溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“MySQL Join使用原理是什么”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“MySQL Join使用原理是什么”文章吧。
left join,以左表為驅動表,以左表作為結果集基礎,連接右表的數據補齊到結果集中
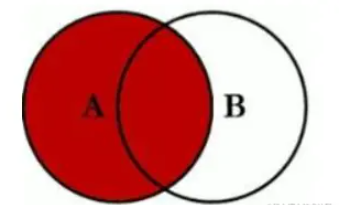
right join,以右表為驅動表,以右表作為結果集基礎,連接左表的數據補齊到結果集中
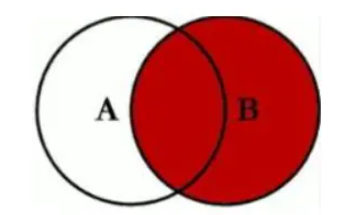
inner join,結果集取兩個表的交集
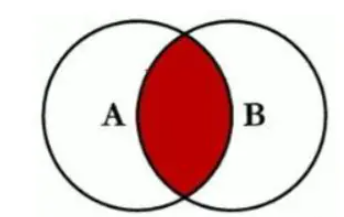
full join,結果集取兩個表的并集
mysql沒有full join,union取代
union與union all的區別為,union會去重
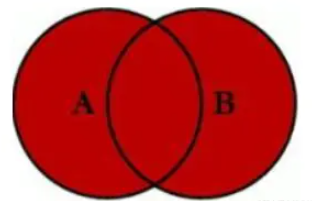
cross join 笛卡爾積
如果不使用where條件則結果集為兩個關聯表行的乘積
與,的區別為,cross join建立結果集時會根據on條件過濾結果集合
straight_join
嚴格根據SQL順序指定驅動表,左表是驅動
本質上可以理解為嵌套循環的操作,驅動表作為外層for循環,被驅動表作為內層for循環。根據連接組成數據的策略可以分為三種算法。
連接比如有A表,B表,兩個表JOIN的話會拿著A表的連表條件一條一條在B表循環,匹配A表和B表相同的id 放入結果集,這種效率是最低的。
執行流程(磁盤掃描)
從表t1中讀入一行數據 R;
從數據行R中,取出a字段到表t2里進行樹搜索查找;
取出表t2中滿足條件的行,跟R組成一行,作為結果集的一部分;
重復執行步驟1到3,直到表t1的末尾循環結束。
而對于每一行R,根據a字段去表t2查找,走的是樹搜索過程。
mysql使用了一個叫join buffer的緩沖區去減少循環次數,這個緩沖區默認是256KB,可以通過命令show variables like 'join_%'查看
其具體的做法是,將第一表中符合條件的列一次性查詢到緩沖區中,然后遍歷一次第二個表,并逐一和緩沖區的所有值比較,將比較結果加入結果集中
只有當JOIN類型為ALL,index,rang或者是index_merge的時候才會使用join buffer,可以通過explain查看SQL的查詢類型。
為了優化join算法采用Index nested-loop join算法,在連接字段上建立索引字段
使用數據量小的表去驅動數據量大的表
增大join buffer size的大小(一次緩存的數據越多,那么外層表循環的次數就越少)
注意連接字段的隱式轉換與字符編碼,避免索引失效
以上就是關于“MySQL Join使用原理是什么”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





