溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Python怎么調用實現最小二乘法”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Python怎么調用實現最小二乘法”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
所謂線性最小二乘法,可以理解為是解方程的延續,區別在于,當未知量遠小于方程數的時候,將得到一個無解的問題。最小二乘法的實質,是保證誤差最小的情況下對未知數進行賦值。
最小二乘法是非常經典的算法,而且這個名字我們在高中的時候就已經接觸了,屬于極其常用的算法。此前曾經寫過線性最小二乘法的原理,并用Python實現:最小二乘法及其Python實現;以及scipy中非線性最小二乘法的調用方式:非線性最小二乘法(文末補充內容);還有稀疏矩陣的最小二乘法:稀疏矩陣最小二乘法。
下面講對numpy和scipy中實現的線性最小二乘法進行說明,并比較二者的速度。
numpy中便實現了最小二乘法,即lstsq(a,b)用于求解類似于a@x=b中的x,其中,a為M×N的矩陣;則當b為M行的向量時,剛好相當于求解線性方程組。對于Ax=b這樣的方程組,如果A是滿秩仿真,那么可以表示為x=A−1b,否則可以表示為x=(ATA)−1ATb。
當b為M×K的矩陣時,則對每一列,都會計算一組x。
其返回值共有4個,分別是擬合得到的x、擬合誤差、矩陣a的秩、以及矩陣a的單值形式。
import numpy as np np.random.seed(42) M = np.random.rand(4,4) x = np.arange(4) y = M@x xhat = np.linalg.lstsq(M,y) print(xhat[0]) #[0. 1. 2. 3.]
scipy.linalg同樣提供了最小二乘法函數,函數名同樣是lstsq,其參數列表為
lstsq(a, b, cond=None, overwrite_a=False, overwrite_b=False, check_finite=True, lapack_driver=None)
其中a, b即Ax=b,二者均提供可覆寫開關,設為True可以節省運行時間,此外,函數也支持有限性檢查,這是linalg中許多函數都具備的選項。其返回值與numpy中的最小二乘函數相同。
cond為浮點型參數,表示奇異值閾值,當奇異值小于cond時將舍棄。
lapack_driver為字符串選項,表示選用何種LAPACK中的算法引擎,可選'gelsd', 'gelsy', 'gelss'。
import scipy.linalg as sl xhat1 = sl.lstsq(M, y) print(xhat1[0]) # [0. 1. 2. 3.]
最后,對著兩組最小二乘函數做一個速度上的對比
from timeit import timeit N = 100 A = np.random.rand(N,N) b = np.arange(N) timeit(lambda:np.linalg.lstsq(A, b), number=10) # 0.015487500000745058 timeit(lambda:sl.lstsq(A, b), number=10) # 0.011151800004881807
這一次,二者并沒有拉開太大的差距,即使將矩陣維度放大到500,二者也是半斤八兩。
N = 500 A = np.random.rand(N,N) b = np.arange(N) timeit(lambda:np.linalg.lstsq(A, b), number=10) 0.389679799991427 timeit(lambda:sl.lstsq(A, b), number=10) 0.35642060000100173
Python調用非線性最小二乘法
簡介與構造函數
在scipy中,非線性最小二乘法的目的是找到一組函數,使得誤差函數的平方和最小,可以表示為如下公式
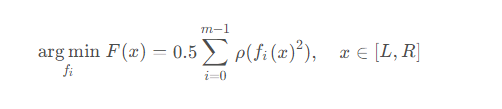
其中ρ表示損失函數,可以理解為對fi(x)的一次預處理。
scipy.optimize中封裝了非線性最小二乘法函數least_squares,其定義為
least_squares(fun, x0, jac, bounds, method, ftol, xtol, gtol, x_scale, f_scale, loss, jac_sparsity, max_nfev, verbose, args, kwargs)
其中,func和x0為必選參數,func為待求解函數,x0為函數輸入的初值,這兩者無默認值,為必須輸入的參數。
bound為求解區間,默認(−∞,∞),verbose為1時,會有終止輸出,為2時會print更多的運算過程中的信息。此外下面幾個參數用于控制誤差,比較簡單。
| 默認值 | 備注 | |
|---|---|---|
| ftol | 10-8 | 函數容忍度 |
| xtol | 10-8 | 自變量容忍度 |
| gtol | 10-8 | 梯度容忍度 |
| x_scale | 1.0 | 變量的特征尺度 |
| f_scale | 1.0 | 殘差邊際值 |
loss為損失函數,就是上面公式中的ρ \rhoρ,默認為linear,可選值包括

迭代策略
上面的公式僅給出了算法的目的,但并未暴露其細節。關于如何找到最小值,則需要確定搜索最小值的方法,method為最小值搜索的方案,共有三種選項,默認為trf
trf:即Trust Region Reflective,信賴域反射算法
dogbox:信賴域狗腿算法
lm:Levenberg-Marquardt算法
這三種方法都是信賴域方法的延申,信賴域的優化思想其實就是從單點的迭代變成了區間的迭代,由于本文的目的是介紹scipy中所封裝好的非線性最小二乘函數,故而僅對其原理做簡略的介紹。

其中r為置信半徑,假設在這個鄰域內,目標函數可以近似為線性或二次函數,則可通過二次模型得到區間中的極小值點sk。然后以這個極小值點為中心,繼續優化信賴域所對應的區間。

以上就是信賴域方法的基本原理。
雅可比矩陣
在了解了信賴域方法之后,就會明白雅可比矩陣在數值求解時的重要作用,而如何計算雅可比矩陣,則是接下來需要考慮的問題。jac參數為計算雅可比矩陣的方法,主要提供了三種方案,分別是基于兩點的2-point;基于三點的3-point;以及基于復數步長的cs。一般來說,三點的精度高于兩點,但速度也慢一倍。
此外,可以輸入自定義函數來計算雅可比矩陣。
測試
最后,測試一下非線性最小二乘法
import numpy as np
from scipy.optimize import least_squares
def test(xs):
_sum = 0.0
for i in range(len(xs)):
_sum = _sum + (1-np.cos((xs[i]*i)/5)*(i+1))
return _sum
x0 = np.random.rand(5)
ret = least_squares(test, x0)
msg = f"最小值" + ", ".join([f"{x:.4f}" for x in ret.x])
msg += f"\nf(x)={ret.fun[0]:.4f}"
print(msg)
'''
最小值0.9557, 0.5371, 1.5714, 1.6931, 5.2294
f(x)=0.0000
'''讀到這里,這篇“Python怎么調用實現最小二乘法”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





