溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
何為C++對象模型?
語言中直接支持面向對象的部分
對于各種支持的底層實現機制
語言中直接支持面向對象程序設計的部分,如構造函數,析構函數,虛函數,繼承(單繼承,虛繼承)、多態等等。
在C語言中,數據和處理操作是分開來聲明的,也就是說,語言中沒有支持“數據和函數”之間的關聯性,在C++中,通過抽象數據類型(abstract data type,ADT),在類中定義數據和函數,來實現數據和函數的直接綁定。
概括來說,在C++類中有兩種成員數據:static,nonstatic;三種成員函數:static, nonstatic, virtual。

如下面定義Base類
Base類定義:
#pragma once
#include<iostream>
using namespace std;
class Base
{
public:
Base(int);
virtual ~Base(void);
int getIBase() const;
static int instanceCount();
virtual void print() const;
protected:
int iBase;
static int count;
};Base類在機器中是如何構建出各種成員數據和成員函數呢?
基本C++對象模型
有兩種,簡單對象模型和表格驅動模型

所有相同的成員占用的空間(跟類型無關),對象只是維護了一個包含成員指針的一個表。表中放的是成員地址,無論是成員變量還是成員函數,都是這樣處理。對象并沒有直接保存成員而是保存了成員的指針。
表格驅動模型
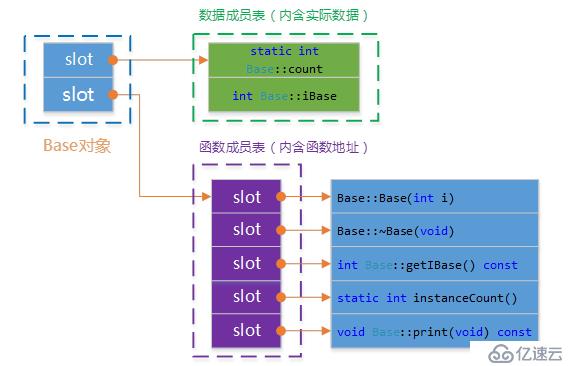
這個模型在簡單模型基礎上又填了間接層。將成員分成函數和數據,并且用兩個表格保存,然后對象只保存了兩個指向表格的指針,這個模型可以保證所有對象具有相同的大小,比如簡單對象模型還與成員個數有關,其中數據成員表中還包含實際數據;函數成員表中包含實際函數地址(與數據成員相比,多一次尋址)
C++對象模型
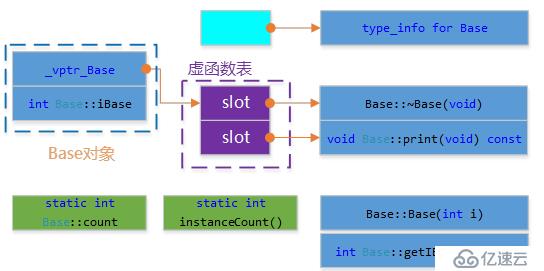
這個模型結合表格驅動模型總的特點,并對內存存取和空間進行了優化。在此模型中,nostatic數據成員被放在對象內部,static數據成員,static和nonstatic函數成員均被列到對象之外,對于虛函數的支持則分成兩步完成
每一個class產生一堆指向虛函數的指針,放在表格中。這個表格稱為虛函數表。
每一個對象被添加一個指針,指向相關函數的vtbl。通常這個指針被稱為Vptr。vptr的設定和重置都有每個class的構造函數,析構函數和拷貝賦值運算符自動完成。
另外,虛函數表地址的前面設置了一個指向type_info的指針,RTTI運行時類型識別是由編譯器在編譯期生成的特殊類型信息,包括對象繼承關系,對象本身的描述,RTTI是為多態而生成的信息,所以只有具有虛函數的對象才會生成。
優點:它的空間和存取時間的效率高。
缺點:如果程序本身未改變,但當使用的類的nonstatic數據成員添加刪除或修改時,需要重新編譯
C++對象模型加入單繼承
不管單繼承多繼承還是虛繼承,如果基于“簡單對象模型”,每一個基類都可以被派生類中的slot指出,該slot內包含基類對象的地址,這個機制主要缺點是,因為間接性而導致空間和存取時間上的額外負擔,優點則是派生類對象的大小不會因為基類的改變而受影響。
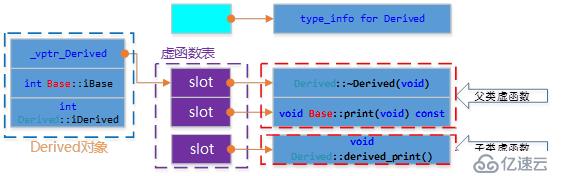
無重寫的單繼承
//Derived類:
#pragma once
#include "base.h"
class Derived :
public Base
{
public:
Derived(int);
virtual ~Derived(void);
virtual void derived_print(void);
protected:
int iDerived;
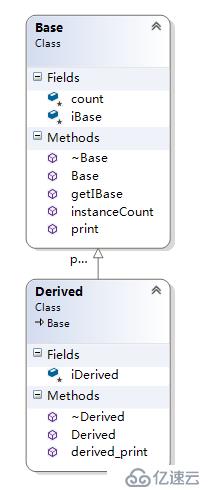
};Base、Derived的類圖
|
注:子類沒有重新父類函數的情況
|
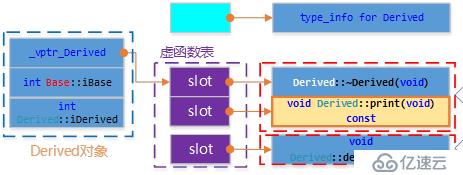
有重寫的單繼承
//Derived_Overwrite類:
#pragma once
#include "base.h"
class Derived_Overrite :
public Base
{
public:
Derived_Overrite(int);
virtual ~Derived_Overrite(void);
virtual void print(void) const;
protected:
int iDerived;
};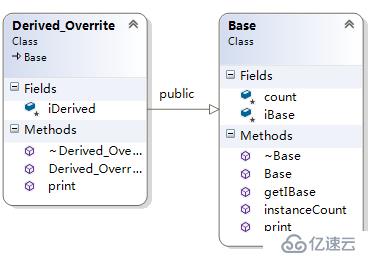 |
注:子類有函數重寫父類函數的情況 1.父類的虛函數在虛函數表的【前面】 2.子類的虛函數在虛函數表的【后面】 3.子類重寫父類的虛函數,替換父類對應的虛函數,出現在虛函數表里【前面】 |
C++對象模型中加入多繼承
從單繼承可以知道,派生類中只是擴充了基類的虛函數表。如果是多繼承的話,又是如何擴充的呢?
1)每個基類都有自己的虛表
2)子類的成員函數放到了第一個基類的表中
3)內存布局中,其父類布局一次按聲明順序排列
4)每個基類的虛表中的Print()函數被overwrite成了子類的Print()。這樣做就是為了解決不同基類類型的指針指向同一個子類的實例,而能夠調用到實際的函數。
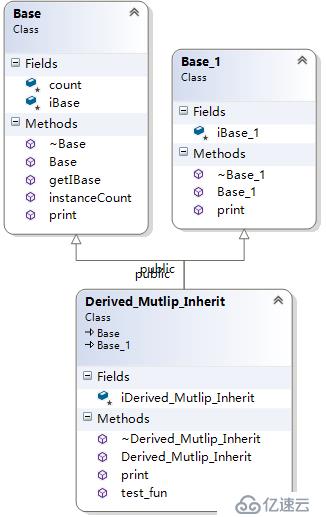
上面3個類,Derived_Mutlip_Inherit繼承自Base、Base_1兩個類,Derived_Mutlip_Inherit的結構如下所示:
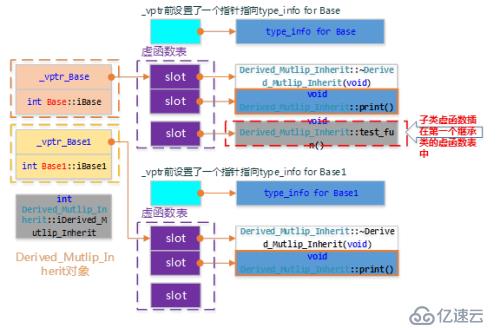
C++對象模型中加入虛繼承
虛繼承是為了解決重復繼承中多個間接父類的問題的,所以不能使用上面簡單的擴充并為每個虛基類 提供一個虛函數指針(這樣做會導致重復繼承的基類會有多個虛函數表)形式。虛繼承的派生類的內存結構,和普通繼承完全不同,虛繼承的子類,有單獨的虛函數表,另外也單獨保存一份父類的虛函數表,兩部分之間用一個四個字節的0x00000000來作為分界,派生類的內存中,首先是自己的虛函數表,然后是派生類成員的數據,然后是0x0,之后就是基類的虛函數表,之后是基類數據成員。
如果派生類沒有自己的虛函數,那么派生類就不會有虛函數表,但是派生類數據和基類數據之間,還需要用0x0來間隔。因此在虛繼承中,派生類和基類的數據,是完全間隔的,先存放派生類自己的虛函數表和數據,中間以0x分界,然后保存基類的虛函數和數據,如果派生類重載了父類的虛函數,那么則派生類內存中的基類虛函數表的相應函數替換。
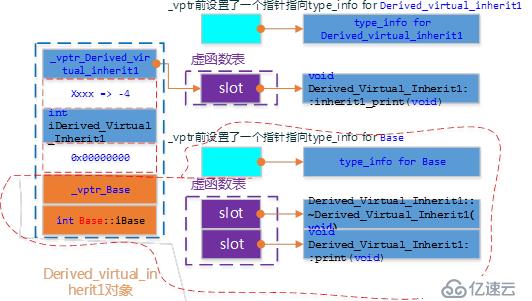
簡單虛繼承(無重復繼承)
簡單虛繼承的2個類Base、Derived_Virtual_Inherit1的關系如下所示:
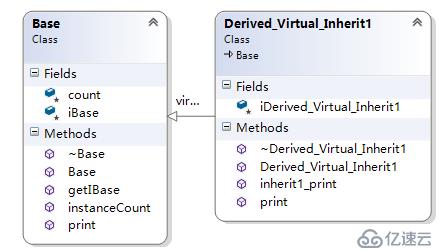
Derived_Virtual_Inherit1的對象模型如下圖:
| 注:虛 基類的信息是獨立de
|
菱形繼承(含重復繼承、多繼承情況)
菱形繼承關系如下:
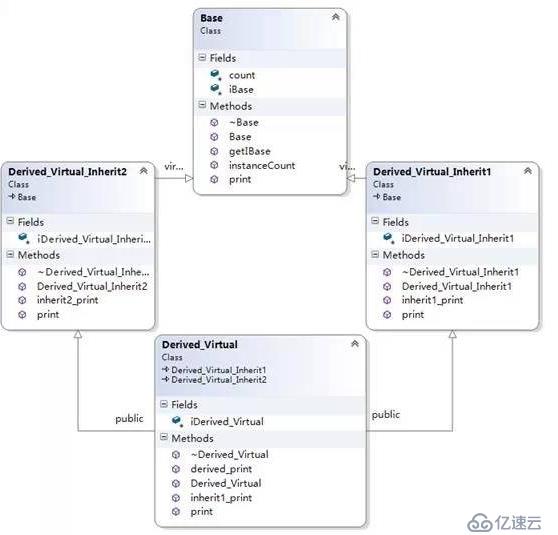
Derived_Virtual的對象模型如下圖:
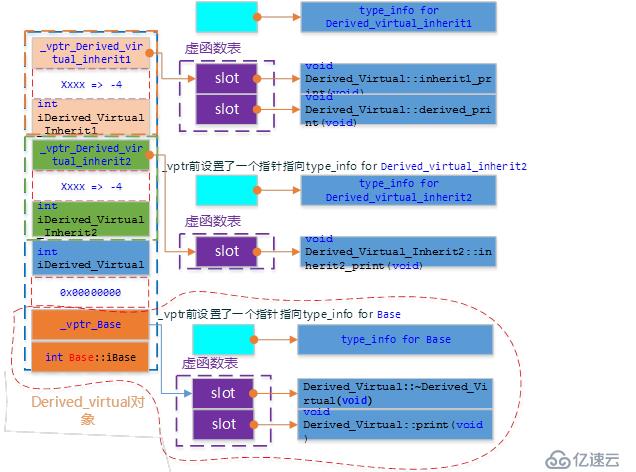
注:虛基類的信息是獨立的,多繼承的布局和之前一樣
1.基類的虛函數表指針及數據成員按照繼承的排序序列【前面】
2.虛基類的信息與子類的信息使用0x00000000與子類分隔開來,虛基類函數表指針及數據成員【后面】
3.子類重寫所有基類(包含虛基類)的虛函數表對應的函數
對象大小問題
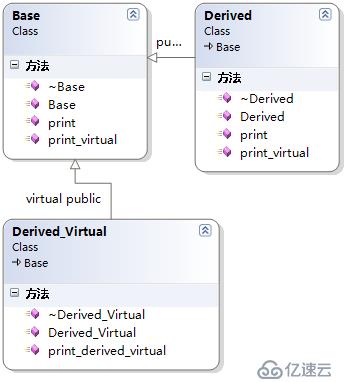
三個類中的函數都是虛函數
●Derived繼承Base
●Derived_Virtual虛繼承Base
//測試對象大小:
void test_size()
{
Base b;
Derived d;
Derived_Virtual dv;
cout << "sizeof(b):\t" << sizeof(b) << endl;
cout << "sizeof(d):\t" << sizeof(d) << endl;
cout << "sizeof(dv):\t" << sizeof(dv) << endl;
}輸出如下
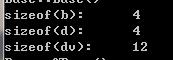
因為Base類中包含虛函數指針,所有size為4,;Derived繼承Base,只是擴充基類的虛函數表,不會新增虛函數表指針,所以size也是4,Derived-Virtusl虛繼承Base,根據前面的模型知道,派生類有自己的虛函數表及指針,并且有分隔符(0x00000000)然后才有虛基類的虛函數表等信息,故大小為4+4+4=12
數據成員是如何訪問的?
跟實際對象模型相關聯,根據對象地址+偏移量取得
靜態綁定與動態綁定
綁定:把函數體與函數調用相聯系稱為綁定
程序調用函數時,將使用哪個可執行的代碼塊?編譯器負責回答這個問題,將源代碼中的函數調用解析為執行特定函數代碼塊被稱為函數名綁定,在VC語言中,這非常簡單,因為每個函數名都對應一個不同的額函數,在C++中,由于函數重載的緣故,這項任務復雜,編譯器必須查看函數參數以及函數名才能確定使用哪個函數,然而編譯器可以在編譯過程中完成這種綁定,這稱為靜態綁定,有稱為早起綁定。
然而虛函數使得這項工作變得困難,使用那個函數不是能在編譯階段確定的,因為編譯器不知道用戶選擇哪種類型。所以編譯器必須在程序運行時選擇正確的函數代碼,這稱為動態綁定,又稱為晚期綁定。
使用虛函數是有代價的,在內存和執行速度方面是有一定成本的,包括:
●每個對象都將增大,增大量為存儲虛函數表指針的大小;
●對于每個類,編譯器都創建一個虛函數地址表;
●對于每個函數調用,都需要執行一項額外的操作,即到虛函數表中查找地址。
雖然非虛函數比虛函數效率稍高,單不具備動態聯編能力。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。