溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python類和對象如何應用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python類和對象如何應用文章都會有所收獲,下面我們一起來看看吧。
我們前面其實已經接觸過封裝的概念,把亂七八糟的數據扔進列表里面,這是一種封裝,是數據層面的封裝;把常用的代碼段打包成一個函數,這也是一種封裝,是語句層面的封裝;現在我們要學習的對象,也是一種封裝的思想, 對象的來源是模擬真是世界,將數據和代碼都封裝在了一起。
打個比方,烏龜就是真實世界的一個對象,通常會從兩個部分來描述它。
(1)從靜態的特征描述:例如,綠色的,有四條腿,有外殼等等,這是靜態一方面的描述。
(2)從動態的行為描述:例如,它會爬,如果追它,它還會跑,有時還會咬人,睡覺等等,這都是從行為方面進行描述的。
Python中的對象也是如此,一個對象的特征稱為“屬性”,一個對象的行為稱為“方法”。:
如果將烏龜寫成代碼,將會是下面這樣:
class Turtle: # Python中的類名約定以大寫字母開頭
# 特征的描述稱為屬性,在代碼層面看來其實就是變量
color = 'green'
legs = 4
shell = True
# 方法實際就是函數,通過調用這些函數來完成某些工作
def climb(self):
print('向前爬')
def run(self):
print('向前跑')
def bite(self):
print('咬人')
def sleep(self):
print('睡覺')以上代碼定義了對象的特征(屬性)和行為(方法),但還不是一個完整的對象,將定義的這些稱為類(Class)。需要使用類來創建一個真正的對象,這個對象就叫作這個類的一個實例(Instance),也叫實例對象(Instance Objects)。
舉個例子,這就像工廠需要生產一系列玩具,需要先作出這個玩具的模具,然后根據這個模具再進行批量生產。
那么怎么創建真正的實例對象呢?創建一個對象,也叫類的實例化,其實很簡單:
# 首先要有上面那一段類的定義 tt = Turtle()
注意:類名后面跟著小括號,這跟調用函數是一樣的。所以在Python中,類名約定用大寫字母開頭,函數用小寫字母開頭,這樣更容易區分。另外,賦值操作并不是必需的,但如果沒有把創建好的實例對象賦值給一個變量,這個對象就沒辦法使用,因為沒有引用指向這個實例,最終會被Python的垃圾回收機制自動回收。
如果要 調用對象里的方法,使用點操作符(.) 即可。
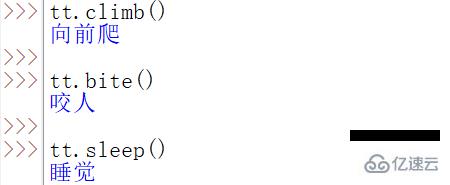
接下來我們看一段代碼,再深入理解一下類、類對象和實例對象三個概念:

從這個例子可以看出,對實例對象c的count屬性進行賦值后,就相當于覆蓋了類對象C的count屬性。如下圖所示,如果沒有賦值覆蓋,那么引用的是類對象的count屬性。
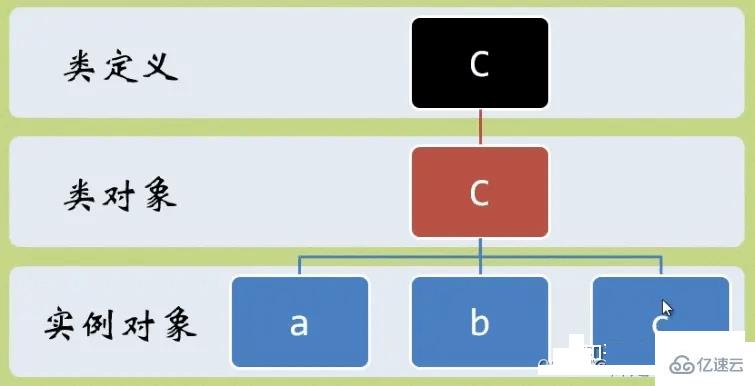
需要注意的是,類中定義的屬性是靜態變量,類的屬性是與類對象進行綁定,并不會依賴任何它的實例對象。
另外,如果屬性的名字跟方法名相同,屬性會覆蓋方法:

為了避免名字上的沖突,應該遵守一些約定俗成的規矩:
(1)不要試圖在一個類里面定義出所有能想到的特性和方法,應該利用繼承和組合機制進行擴展。
(2)用不同的詞性命名,如屬性名用名詞、方法名用動詞,并使用駝峰命名法等。
細心的讀者發現對象的方法都會有一個self參數,那么這個self是什么呢?如果你接觸過C++,那么你應該很容易對號入座,Python的self其實就相當于C++的this指針。
如果你此前沒有接觸過任何編程語言,那么簡單說,如果把類比作圖紙,那么由類實例化后的對象才是真正可以住的房子。根據一張圖紙可以設計出成千上萬的房子,它們外觀都差不多,但是每一個房子都有不同的主人。每個人要找到自己的房子,那self就相當于這里的門牌號,有了self,你就可以輕松找到自己的房子。
Python的self參數就是同一個道理,由一個類可以生成無數個對象,當一個對象方法被調用的時候,對象會將自身的引用作為第一個參數傳給該方法,那么Python就知道需要操作哪個對象的方法了。
舉個簡單的例子:

一般面向對象的編程語言都會區分公有和私有的數據類型,像C++和Java它們使用public和private關鍵字用于聲明數據是公有的還是私有的,但在Python中并沒有類似的關鍵字來修飾。
默認上對象的屬性和方法都是公開的,可以直接通過點操作符(.)進行訪問:

為了實現類似私有變量的特征,Python內部采用了一種叫name mangling(名字改編)的技術,在Python中定義私有變量只需要在變量名或函數名前加上“_ _”兩個下劃線,那么這個函數或變量就會成為私有的了:

這樣,在外部將變量名“隱藏”起來了,理論上如果要訪問,就要從內部進行:

但是認真想一下這個技術的名字name mangling(名字改編),那就不難發現其實Python只是把雙下橫線開頭的變量進行了改名而已。實際上,在外部使用“_類名_ _變量名”即可訪問雙下橫線開頭的私有變量了:

說明:Python目前的私有機制其實是偽私有的,Python的類是沒有權限控制的,所有的變量都是可以被外部調用的。
舉個例子來說明繼承。例如現在有個游戲,需要對魚類進行細分,有金魚(Goldfish)、鯉魚(Carp)、三文魚(Salmon)以及鯊魚(Shark)。那么我們能不能不要每次都從頭到尾去重新定義一個新的魚類呢?因為我們知道大多數魚的屬性和方法是相似的,如果有一種機制可以讓這些相似的東西得以自動傳遞,那么就方便多了。這就是繼承。
繼承的語法很簡單:
c l a s s 類 名 ( 被 繼 承 的 類 ) : . . . class 類名(被繼承的類): \\ \quad ... class類名(被繼承的類):...
被繼承的類稱為基類、父類或超類;繼承者稱為子類,一個子類可以繼承它的父類的任何屬性和方法。
舉個例子:

需要注意的是,如果子類中定義與父類同名的方法或屬性,則會自動覆蓋父類對應的方法或屬性:

接下來,嘗試寫一下開頭提到的金魚(Goldfish)、鯉魚(Carp)、三文魚(Salmon)以及鯊魚(Shark)的例子。
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0, 10)
self.y = r.randint(0, 10)
def move(self):
# 這里主要演示類的繼承機制,就不考慮檢查場景邊界和移動方向問題
# 假設所有的魚都是一路向西游
self.x -= 1
print("我的位置是:", self.x, self.y)
# 金魚
class Goldfish(Fish):
pass
# 鯉魚
class Carp(Fish):
pass
#三文魚
class Salmon(Fish):
pass
# 上面三種魚都是食物,直接繼承Fish類的全部屬性和方法
# 下面定義鯊魚類,除了繼承Fish類的屬性和方法,還要添加一個吃的方法
class Shark(Fish):
def __init__(self):
self.hungry = True
def eat(self):
if self.hungry:
print("吃掉你!")
self.hungry = False
else:
print("太飽了,吃不下了~")首先運行這段代碼,然后進行測試:

同樣是繼承于Fish類,為什么金魚(goldfish)可以移動,而鯊魚(shark)一移動就報錯呢?
可以看到報錯提示為:Shark對象沒有x屬性,這是因為在Shark類中,重寫了_ _init_ _()方法,但新的_ _init_ _()方法里面沒有初始化鯊魚的x坐標和y坐標,因此調用move()方法就會出錯。
那么解決這個問題,只要在鯊魚類中重寫_ _init_ _()方法的時候先調用基類Fish的_ _init_ _()方法。
下面介紹兩種可以實現的技術:
(1)調用未綁定的父類方法
(2)使用super函數
什么是調用未綁定的父類方法?舉個例子:
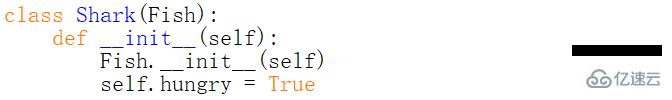
修改之后,再運行下發現鯊魚也可以成功移動了:

這里需要注意的是,這個self并不是父類Fish的實例對象,而是子類Shark的實例對象。所以這里說的未綁定是指并不需要綁定父類的實例對象,使用子類的實例對象代替即可。
super函數能夠幫助我們自動找到基類的方法,而且還為我們傳入了self參數,這樣就不需要做這些事情了:

運行后得到同樣的結果:

除此之外,Python還支持多重繼承,就是可以同時繼承多個父類的屬性和方法:
c l a s s 類 名 ( 父 類 1 , 父 類 2 , 父 類 3 , . . . ) : . . . class 類名(父類1,父類2,父類3,...):\\ \quad ... class類名(父類1,父類2,父類3,...):...
舉個例子:

這就是基本的多重繼承語法,但多重繼承很容易導致代碼混亂,所以當你不確定是否真的必須使用多重繼承的時候,請盡量避免使用它,因為有些時候會出現不可預見的BUG。
前面學習了繼承的概念,又提到了多重繼承,但如果現在我們有了烏龜類、魚類,現在要求定義一個類,叫水池,水池里要有烏龜和魚。用多重繼承就顯得很奇怪,因為水池和烏龜、魚是不同物種,那怎樣把它們組合成一個水池的類呢?
其實在Python中很簡單,直接把需要的類放進去實例化就可以了,這就叫組合:

先運行上段代碼,然后測試:

Python的對象有許多神奇的方法,如果你的對象實現了這些方法中的某一個,那么這個方法就會在特殊情況下被Python所調用,而這一切都是自動發生的。
通常把_ _init_ _()方法稱為構造方法,只要實例化一個對象,這個方法就會在對象被創建時自動調用。實例化對象時是可以傳入參數的,這些參數會自動傳入_ _init_ _()方法中,可以通過重寫這個方法來自定義對象的初始化操作。
舉個例子:

有些讀者可能會問,有些時候在類定義時寫_ _init_ _()方法,有時候卻沒有,這是為什么呢?看下面這個例子:

這里需要注意的是,_ _init_ _()方法的返回值一定是None,不能是其他:

所以,一般在需要進行初始化的時候才重寫_ _init_ _()方法。所以這個_ _init_ _()方法并不是實例化對象時第一個被調用的方法。
_ _new_ _()方法才是一個對象實例化的時候所調用的第一個方法。與其他方法不同的是,它的第一個參數不是self而是這個類(cls),而其他的參數會直接傳遞給_ _init_ _()方法的。
_ _new_ _()方法需要返回一個實例對象,通常是cls這個類實例化的對象,當然你也可以返回其他對象。
_ _new_ _()方法平時很少去重寫它,一般讓Python用默認的方案執行即可。但是有一種情況需要重寫這個方法,就是當繼承一個不可變的類型的時候,它的特性就顯得尤為重要了。

如果說_ _init_ _()和_ _new_ _()方法是對象的構造器的話,那么Python也提供了一個析構器,叫作_ _del_ _()方法。當對象將要被銷毀的時候,這個方法就會被調用。但是需要注意的是,并非 del x 就相當于自動調用 x._ _del_ _(),_ _del_ _()方法是當垃圾回收機制回收這個對象的時候調用的。 舉個例子:

前面提到過綁定的概念,那到底什么是綁定呢?Python中嚴格要求了方法需要有實例才能被調用,這種限制其實就是Python所謂的綁定概念。
有人可能會這么嘗試,而且發現也可以調用:

但是,這樣做會有一個問題,就是根據類實例化后的對象根本無法調用里面的函數:

實際上是由于Python的綁定機制,這里自動把bb對象作為第一個參數傳入,所以才會出現TypeError。
再看一個例子:

_ _dict_ _屬性是由一個字典組成,字典中僅有實例對象的屬性,不顯示類屬性和特殊屬性,鍵表示的是屬性名,值表示屬性相應的數據值。

現在實例對象dd有了兩個新屬性,而且這兩個屬性是僅屬于實例對象的:

為什么會這樣?其實這完全歸功于self參數:當實例對象dd去調用setXY方法的時候,它傳入的第一個參數就是dd,那么self.x = 4, self.y = 5也就相當于dd.x = 4, dd.y = 5,所以在實例對象,甚至類對象中都看不到x和y,是因為這兩個屬性是只屬于實例對象dd的。
如果把類實例刪掉,實例對象dd還能否調用printXY方法?答案是可以的:

關于“Python類和對象如何應用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python類和對象如何應用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





