溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下go map搬遷怎么實現的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
以下代碼基于go1.17
桶用太多
go用了一個負載因子loadFactor來衡量。也就是如果數量count大于loadFactor * bucket數,那么就要擴容
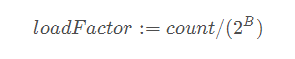
代碼如下
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
)
// 在元素數量大于8且元素數量大于負載因子(6.5)*桶總數,就要進行擴容
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}overflow太多
overflow太多在go中分兩種情況
bucket數量小于1<<15時,overflow超過桶總數
bucket數量大于1<<15時,overflow超過1<<15
// overflow buckets 太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}準備搬遷工作是由hashGrow方法完成的,他主要就是進行申請新buckets空間、初始化搬遷進度為0、將原桶標記為舊桶等
func hashGrow(t *maptype, h *hmap) {
// 判斷是bucket多還是overflow多,然后根據這兩種情況去申請新buckets空間
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
// 更新最新的bucket總數、將原桶標記為舊桶(后面判斷是否在搬遷就是通過這個進行判斷的)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 初始化搬遷進度為0
h.nevacuate = 0
// 初始化新桶overflow數量為0
h.noverflow = 0
// 將原來extra的overflow掛載到old overflow,代表這已經是舊的了
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
// extra指向下一塊空閑的overflow空間
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}正式搬遷其實是在添加、刪除元素的時候順便干的。在發現搬遷的時候,就可能會做一到兩次的搬遷,每次搬遷一個bucket。具體是一次還是兩次就是下面的邏輯決定的
搬遷正在使用的bucket對應old bucket(如果沒有搬遷過的話)
若還正在搬遷就再搬一個以加快搬遷
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}對于不擴容的情況,可能只有一個——就是原來序號對應的桶(就是下面的x)。
對于擴容2倍的情況,顯然既有可能是在原來序號對應桶,也有可能是原來序號加上擴容的桶數的序號
比如B由2變成了3,那么就要看hash第3bit到底是0還是1了,如果是001,那么和原來的一樣,是序號為1的桶;如果是101,那么就是原來序號1+22 (擴容桶數)=序號為5的桶
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
// newBit在擴容的情況下等于1<<(B-1)
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}每一個bucket在溢出之后都會附接overflow桶,每個bucket包括overflow儲存著8個元素
若元素tophash為空,則表示被搬遷過,繼續下一個
計算hash值
若超出當前bucket容量,就新建一個overflow bucket
將原來的key、value復制到新bucket新位置
定位到下一個元素
在上面的步驟計算hash值在overflow用太多的情況下是不用的
此外,在桶用太多的情況下,計算hash
for ; b != nil; b = b.overflow(t) {
// 找到key開始位置k,和value開始位置e
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
// 遍歷bucket中元素進行搬遷
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
// 獲取tophash,若發現是空,說明已經搬遷過。并標記為空且已搬遷
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
// 若key為引用類型就解引用
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
// X指的就是原序號桶
// Y指的就是擴容情況下,新的最高位為1的時候應該去的桶
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
// 若正在迭代,且key為NaNs。是不是使用Y就取決最低位是不是1了
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// 如果最高位為1,那么就應該選Y桶
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 標記X還是Y搬遷,并依此獲取到搬遷目標桶
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
// 若目標桶已經超出桶容量,就分配新overflow
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 更新元素目標桶對應的tophash
// 采用與而非取模,應該是出于性能目的
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// 復制key到目標桶
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
// 復制value到目標桶
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 更新目標桶元素數量、key、value位置
dst.i++
// These updates might push these pointers past the end of the key or elem arrays.
// That's ok, as we have the overflow pointer at the end of the bucket to protect against pointing past the end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}如果發現沒有在使用舊buckets的就把原buckets中的key-value清理掉吧(tophash還是保留用來搬遷時判斷狀態)
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
// 計算當前原bucket所在的開始位置b
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
// 從開始位置加上key-value的偏移量,那么ptr所在的位置就是實際key-value的開始位置
ptr := add(b, dataOffset)
// n是總bucket大小減去key-value的偏移量,就key-value占用空間的大小
n := uintptr(t.bucketsize) - dataOffset
// 清理從ptr開始的n個字節
memclrHasPointers(ptr, n)
}在本次搬遷進度是最新進度的情況下(不是最新就讓最新的去干吧)
更新進度
嘗試往后看1024個bucket,如果發現有搬遷完的,但是沒更新進度就順便幫別人更新了
若是全部bucket都完成搬遷了,那就直接將原buckets釋放掉
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
// 更新進度
h.nevacuate++
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// 向后看,更新已經完成的進度
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 若是完成搬遷,就釋放掉old buckets、重置搬遷狀態、釋放原bucket掛載到extra的overflow指針
if h.nevacuate == newbit { // newbit == # of oldbuckets
// Growing is all done. Free old main bucket array.
h.oldbuckets = nil
// Can discard old overflow buckets as well.
// If they are still referenced by an iterator,
// then the iterator holds a pointers to the slice.
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}以上就是“go map搬遷怎么實現”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





