溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python drop()刪除行列的操作方法有哪些”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Python drop()刪除行列的操作方法有哪些”文章能幫助大家解決問題。
在進行特征工程、劃分數據集的工作中,drop()函數都能派上用場。它可以輕松剔除數據、操作列和操作行等。
drop()詳細的語法如下:
刪除行是index,刪除列是columns:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
參數:
labels:要刪除的行或列的標簽,可以是單個標簽,也可以是標簽列表。
axis:要刪除的行或列的軸,0表示行,1表示列。
index:要刪除的行的索引,可以是單個索引,也可以是索引列表。
columns:要刪除的列的列名,可以是單個列名,也可以是列名列表。
inplace:是否在原DataFrame上進行操作,默認為False,即不在原DataFrame上進行操作。
使用場景1:刪除不需要的特征。
例如:有些特征對結果的影響不大,就可以把與因變量不相關的自變量刪掉;為了避免多重共線性,要把有強相關關系的自變量刪掉。
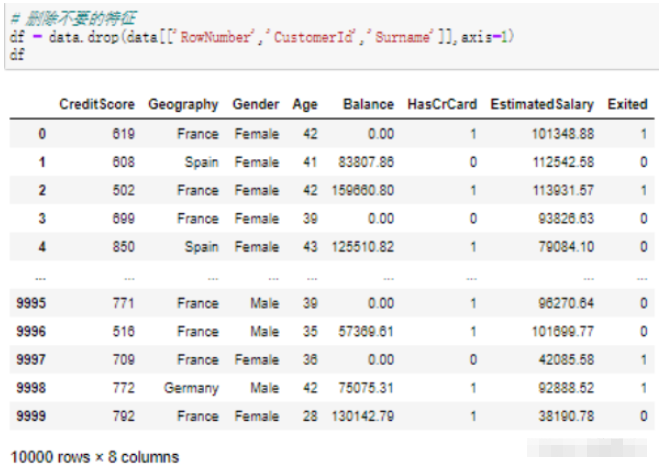
df = data.drop(data[['RowNumber','CustomerId','Surname']],axis=1) df
代碼講解:
data是數據集,兩個中括號代表DataFrame格式,里面篩選了3個要刪除的字段;
axis=1代表操作列;
運行結果:
使用場景2:把因變量刪掉
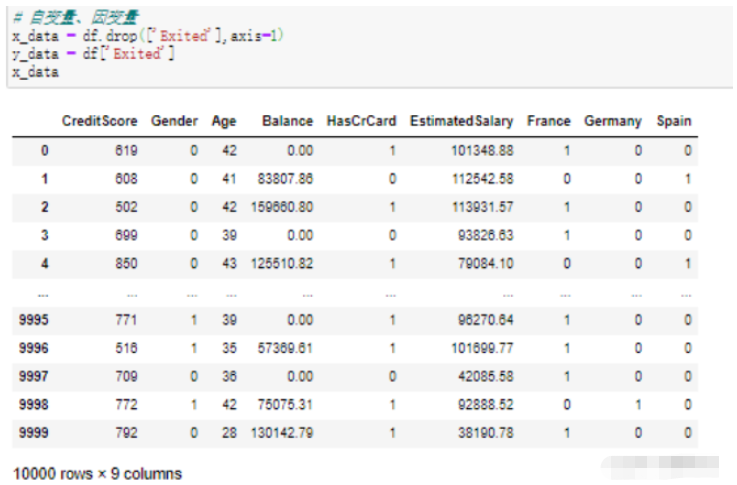
# 自變量、因變量 x_data = df.drop(['Exited'],axis=1) y_data = df['Exited'] x_data
代碼講解:
drop()函數里面填寫要刪除的字段,表示從df中刪除名為“Exited”的列;
['Exited']這一個字段是我們要剔除的因變量,單個字段可以這樣表示;
運行結果:
使用場景3:在劃分數據集的時候,生成了訓練集,把被分到訓練集的樣本剔除掉,剩下的就是測試集了。
#劃分訓練集 train_data = data.sample(frac = 0.8, random_state = 0) #測試集 test_data = data.drop(train_data.index)
代碼講解:
drop()函數里面填行索引可以刪除掉行;
train_data是我們劃分好的訓練集,train_data.index表示行索引;
axis=0,表示的是刪除行,也可以不寫,是默認值;
關于“Python drop()刪除行列的操作方法有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





