溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Python基于pywinauto怎么實現自動化采集任務”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Python基于pywinauto怎么實現自動化采集任務”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
這個程序使用了一個 Python 的自動化庫 ---- pywinauto, 因為官方已經很久沒更新了, 所以 python 的版本最高只能是 Python 3.7 左右, 我用的是 Python 3.7.1. 我使用它模擬了輸入單詞, 復制例句, 獲取例句, 清空剪切板, 然后重復這個操作, 總體上實現比較簡陋. 而且, 為了簡單, 我是之間手動切換到例句頁, 這樣就不用使用程序來切換到例句頁了.
requirements.txt
pyperclip==1.8.2 pywin32==304 pywinauto==0.6.8
代碼
import os
import random
import time
import re
from typing import Dict, List
from pywinauto.application import Application
from pywinauto import mouse
from pywinauto import keyboard
import pyperclip
import json
# 程序處理中的各種路徑
dir_path = r"C:/Users/Dick/Desktop/work/DragonEnglish/tools"
input_path = os.path.join(dir_path, r"input.txt")
output_path = os.path.join(dir_path, r"output.json")
error_path = os.path.join(dir_path, r"error.txt")
# 順序錯誤的單詞
error_words = []
# 有道詞典的進程id
processId = 13840
def line_process(content: str) -> str:
"""
去除所有空行, 再去除前面四行無關內容
"""
lines = content.split("\r\n")
# 因為例句開頭是 數字. 開頭的, 所以先以這個為特點來進行過濾掉多復制的開頭
count = 0
for i in range(len(lines)):
if re.match(r"\d+\.", lines[i]):
count = i
break
lines = lines[count:]
filter_lines = []
for line in lines:
if line.strip() != "": # 過濾空行
if not line.startswith("youdao") and not \
(line.startswith("《") and line.endswith("》")): # 過濾來源
filter_lines.append(line)
if len(filter_lines) % 3 != 0:
raise Exception("抓取數據錯誤")
content = "\n".join(filter_lines) + "\n" # 補上一個 \n, 不然正則會漏掉一個結果
return content
def to_list(line: str) -> List[Dict[str, str]]:
"""
直接生成列表字典對象
[{
"no": 1,
"original": "",
"translate"
}]
"""
sentences = []
# 正則表達式
REGEXP = r'(?P<no>\d+?)\.\n(?P<original>.+?)\n(?P<translate>.+?)\n'
# 編譯
pattern = re.compile(REGEXP)
# 匹配
rs = pattern.finditer(line)
# 組裝結果
for r in rs:
print(r.groupdict())
sentences.append(r.groupdict())
return sentences
if __name__ == "__main__":
# 連接網易有道詞典
app = Application(backend="uia").connect(process=processId)
# 獲取需要的窗口
win = app.window(class_name="RICHEDIT50W")
# 輸入詞匯列表
input_words = []
# 輸出詞匯對象列表
output_words = []
# 打開輸入文件,初始化輸入詞匯列表
with open(input_path, "r", encoding="utf-8") as input_file:
input_words = input_file.read().split("\n")
for word in input_words:
print("正在抓取單詞: %s" % word)
# 清空剪切板,這步很重要,防止重復復制
pyperclip.copy("")
# 將輸入數據復制到剪切板
pyperclip.copy(word)
# 定位到輸入框(采用坐標定位,定位到大致位置即可)
mouse.click(coords=(2400, 80))
# 模擬按鍵操作:全選 刪除 粘貼 回車(觸發查詢)
keyboard.send_keys("^a{DELETE}^v{ENTER}")
# 清空剪切板,這步很重要,防止重復復制
pyperclip.copy("")
# 鼠標左鍵點擊,這個操作只是為了把鼠標移動到這里
mouse.click(button="left", coords=(2200, 330))
# 模擬鍵盤 CTRL+A CTRL+C,直接全選所有的例句(這里會多選一部分內容,待會再處理)
keyboard.send_keys("^a^c")
# 暫停一會兒,不做操作的太快
time.sleep(random.random() * 2 + 1)
# pywinauto 復制的內容是在系統的剪切板里面的,所以需要其它庫讀取
content = pyperclip.paste()
# 對內容進行簡單的預處理后,加入output_words
try:
lines = line_process(content)
except BaseException as exp:
print(exp)
# 如果抓取出現問題,說明被網易抓了現行,直接退出即可。
break
sentences = to_list(lines)
if not sentences:
print("獲取例句為空, 可能是數據格式錯誤.")
break
output_words.append({
"word": word,
"example": sentences,
})
# 模擬暫停一個較長的隨機時間,沒有必要追求速度,平穩運行即可。
time.sleep(random.random() * 3 + 3)
# 清空剪切板,這步很重要,防止重復復制
pyperclip.copy("")
# 抓取完畢一個文件的內容后,然后一次性寫入即可。
# 之前的寫法是一個單詞寫入一次,會造成太多的IO次數,浪費性能!
with open(output_path, "a+", encoding="utf-8") as output_file:
output_file.write(json.dumps(
output_words, ensure_ascii=False, indent=4))
# 錯誤單詞記錄
with open(error_path, "w", encoding="utf-8") as err_file:
err_file.writelines("\n".join(error_words))演示 如果想要啟動這個代碼, 還是蠻復雜的. 我這里直接把需要的步驟羅列一下, 希望能幫助感興趣的同學.
修改dir_path, 并且在下面準備一個 input.txt 文件.
獲取有道詞典進程的 id.
獲取單詞輸入框的坐標, 獲取復制粘貼處的坐標.
將有道詞典界面調整到例句處.
啟動項目, 需要一個 input.txt 文件, 這里是我測試的文件.
sophisticated
centralization
phenomenon
internationalization
radioactive
我是通過任務管理器獲取的進程 pid, 你也可以通過其它訪問. 或者最簡單的是使用 Inspect 和 Spy++, 我這里就偷懶了, 直接怎么省事怎么來了.
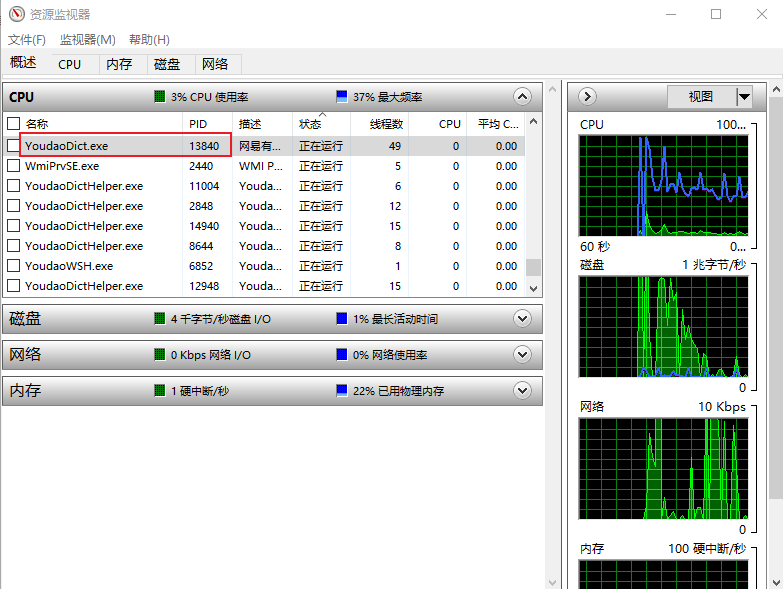
單詞輸入框的坐標, 復制粘貼處的坐標. 第一個坐標是為了定位輸入框的, 然后程序會把單詞復制進去, 并執行一下回車鍵, 然后內容被查詢出來. 再將鼠標移動到第二個坐標處, 這里只是移動到下面的空白處就行了, 然后會執行一個全選 CTRL+A 操作. 這樣一個單詞的內容就全部獲取到了.
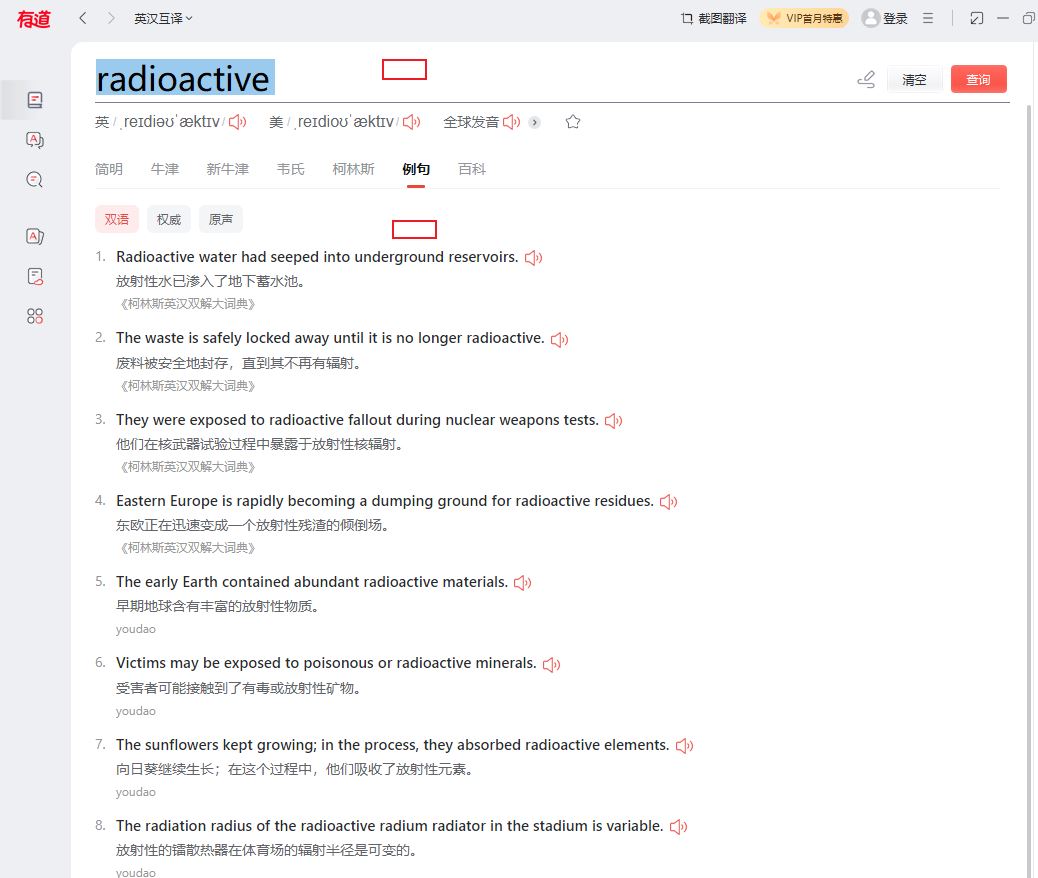
將有道調整到這個位置, 首選查詢一個單詞, 選擇例句, 然后保持這個界面不要動即可.
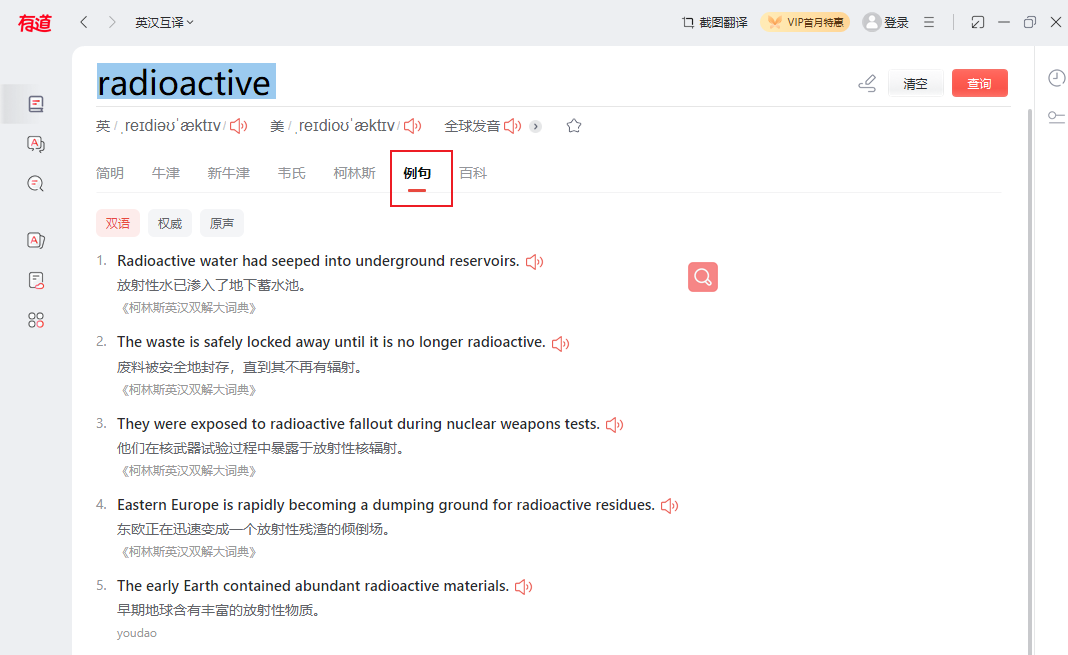
最后就是程序的執行了, 錄制的 GIF 做了加速處理, 實際上執行的時候, 是特意加了延時的, 防止被過早的發現了.
控制臺輸出
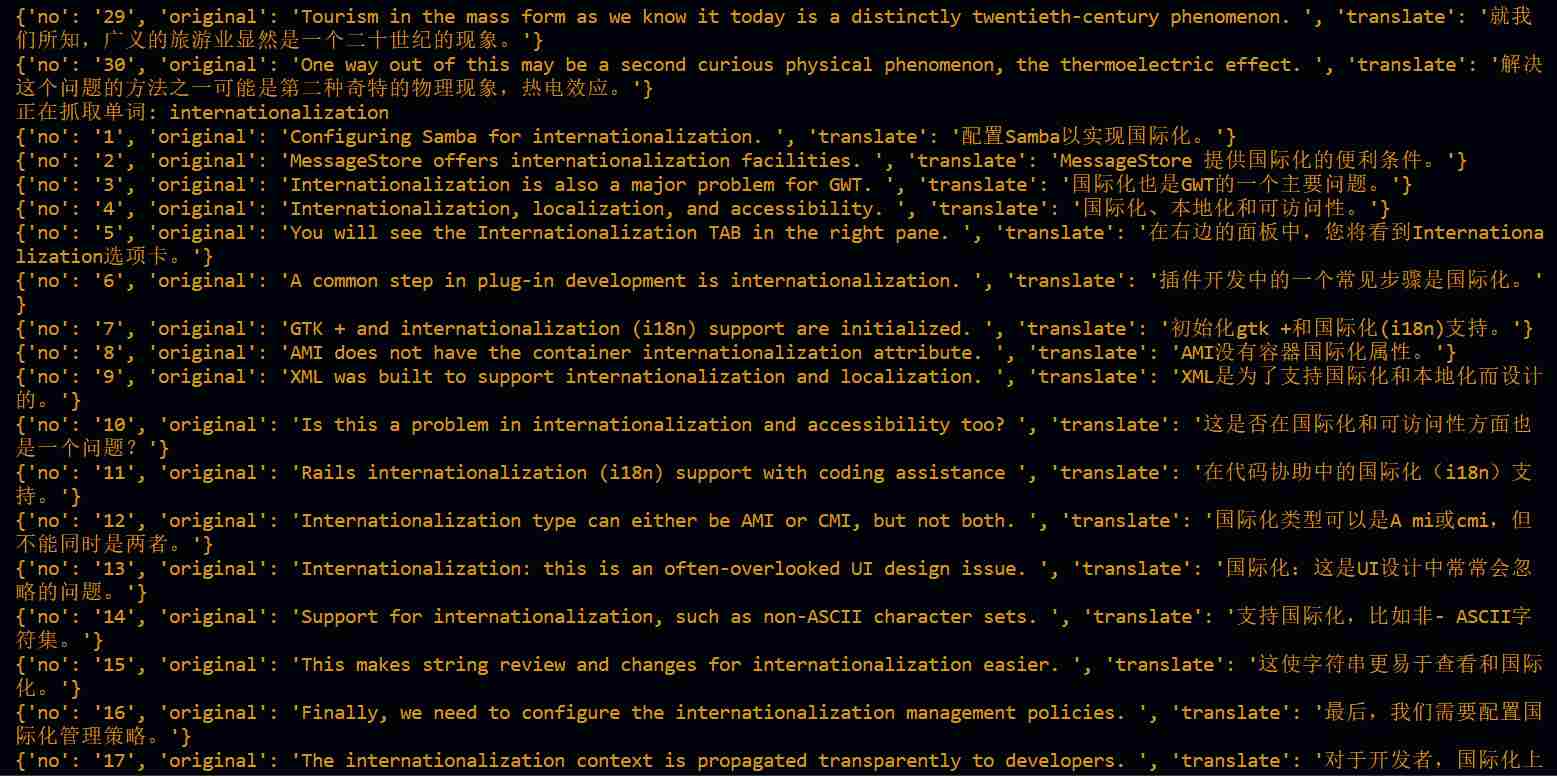
output.json 文件
讀到這里,這篇“Python基于pywinauto怎么實現自動化采集任務”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





