溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
為什么要來講指針呢?因為指針對于C來說太重要。
然而,想要全面理解指針,除了要對C語言有熟練的掌握外,還要有計算機硬件以及操作系統等方方面面的基本知識。
所以我們通過一篇文章來盡可能的講解指針,以對得起這個文章的標題吧。
為什么需要指針?
指針解決了一些編程中基本的問題。
第一,指針的使用使得不同區域的代碼可以輕易的共享內存數據。當然小伙伴們也可以通過數據的復制達到相同的效果,但是這樣往往效率不太好。
因為諸如結構體等大型數據,占用的字節數多,復制很消耗性能。
但使用指針就可以很好的避免這個問題,因為任何類型的指針占用的字節數都是一樣的(根據平臺不同,有4字節或者8字節或者其他可能)。
第二,指針使得一些復雜的鏈接性的數據結構的構建成為可能,比如鏈表,鏈式二叉樹等等。
第三,有些操作必須使用指針。如操作申請的堆內存。
還有:C語言中的一切函數調用中,值傳遞都是“按值傳遞”的。
如果我們要在函數中修改被傳遞過來的對象,就必須通過這個對象的指針來完成。
指針是什么?
我們知道:C語言中的數組是指一類類型,數組具體區分為 int 類型數組,double類型數組,char數組 等等。
同樣指針這個概念也泛指一類數據類型,int指針類型,double指針類型,char指針類型等等。
通常,我們用int類型保存一些整型的數據,如 int num = 97 , 我們也會用char來存儲字符:char ch = 'a'。
我們也必須知道:任何程序數據載入內存后,在內存都有他們的地址,這就是指針。
而為了保存一個數據在內存中的地址,我們就需要指針變量。
因此:指針是程序數據在內存中的地址,而指針變量是用來保存這些地址的變量。

為什么程序中的數據會有自己的地址?
弄清這個問題我們需要從操作系統的角度去認知內存。
電腦維修師傅眼中的內存是這樣的:內存在物理上是由一組DRAM芯片組成的。

而作為一個程序員,我們不需要了解內存的物理結構,操作系統將RAM等硬件和軟件結合起來,給程序員提供的一種對內存使用的抽象。
這種抽象機制使得程序使用的是虛擬存儲器,而不是直接操作和使用真實存在的物理存儲器。
所有的虛擬地址形成的集合就是虛擬地址空間。
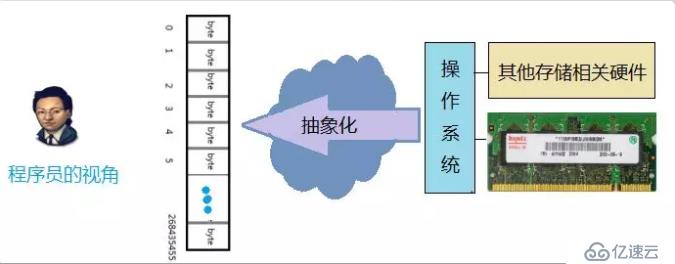
在程序員眼中的內存應該是下面這樣的。

也就是說,內存是一個很大的,線性的字節數組(平坦尋址)。每一個字節都是固定的大小,由8個二進制位組成。
最關鍵的是,每一個字節都有一個唯一的編號,編號從0開始,一直到最后一個字節。
如上圖中,這是一個256M的內存,他一共有256x1024x1024 = 268435456個字節,那么它的地址范圍就是 0 ~268435455 。
由于內存中的每一個字節都有一個唯一的編號。
因此,在程序中使用的變量,常量,甚至數函數等數據,當他們被載入到內存中后,都有自己唯一的一個編號,這個編號就是這個數據的地址。
指針就是這樣形成的。
下面用代碼說明
#include <stdio.h>
int main(void)
{
char ch = 'a';
int num = 97;
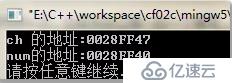
printf("ch 的地址:%p
",&ch); //ch 的地址:0028FF47
printf("num的地址:%p
",&num); //num的地址:0028FF40
return 0;
}
指針的值實質是內存單元(即字節)的編號,所以指針單獨從數值上看,也是整數,他們一般用16進制表示。
指針的值(虛擬地址值)使用一個機器字的大小來存儲。
也就是說,對于一個機器字為w位的電腦而言,它的虛擬地址空間是0~2w - 1 ,程序最多能訪問2w個字節。
這就是為什么xp這種32位系統最大支持4GB內存的原因了。
我們可以大致畫出變量ch和num在內存模型中的存儲。(假設 char占1個字節,int占4字節)

變量和內存
為了簡單起見,這里就用上面例子中的 int num = 97 這個局部變量來分析變量在內存中的存儲模型。

已知:num的類型是int,占用了4個字節的內存空間,其值是97,地址是0028FF40。我們從以下幾個方面去分析。
1、內存的數據
內存的數據就是變量的值對應的二進制,一切都是二進制。
97的二進制是 : 00000000 00000000 00000000 0110000 , 但使用的小端模式存儲時,低位數據存放在低地址,所以圖中畫的時候是倒過來的。
2、內存數據的類型
內存的數據類型決定了這個數據占用的字節數,以及計算機將如何解釋這些字節。
num的類型是int,因此將被解釋為 一個整數。
3、內存數據的名稱
內存的名稱就是變量名。實質上,內存數據都是以地址來標識的,根本沒有內存的名稱這個說法,這只是高級語言提供的抽象機制 ,方便我們操作內存數據。
而且在C語言中,并不是所有的內存數據都有名稱,例如使用malloc申請的堆內存就沒有。
4、內存數據的地址
如果一個類型占用的字節數大于1,則其變量的地址就是地址值最小的那個字節的地址。
因此num的地址是 0028FF40。內存的地址用于標識這個內存塊。
5、內存數據的生命周期
num是main函數中的局部變量,因此當main函數被啟動時,它被分配于棧內存上,當main執行結束時,消亡。
如果一個數據一直占用著他的內存,那么我們就說他是“活著的”,如果他占用的內存被回收了,則這個數據就“消亡了”。
C語言中的程序數據會按照他們定義的位置,數據的種類,修飾的關鍵字等因素,決定他們的生命周期特性。
實質上我們程序使用的內存會被邏輯上劃分為:棧區,堆區,靜態數據區,方法區。
不同的區域的數據有不同的生命周期。
無論以后計算機硬件如何發展,內存容量都是有限的,因此清楚理解程序中每一個程序數據的生命周期是非常重要的。
指針變量和指向關系
用來保存指針的變量,就是指針變量。
如果指針變量p1保存了變量 num的地址,則就說:p1指向了變量num,也可以說p1指向了num所在的內存塊 ,這種指向關系,在圖中一般用 箭頭表示。
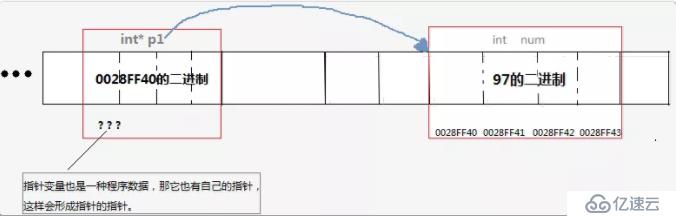
上圖中,指針變量p1指向了num所在的內存塊 ,即從地址0028FF40開始的4個byte 的內存塊。
定義指針變量
C語言中,定義變量時,在變量名前寫一個 * 星號,這個變量就變成了對應變量類型的指針變量。必要時要加( ) 來避免優先級的問題。
引申:C語言中,定義變量時,在定義的最前面寫上typedef ,那么這個變量名就成了一種類型,即這個類型的同義詞。
int a ; //int類型變量 a
int *a ; //int* 變量a
int arr[3]; //arr是包含3個int元素的數組
int (* arr )[3]; //arr是一個指向包含3個int元素的數組的指針變量
//-----------------各種類型的指針------------------------------
int* p_int; //指向int類型變量的指針
double* p_double; //指向idouble類型變量的指針
struct Student *p_struct; //結構體類型的指針
int(*p_func)(int,int); //指向返回類型為int,有2個int形參的函數的指針
int(*p_arr)[3]; //指向含有3個int元素的數組的指針
int** p_pointer; //指向 一個×××變量指針的指針取地址
既然有了指針變量,那就得讓他保存其它變量的地址,使用& 運算符取得一個變量的地址。
int add(int a , int b)
{
return a + b;
}
int main(void)
{
int num = 97;
float score = 10.00F;
int arr[3] = {1,2,3};
//-----------------------
int* p_num = #
float* p_score = &score;
int (*p_arr)[3] = &arr;
int (*fp_add)(int ,int ) = add; //p_add是指向函數add的函數指針
return 0;
}特殊的情況,他們并不一定需要使用&取地址:
數組名的值就是這個數組的第一個元素的地址。
函數名的值就是這個函數的地址。
字符串字面值常量作為右值時,就是這個字符串對應的字符數組的名稱,也就是這個字符串在內存中的地址。
int add(int a , int b){
return a + b;
}
int main(void)
{
int arr[3] = {1,2,3};
//-----------------------
int* p_first = arr;
int (*fp_add)(int ,int ) = add;
const char* msg = "Hello world";
return 0;
}解地址
我們需要一個數據的指針變量干什么?
當然使用通過它來操作(讀/寫)它指向的數據啦。
對一個指針解地址,就可以取到這個內存數據,解地址的寫法,就是在指針的前面加一個*號。
解指針的實質是:從指針指向的內存塊中取出這個內存數據。
int main(void)
{
int age = 19;
int*p_age = &age;
*p_age = 20; //通過指針修改指向的內存數據
printf("age = %d
",*p_age); //通過指針讀取指向的內存數據
printf("age = %d
",age);
return 0;
}指針之間的賦值
指針賦值和int變量賦值一樣,就是將地址的值拷貝給另外一個。
指針之間的賦值是一種淺拷貝,是在多個編程單元之間共享內存數據的高效的方法。
int p1 = & num;
int p3 = p1;
//通過指針 p1 、 p3 都可以對內存數據 num 進行讀寫,如果2個函數分別使用了p1 和p3,那么這2個函數就共享了數據num。

空指針
指向空,或者說不指向任何東西。
在C語言中,我們讓指針變量賦值為NULL表示一個空指針,而C語言中,NULL實質是 ((void*)0) , 在C++中,NULL實質是0。
換種說法:任何程序數據都不會存儲在地址為0的內存塊中,它是被操作系統預留的內存塊。
下面代碼摘自 stdlib.h
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif壞指針
指針變量的值是NULL,或者未知的地址值,或者是當前應用程序不可訪問的地址值,這樣的指針就是壞指針。
不能對他們做解指針操作,否則程序會出現運行時錯誤,導致程序意外終止。
任何一個指針變量在做解地址操作前,都必須保證它指向的是有效的,可用的內存塊,否則就會出錯。
壞指針是造成C語言Bug的最頻繁的原因之一。
下面的代碼就是錯誤的示例。
void opp()
{
int*p = NULL;
*p = 10; //Oops! 不能對NULL解地址
}
void foo()
{
int*p;
*p = 10; //Oops! 不能對一個未知的地址解地址
}
void bar()
{
int*p = (int*)1000;
*p =10; //Oops! 不能對一個可能不屬于本程序的內存的地址的指針解地址
}指針的2個重要屬性
指針也是一種數據,指針變量也是一種變量,因此指針 這種數據也符合前面變量和內存主題中的特性。
這里要強調2個屬性:指針的類型,指針的值。
int main(void)
{
int num = 97;
int *p1 = #
char* p2 = (char*)(&num);
printf("%d
",*p1); //輸出 97
putchar(*p2); //輸出 a
return 0;
}指針的值:很好理解,如上面的num 變量 ,其地址的值就是0028FF40 ,因此 p1的值就是0028FF40。
數據的地址用于在內存中定位和標識這個數據,因為任何2個內存不重疊的不同數據的地址都是不同的。
指針的類型:指針的類型決定了這個指針指向的內存的字節數并如何解釋這些字節信息。
一般指針變量的類型要和它指向的數據的類型匹配。
由于num的地址是0028FF40,因此 p1 和 p2 的值都是0028FF40
*p1 : 將從地址0028FF40 開始解析,因為p1是int類型指針,int占4字節,因此向后連續取4個字節,并將這4個字節的二進制數據解析為一個整數 97。
*p2 : 將從地址0028FF40 開始解析,因為p2是char類型指針,char占1字節,因此向后連續取1個字節,并將這1個字節的二進制數據解析為一個字符,即'a'。
同樣的地址,因為指針的類型不同,對它指向的內存的解釋就不同,得到的就是不同的數據。
void*類型指針
由于void是空類型,因此void*類型的指針只保存了指針的值,而丟失了類型信息,我們不知道他指向的數據是什么類型的,只指定這個數據在內存中的起始地址。
如果想要完整的提取指向的數據,程序員就必須對這個指針做出正確的類型轉換,然后再解指針。
因為,編譯器不允許直接對void*類型的指針做解指針操作。
結構體和指針
結構體指針有特殊的語法:-> 符號
如果p是一個結構體指針,則可以使用 p ->【成員】 的方法訪問結構體的成員
typedef struct
{
char name[31];
int age;
float score;
}Student;
int main(void)
{
Student stu = {"Bob" , 19, 98.0};
Student*ps = &stu;
ps->age = 20;
ps->score = 99.0;
printf("name:%s age:%d
",ps->name,ps->age);
return 0;
}數組和指針
1、數組名作為右值的時候,就是第一個元素的地址。
int main(void)
{
int arr[3] = {1,2,3};
int*p_first = arr;
printf("%d
",*p_first); //1
return 0;
}2、指向數組元素的指針 支持 遞增 遞減 運算。
(實質上所有指針都支持遞增遞減 運算 ,但只有在數組中使用才是有意義的)
int main(void)
{
int arr[3] = {1,2,3};
int*p = arr;
for(;p!=arr+3;p++){
printf("%d
",*p);
}
return 0;
}3、p= p+1 意思是,讓p指向原來指向的內存塊的下一個相鄰的相同類型的內存塊。
同一個數組中,元素的指針之間可以做減法運算,此時,指針之差等于下標之差。
4、p[n] == *(p+n)
p[n][m] == ( (p+n)+ m )
5、當對數組名使用sizeof時,返回的是整個數組占用的內存字節數。當把數組名賦值給一個指針后,再對指針使用sizeof運算符,返回的是指針的大小。
這就是為什么將一個數組傳遞給一個函數時,需要另外用一個參數傳遞數組元素個數的原因了。
int main(void)
{
int arr[3] = {1,2,3};
int*p = arr;
printf("sizeof(arr)=%d
",sizeof(arr)); //sizeof(arr)=12
printf("sizeof(p)=%d
",sizeof(p)); //sizeof(p)=4
return 0;
}函數和指針
函數的參數和指針
C語言中,實參傳遞給形參,是按值傳遞的,也就是說,函數中的形參是實參的拷貝份,形參和實參只是在值上面一樣,而不是同一個內存數據對象。
這就意味著:這種數據傳遞是單向的,即從調用者傳遞給被調函數,而被調函數無法修改傳遞的參數達到回傳的效果。
void change(int a)
{
a++; //在函數中改變的只是這個函數的局部變量a,而隨著函數執行結束,a被銷毀。age還是原來的age,紋絲不動。
}
int main(void)
{
int age = 19;
change(age);
printf("age = %d
",age); // age = 19
return 0;
}有時候我們可以使用函數的返回值來回傳數據,在簡單的情況下是可以的。
但是如果返回值有其它用途(例如返回函數的執行狀態量),或者要回傳的數據不止一個,返回值就解決不了了。
傳遞變量的指針可以輕松解決上述問題。
void change(int* pa)
{
(*pa)++; //因為傳遞的是age的地址,因此pa指向內存數據age。當在函數中對指針pa解地址時,
//會直接去內存中找到age這個數據,然后把它增1。
}
int main(void)
{
int age = 19;
change(&age);
printf("age = %d
",age); // age = 20
return 0;
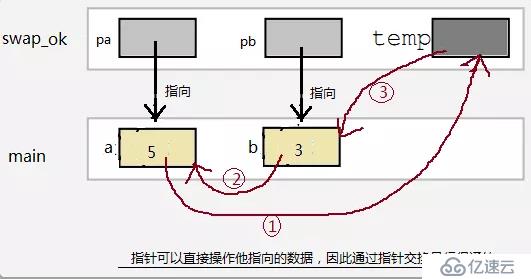
}再來一個老生常談的,用函數交換2個變量的值的例子:
#include<stdio.h>
void swap_bad(int a,int b);
void swap_ok(int*pa,int*pb);
int main()
{
int a = 5;
int b = 3;
swap_bad(a,b); //Can`t swap;
swap_ok(&a,&b); //OK
return 0;
}
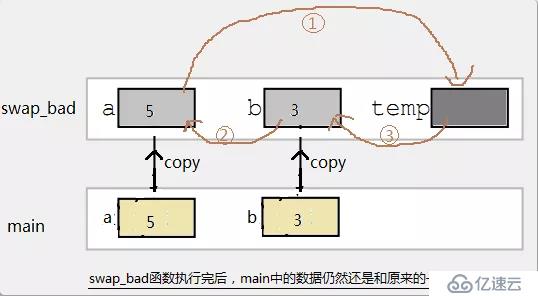
//錯誤的寫法
void swap_bad(int a,int b)
{
int t;
t=a;
a=b;
b=t;
}
//正確的寫法:通過指針
void swap_ok(int*pa,int*pb)
{
int t;
t=*pa;
*pa=*pb;
*pb=t;
}
有的時候,我們通過指針傳遞數據給函數不是為了在函數中改變他指向的對象。
相反,我們防止這個目標數據被改變。傳遞指針只是為了避免拷貝大型數據。
考慮一個結構體類型Student。我們通過show函數輸出Student變量的數據。
typedef struct
{
char name[31];
int age;
float score;
}Student;
//打印Student變量信息
void show(const Student * ps)
{
printf("name:%s , age:%d , score:%.2f
",ps->name,ps->age,ps->score);
}我們只是在show函數中取讀Student變量的信息,而不會去修改它,為了防止意外修改,我們使用了常量指針去約束。
另外我們為什么要使用指針而不是直接傳遞Student變量呢?
從定義的結構看出,Student變量的大小至少是39個字節,那么通過函數直接傳遞變量,實參賦值數據給形參需要拷貝至少39個字節的數據,極不高效。
而傳遞變量的指針卻快很多,因為在同一個平臺下,無論什么類型的指針大小都是固定的:X86指針4字節,X64指針8字節,遠遠比一個Student結構體變量小。
函數的指針
每一個函數本身也是一種程序數據,一個函數包含了多條執行語句,它被編譯后,實質上是多條機器指令的合集。
在程序載入到內存后,函數的機器指令存放在一個特定的邏輯區域:代碼區。
既然是存放在內存中,那么函數也是有自己的指針的。
C語言中,函數名作為右值時,就是這個函數的指針。
void echo(const char *msg)
{
printf("%s",msg);
}
int main(void)
{
void(*p)(const char*) = echo; //函數指針變量指向echo這個函數
p("Hello "); //通過函數的指針p調用函數,等價于echo("Hello ")
echo("World
");
return 0;
}const和指針
const到底修飾誰?誰才是不變的?
如果const 后面是一個類型,則跳過最近的原子類型,修飾后面的數據。
(原子類型是不可再分割的類型,如int, short , char,以及typedef包裝后的類型)
如果const后面就是一個數據,則直接修飾這個數據。
int main()
{
int a = 1;
int const *p1 = &a; //const后面是*p1,實質是數據a,則修飾*p1,通過p1不能修改a的值
const int*p2 = &a; //const后面是int類型,則跳過int ,修飾*p2, 效果同上
int* const p3 = NULL; //const后面是數據p3。也就是指針p3本身是const .
const int* const p4 = &a; // 通過p4不能改變a 的值,同時p4本身也是 const
int const* const p5 = &a; //效果同上
return 0;
}
typedef int* pint_t; //將 int* 類型 包裝為 pint_t,則pint_t 現在是一個完整的原子類型
int main()
{
int a = 1;
const pint_t p1 = &a; //同樣,const跳過類型pint_t,修飾p1,指針p1本身是const
pint_t const p2 = &a; //const 直接修飾p,同上
return 0;
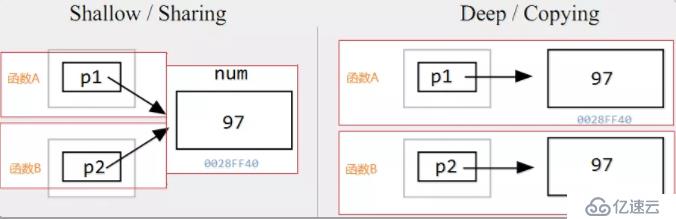
}深拷貝和淺拷貝
如果2個程序單元(例如2個函數)是通過拷貝他們所共享的數據的指針來工作的,這就是淺拷貝,因為真正要訪問的數據并沒有被拷貝。
如果被訪問的數據被拷貝了,在每個單元中都有自己的一份,對目標數據的操作相互不受影響,則叫做深拷貝。
附加知識
指針和引用這個2個名詞的區別。他們本質上來說是同樣的東西。
指針常用在C語言中,而引用,則用于諸如Java,C#等 在語言層面封裝了對指針的直接操作的編程語言中。
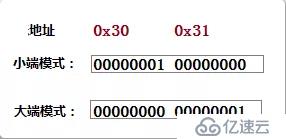
大端模式和小端模式
1) Little-Endian就是低位字節排放在內存的低地址端,高位字節排放在內存的高地址端。個人PC常用,Intel X86處理器是小端模式。
2) B i g-Endian就是高位字節排放在內存的低地址端,低位字節排放在內存的高地址端。
采用大端方式進行數據存放符合人類的正常思維,而采用小端方式進行數據存放利于計算機處理。
有些機器同時支持大端和小端模式,通過配置來設定實際的端模式。
假如 short類型占用2個字節,且存儲的地址為0x30。
short a = 1;
如下圖:
//測試機器使用的是否為小端模式。是,則返回true,否則返回false
//這個方法判別的依據就是:C語言中一個對象的地址就是這個對象占用的字節中,地址值最小的那個字節的地址。
bool isSmallIndain()
{
unsigned int val = 'A';
unsigned char* p = (unsigned char*)&val; //C/C++:對于多字節數據,取地址是取的數據對象的第一個字節的地址,也就是數據的低地址
return *p == 'A';
}**加C/C++學習交流.群獲取C語言、C++、Windows高級編程,MFC框架編程、QT框架編程,大型企業實戰項目。Linux應用程序開發,Linux內核研究等多個知識點高級進階干貨的直播免費學習權限 都是大牛帶飛 讓你少走很多的彎路的 群...號是 546912356
注:加群要求
1、零基礎,目前遇到困難不知從何下手可以加。
2、在公司待久了,過得很安逸,但跳槽時面試碰壁。需要在短時間內進修、跳槽拿高薪的可以加。
3、基礎非常扎實,但對目前主流技術欠缺,需要突破技術瓶頸的可以加。
4、覺得自己很牛B,一般需求都能搞定。但是所學的知識點沒有系統化,很難在技術領域繼續突破的可以加。
5.企業一線C/C++高級大牛直播講解知識點,分享知識,多年工作經驗的梳理和總結,帶著大家全面、科學地建立自己的技術體系和技術認知!**
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





