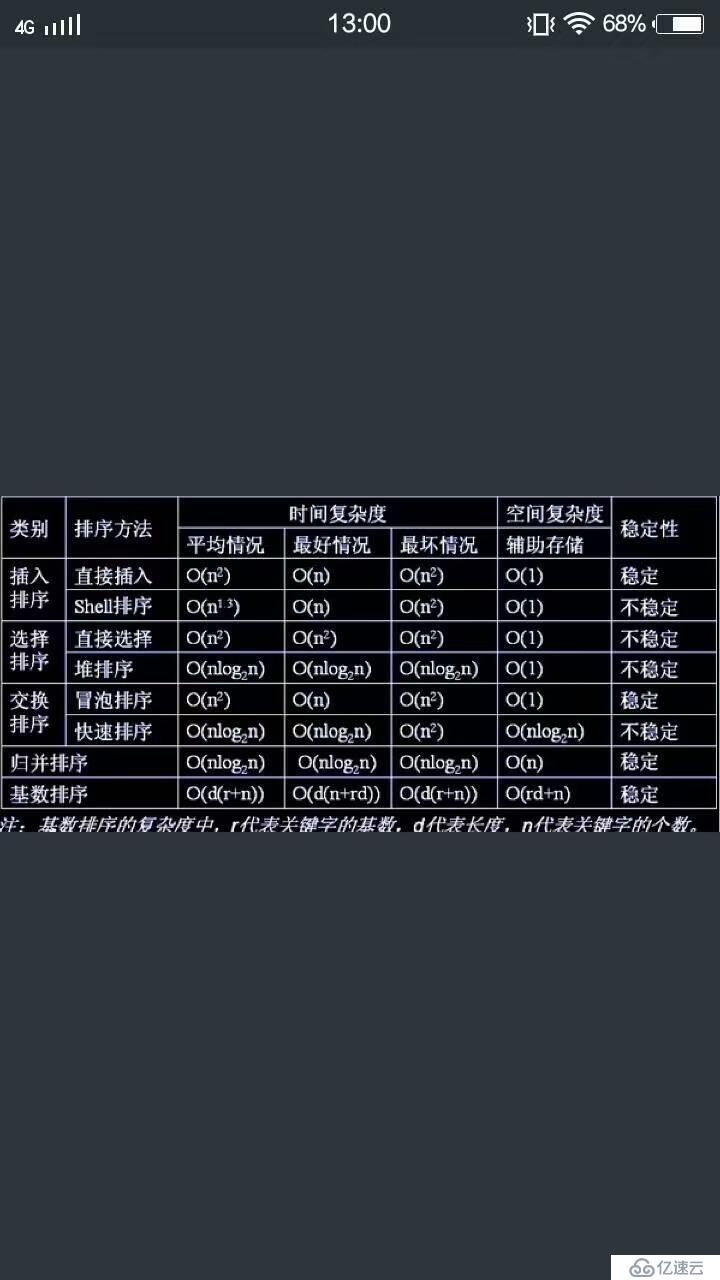
排序算法中的穩定和不穩定指的是什么?
若在待排序的紀錄中,存在兩個或兩個以上的關鍵碼值相等的紀錄,經排序后這些記錄的相對次序仍然保持不變,則稱相應的排序方法是穩定的方法,否則是不穩定的方法。
根據排序過程中涉及的存儲器不同,可以講排序方法分為兩大類:一類是內部排序,指的是待排序的幾率存放在計算機隨機存儲器中進行的排序過程;另一類的外部排序,指的是排序中要對外存儲器進行訪問的排序過程。
內部排序是排序的基礎,在內部排序中,根據排序過程中所依據的原則可以將它們分為5類:插入排序、交換排序、選擇排序、歸并排序和基數排序;
根據排序過程的時間復雜度來分,可以分為三類:簡單排序、先進排序、基數排序。
評價排序算法優劣的標準主要是兩條:一是算法的運算量,這主要是通過記錄的比較次數和移動次數來反應;另一個是執行算法所需要的附加存儲單元的的多少。
插入排序:
有一個已經有序的數據序列,要求在這個已經排好的數據序列中插入一個數,但要求插入后此數據序列仍然有序,這個時候就要用到一種新的排序方法——插入排序法,插入排序的基本操作就是將一個數據插入到已經排好序的有序數據中,從而得到一個新的、個數加一的有序數據,算法適用于少量數據的排序,時間復雜度為O(n^2)。是穩定的排序方法。插入算法把要排序的數組分成兩部分:第一部分包含了這個數組的所有元素,但將最后一個元素除外(讓數組多一個空間才有插入的位置),而第二部分就只包含這一個元素(即待插入元素)。在第一部分排序完成后,再將這個最后元素插入到已排好序的第一部分中。
插入排序的基本思想是:每步將一個待排序的紀錄,按其關鍵碼值的大小插入前面已經排序的文件中適當位置上,直到全部插入完為止。
void InsertSort(int *arr, size_t size)
{
assert(arr);
for (int i = 0; i < size - 1; ++i)
{
int tmp = arr[i+1];
int end = i;
while (end >= 0&&arr[end]>tmp)
{
arr[end + 1] = arr[end];
--end;
}
arr[end + 1] = tmp;//即使都大于tmp,將tmp放置arr[0]處
}
}希爾排序:
希爾排序(Shell Sort)是插入排序的一種。也稱縮小增量排序,是直接插入排序算法的一種更高效的改進版本。希爾排序是非穩定排序算法。
希爾排序是把記錄按下標的一定增量分組,對每組使用直接插入排序算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個文件恰被分成一組,算法便終止。
希爾排序是基于插入排序的以下兩點性質而提出改進方法的:
插入排序在對幾乎已經排好序的數據操作時,效率高,即可以達到線性排序的效率。
但插入排序一般來說是低效的,因為插入排序每次只能將數據移動一位。
先取一個小于n的整數d1作為第一個增量,把文件的全部記錄分組。所有距離為d1的倍數的記錄放在同一個組中。先在各組內進行直接插入排序;然后,取第二個增量d2<d1重復上述的分組和排序,直至所取的增量  =1(
=1(  <
<  …<d2<d1),即所有記錄放在同一組中進行直接插入排序為止。該方法實質上是一種分組插入方法。
…<d2<d1),即所有記錄放在同一組中進行直接插入排序為止。該方法實質上是一種分組插入方法。
void ShellSort(int *arr, size_t size)
{
assert(arr);
int gap = size;
while (gap>1)//注意跳出條件
{
gap = gap / 3 + 1;
for (int i = 0; i < size - gap; ++i)//i可取到size-1-gap
{
int tmp = arr[i + gap];
int end = i;
while (end >= 0 && arr[end]>tmp)
{
arr[end + gap] = arr[end];
end-=gap;
}
arr[end + gap] = tmp;//即使都大于tmp,將tmp放置arr[0]處
}
}
}選擇排序:
選擇排序(Selection sort)是一種簡單直觀的排序算法。它的工作原理是每一次從待排序的數據元素中選出最小(或最大)的一個元素,存放在序列的起始位置,直到全部待排序的數據元素排完。
n個記錄的文件的直接選擇排序可經過n-1趟直接選擇排序得到有序結果:
①初始狀態:無序區為R[1..n],有序區為空。
②第1趟排序
在無序區R[1..n]中選出關鍵字最小的記錄R[k],將它與無序區的第1個記錄R[1]交換,使R[1..1]和R[2..n]分別變為記錄個數增加1個的新有序區和記錄個數減少1個的新無序區。
……
③第i趟排序
第i趟排序開始時,當前有序區和無序區分別為R[1..i-1]和R(i..n)。該趟排序從當前無序區中選出關鍵字最小的記錄 R[k],將它與無序區的第1個記錄R交換,使R[1..i]和R分別變為記錄個數增加1個的新有序區和記錄個數減少1個的新無序區。
思路:對比數組中前一個元素跟后一個元素的大小,如果后面的元素比前面的元素小則用一個變量k來記住他的位置,接著第二次比較,前面“后一個元素”現變成了“前一個元素”,繼續跟他的“后一個元素”進行比較如果后面的元素比他要小則用變量k記住它在數組中的位置(下標),等到循環結束的時候,我們應該找到了最小的那個數的下標了,然后進行判斷,如果這個元素的下標不是第一個元素的下標,就讓第一個元素跟他交換一下值,這樣就找到整個數組中最小的數了。然后找到數組中第二小的數,讓他跟數組中第二個元素交換一下值,以此類推。
void SearchSort(int *arr, size_t size)
{
assert(arr);
for (int i = 0,j=size-1; i < j; ++i,-j)
{
int min = i;
int max = j;
for (int k = i; k<=j;++k)
{
if (arr[min]>arr[k])
min = k;
if (arr[max] < arr[k])
max = k;
}
if (min != i)
{
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
if (max == i) //如果最大值在最左邊,肯定要被移走,此時要轉移到相應的新位置
{
max = min;
}
}
if (max != j)
{
int tmp = arr[j];
arr[j] = arr[max];
arr[max] = tmp;
}
}
}快速排序:
快速排序(Quicksort)是對冒泡排序的一種改進。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通過一趟排序將要排序的數據分割成獨立的兩部分,其中一部分的所有數據都比另外一部分的所有數據都要小,然后再按此方法對這兩部分數據分別進行快速排序,整個排序過程可以遞歸進行,以此達到整個數據變成有序序列。
在c++中可以用函數qsort()可以直接為數組進行排序。
用 法:
void qsort(void *base, int nelem, int width, int (*fcmp)(const void *,const void *));
參數:
1 待排序數組首地址
2 數組中待排序元素數量
3 各元素的占用空間大小
4 指向函數的指針,用于確定排序的順序。
int Quick_Sort(int *arr, int left, int right)
{
assert(arr);
if (left >= right)
return right;
int tmp = arr[right];
int index = right;
--right;
while (left < right)
{
while (left < right&&arr[left] <= tmp)
left++;
while (left < right&&arr[right] >=tmp)
right--;
if (left < right)
swap(arr[left], arr[right]);
}
if (arr[right] >= tmp)
swap(arr[right], arr[index]);//重點
return right;
}
void QuickSort(int* arr,int left,int right)
{
assert(arr);
if (left < right)
{
int mid = Quick_Sort(arr, left, right);
QuickSort(arr, left, mid-1);
QuickSort(arr, mid+1, right);
}
}冒泡排序:
它重復地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來。走訪數列的工作是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成。
這個算法的名字由來是因為越大的元素會經由交換慢慢“浮”到數列的頂端。
冒泡排序算法的運作如下:(從后往前)
比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。
對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最后一對。在這一點,最后的元素應該會是最大的數。
針對所有的元素重復以上的步驟,除了最后一個。
持續每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較
void BubbleSort(int* arr, size_t size)
{
assert(arr);
int flag = 0;
for (int i = 0; i < size - 1; ++i)
{
flag = 0;
for (int j = 0; j < size - i - 1;++j)
{
if (arr[j]>arr[j + 1])
{
swap(arr[j], arr[j + 1]);
}
flag = 1;
}
if (flag == 0)
break;
}
}歸并排序:
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序算法,該算法是采用分治法(Divide and Conquer)的一個非常典型的應用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為二路歸并。
歸并過程為:比較a[i]和a[j]的大小,若a[i]≤a[j],則將第一個有序表中的元素a[i]復制到r[k]中,并令i和k分別加上1;否則將第二個有序表中的元素a[j]復制到r[k]中,并令j和k分別加上1,如此循環下去,直到其中一個有序表取完,然后再將另一個有序表中剩余的元素復制到r中從下標k到下標t的單元。歸并排序的算法我們通常用遞歸實現,先把待排序區間[s,t]以中點二分,接著把左邊子區間排序,再把右邊子區間排序,最后把左區間和右區間用一次歸并操作合并成有序的區間[s,t]
歸并操作(merge),也叫歸并算法,指的是將兩個順序序列合并成一個順序序列的方法。
如 設有數列{6,202,100,301,38,8,1}
初始狀態:6,202,100,301,38,8,1
第一次歸并后:{6,202},{100,301},{8,38},{1},比較次數:3;
第二次歸并后:{6,100,202,301},{1,8,38},比較次數:4;
第三次歸并后:{1,6,8,38,100,202,301},比較次數:4;
總的比較次數為:3+4+4=11,;
逆序數為14;
歸并操作的工作原理如下:
第一步:申請空間,使其大小為兩個已經排序序列之和,該空間用來存放合并后的序列
第二步:設定兩個指針,最初位置分別為兩個已經排序序列的起始位置
第三步:比較兩個指針所指向的元素,選擇相對小的元素放入到合并空間,并移動指針到下一位置
重復步驟3直到某一指針超出序列尾
將另一序列剩下的所有元素直接復制到合并序列尾
/歸并[)升序
//使用鏈表合并思想
void Merge(int* src, int* dest, int begin1, int end1, int begin2, int end2)
{
assert(src&&dest);
int index = begin1;//兩個區間挨著
while (begin1 < end1&&begin2 < end2)
{
if (src[begin1] < src[begin2])
{
dest[index++] = src[begin1++];
}
else
{
dest[index++] = src[begin2++];
}
}
if (begin1 < end1)
{
while (begin1 < end1)
dest[index++] = src[begin1++];
}
else
{
while (begin2 < end2)
dest[index++] = src[begin2++];
}
}
void _MergeSort(int* src, int* dst, int left, int right)
{
if (left < right - 1)//[)
{
int mid = left + ((right - left) >> 1);
_MergeSort(src, dst, left, mid);
_MergeSort(src, dst, mid, right);
Merge(src, dst, left, mid, mid, right);
memcpy(src + left, dst + left, sizeof(int)*(right - left));
}
}
void MergeSort(int *a, size_t size)
{
int *dest = new int[size];
_MergeSort(a, dest, 0, 10);
delete[] dest;
}基數排序:
基數排序(radix sort)屬于“分配式排序”(distribution sort),又稱“桶子法”(bucket sort)或bin sort,顧名思義,它是透過鍵值的部份資訊,將要排序的元素分配至某些“桶”中,藉以達到排序的作用,基數排序法是屬于穩定性的排序,其時間復雜度為O (nlog(r)m),其中r為所采取的基數,而m為堆數,在某些時候,基數排序法的效率高于其它的穩定性排序法。
以LSD為例,假設原來有一串數值如下所示:
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
首先根據個位數的數值,在走訪數值時將它們分配至編號0到9的桶子中:
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
接下來將這些桶子中的數值重新串接起來,成為以下的數列:
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接著再進行一次分配,這次是根據十位數來分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
接下來將這些桶子中的數值重新串接起來,成為以下的數列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
這時候整個數列已經排序完畢;如果排序的對象有三位數以上,則持續進行以上的動作直至最高位數為止。
//基數排序:利用哈希桶原理把數據排序,可選擇從低位到高位或從高位到低位
//利用稀疏矩陣壓縮存儲進行數據定位
int GetDigit(int* arr, size_t size)
{
int maxDigit = 1;
int maxNum = 10;
for (int i = 0; i < size; ++i)
{
if (arr[i] >= maxNum)
{
int count = maxDigit;
while (maxNum <= arr[i])
{
maxNum *= 10;
++count;
}
maxDigit = count;
}
}
return maxDigit;
}
void LSDSort(int* arr, size_t size)//從低位開始排 MSD從高位開始排
{
int counts[10] = { 0 };//存位數對應數據個數
int startCounts[10] = { 0 };
int *bucket = new int[size];
int digit = 1;//表示先取各位
int maxDigit = GetDigit(arr, size);
int divider = 1;//除數
while (digit++ <= maxDigit)
{
memset(counts, 0, sizeof(int) * 10);
memset(startCounts, 0, sizeof(int) * 10);
for (int i = 0; i < size; ++i)
counts[(arr[i]/divider)% 10]++;
for (int i = 1; i < 10; ++i)
startCounts[i] = startCounts[i - 1] + counts[i - 1];
for (int i = 0; i < size; ++i)
{
bucket[startCounts[(arr[i] / divider) % 10]++] = arr[i];
}
divider *= 10;
memcpy(arr, bucket, sizeof(int)*size);
}
memcpy(arr, bucket, sizeof(int)*size);
delete[] bucket;
}計數排序:
計數排序是一個非基于比較的排序算法,該算法于1954年由 Harold H. Seward 提出。它的優勢在于在對一定范圍內的整數排序時,它的復雜度為Ο(n+k)(其中k是整數的范圍),快于任何比較排序算法。
計數排序對輸入的數據有附加的限制條件:
1、輸入的線性表的元素屬于有限偏序集S;
2、設輸入的線性表的長度為n,|S|=k(表示集合S中元素的總數目為k),則k=O(n)。
在這兩個條件下,計數排序的復雜性為O(n)。
計數排序的基本思想是對于給定的輸入序列中的每一個元素x,確定該序列中值小于x的元素的個數(此處并非比較各元素的大小,而是通過對元素值的計數和計數值的累加來確定)。
void CountSort(int *arr, size_t size,int len)
{
int* bitMap = new int[len];
memset(bitMap, 0, sizeof(int)*len);
for (int i = 0; i < size; ++i)
{
int index = arr[i] >>5;//除以32
int count = arr[i] % 32;
bitMap[index] |= (1 << count);
}
int index = 0;
for (int i = 0; i < len; ++i)
{
int count = 0;
while (count <32&&index<size )
{
if (bitMap[i] & (1 << count))
arr[index++] = i * 32 + count;
++count;
}
}
delete[] bitMap;
}
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





