溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么使用Python的pandas庫創建多層次索引”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
pd.MultiIndex,即具有多個層次的索引。通過多層次索引,我們就可以操作整個索引組的數據。本文主要介紹在Pandas中創建多層索引的6種方式:
pd.MultiIndex.from_arrays():多維數組作為參數,高維指定高層索引,低維指定低層索引。
pd.MultiIndex.from_tuples():元組的列表作為參數,每個元組指定每個索引(高維和低維索引)。
pd.MultiIndex.from_product():一個可迭代對象的列表作為參數,根據多個可迭代對象元素的笛卡爾積(元素間的兩兩組合)進行創建索引。
pd.MultiIndex.from_frame:根據現有的數據框來直接生成
groupby():通過數據分組統計得到
pivot_table():生成透視表的方式來得到
In [1]:
import pandas as pd import numpy as np
通過數組的方式來生成,通常指定的是列表中的元素:
In [2]:
# 列表元素是字符串和數字 array1 = [["xiaoming","guanyu","zhangfei"], [22,25,27] ] m1 = pd.MultiIndex.from_arrays(array1) m1
Out[2]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [3]:
type(m1) # 查看數據類型
通過type函數來查看數據類型,發現的確是:MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
在創建的同時可以指定每個層級的名字:
In [4]:
# 列表元素全是字符串 array2 = [["xiaoming","guanyu","zhangfei"], ["male","male","female"] ] m2 = pd.MultiIndex.from_arrays( array2, # 指定姓名和性別 names=["name","sex"]) m2
Out[4]:
MultiIndex([('xiaoming', 'male'), ( 'guanyu', 'male'), ('zhangfei', 'female')],
names=['name', 'sex'])下面的例子是生成3個層次的索引且指定名字:
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"], ["male","male","female"], [22,25,27] ] m3 = pd.MultiIndex.from_arrays( array3, names=["姓名","性別","年齡"]) m3
Out[5]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
names=['姓名', '性別', '年齡'])通過元組的形式來生成多層索引:
In [6]:
# 元組的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4Out[6]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [7]:
# 元組構成的3層索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5Out[7]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
)最外層是列表
里面全部是元組
In [8]:
array6 = [("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(18,35,27)
]
# 指定名字
m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性別","年齡"])
m6Out[8]:
MultiIndex([('xiaoming', 'male', 18), ( 'guanyu', 'male', 35), ('zhangfei', 'female', 27)],
names=['姓名', '性別', '年齡'] # 指定名字
)使用可迭代對象的列表作為參數,根據多個可迭代對象元素的笛卡爾積(元素間的兩兩組合)進行創建索引。
在Python中,我們使用 isinstance()函數 判斷python對象是否可迭代:
# 導入 collections 模塊的 Iterable 對比對象 from collections import Iterable


通過上面的例子我們總結:常見的字符串、列表、集合、元組、字典都是可迭代對象
下面舉例子來說明:
In [18]:
names = ["xiaoming","guanyu","zhangfei"] numbers = [22,25] m7 = pd.MultiIndex.from_product( [names, numbers], names=["name","number"]) # 指定名字 m7
Out[18]:
MultiIndex([('xiaoming', 22), ('xiaoming', 25), ( 'guanyu', 22), ( 'guanyu', 25), ('zhangfei', 22), ('zhangfei', 25)],
names=['name', 'number'])In [19]:
# 需要展開成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8Out[19]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [20]:
# 使用元組形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9Out[20]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [21]:
# 使用range函數
strings = ("a","b","c") # 3個元素
lists = range(3) # 0,1,2 3個元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10Out[21]:
MultiIndex([('a', 0), ('a', 1), ('a', 2), ('b', 0), ('b', 1), ('b', 2), ('c', 0), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [22]:
# 使用range函數
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 總個數 3*3*2=18總個數是``332=18`個:
Out[22]:
MultiIndex([('a', 0, 'x'), ('a', 0, 'y'), ('a', 1, 'x'), ('a', 1, 'y'), ('a', 2, 'x'), ('a', 2, 'y'), ('b', 0, 'x'), ('b', 0, 'y'), ('b', 1, 'x'), ('b', 1, 'y'), ('b', 2, 'x'), ('b', 2, 'y'), ('c', 0, 'x'), ('c', 0, 'y'), ('c', 1, 'x'), ('c', 1, 'y'), ('c', 2, 'x'), ('c', 2, 'y')],
names=['name', 'l1', 'l2'])通過現有的DataFrame直接來生成多層索引:
df = pd.DataFrame({"name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"]})
df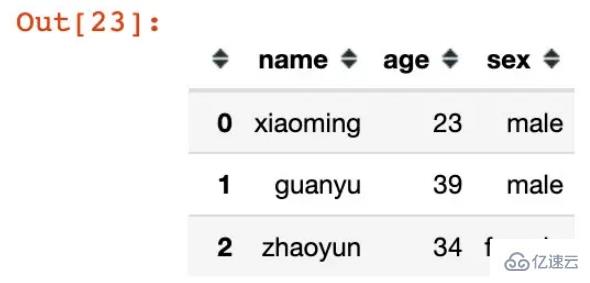
直接生成了多層索引,名字就是現有數據框的列字段:
In [24]:
pd.MultiIndex.from_frame(df)
Out[24]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])通過names參數來指定名字:
In [25]:
# 可以自定義名字 pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
Out[25]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])通過groupby函數的分組功能計算得到:
In [26]:
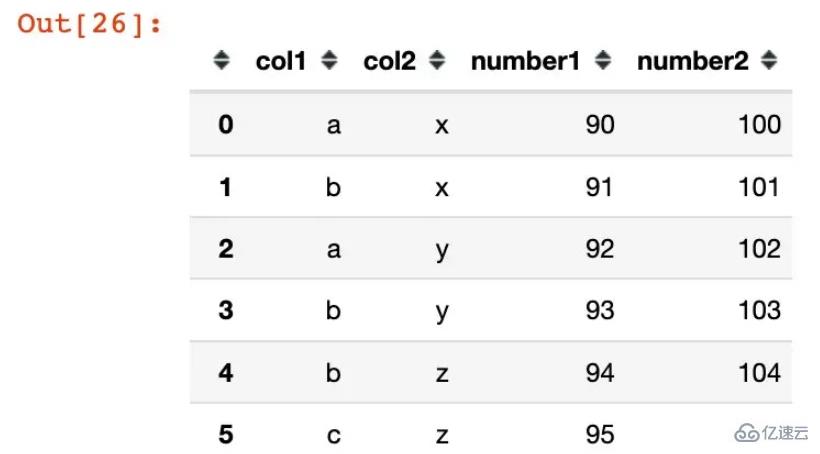
df1 = pd.DataFrame({"col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106)})
df1Out[26]:
df2 = df1.groupby(["col1","col2"]).agg({"number1":sum,
"number2":np.mean})
df2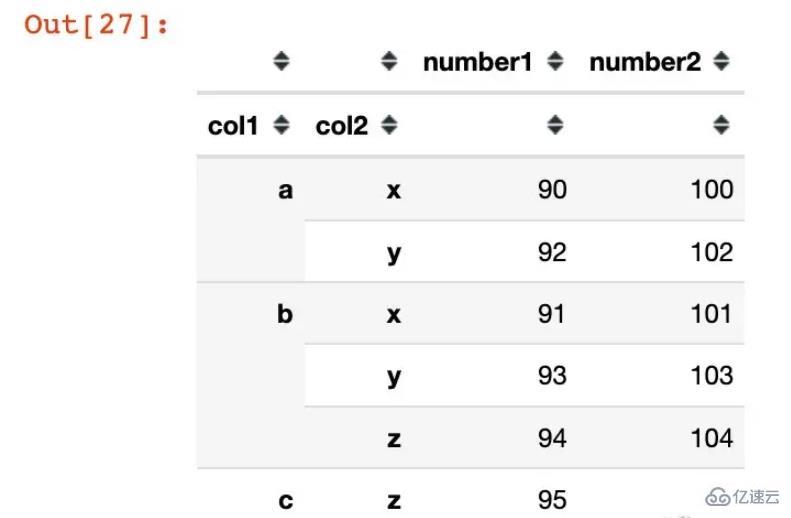
查看數據的索引:
In [28]:
df2.index
Out[28]:
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])通過數據透視功能得到:
In [29]:
df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"]) df3

In [30]:
df3.index
Out[30]:
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])“怎么使用Python的pandas庫創建多層次索引”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





