溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“C語言volatile關鍵字的作用是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
版本信息:Linux操作系統,x86架構,Linux操作系統下GCC9.3.1版本。GCC 9.3.0手冊。
先看一下GCC文檔給的volatile說明:

一言以蔽之:讓編譯器不再去優化被volatile修飾的變量的操作。但是volatile并不能做內存屏障的功能,想使用內存屏障請使用平臺相關的屏障指令,比如GCC提供了一個內聯asm volatile ("" : : : "memory");的編譯器屏障。詳情平臺相關的內存屏障請關注特定平臺的操作手冊~!
既然上述說明了volatile關鍵字可以避免編譯器優化,那么下面筆者用2個列子來說明一下。
// 沒優化: int a = 10; int b = a; int c = a; int d = a; // 對應的匯編代碼 sub 16,esp // 開辟棧幀 mov $10,(esp-12) // 把立即數10放入到esp-12的棧幀位置,這也對應a變量。 mov (esp-12) (esp-8) // 把(esp-12)的值放入到(esp-8)的位置,這也對應b變量 mov (esp-12) (esp-4) // 把(esp-12)的值放入到(esp-4)的位置,這也對應c變量 mov (esp-12) (esp) // 把(esp-12)的值放入到(esp)的位置,這也對應d變量 // 總結,每次從內存中拿
比如這個很簡單的列子,定義一個變量a,然后把a賦值給b、c、d。
看匯編代碼,可以清楚的看到,每次賦值都是從內存地址中拿去值,這也就需要訪問多次內存。影響到代碼的執行效率。那么,編譯器會如何優化呢?
既然b、c、d都使用的a變量,而A變量為10,那么可不可以這樣寫呢?
// 優化: int a = 10; int b = 10; int c = 10; int d = 10; // 對應的匯編代碼: sub 16,esp // 開辟棧幀 mov $10,(esp-12) // 把立即數10放入到esp-12的棧幀位置,這也對應a變量。 mov (esp-12),eax // 把esp-12的棧幀位置對應的值,也就是10放入到eax寄存器中。 mov eax (esp-8) // 把eax寄存器的值放入到(esp-8)的位置,這也對應b變量 mov eax (esp-4) // 把eax寄存器的值放入到(esp-4)的位置,這也對應c變量 mov eax (esp) // 把eax寄存器的值放入到(esp)的位置,這也對應d變量 // 總結,每次從eax寄存器拿,此時,可以把eax想成一個緩存寄存器。
可以從匯編代碼看出,把a變量的值放入到eax寄存器中,然后把eax寄存器的值賦值給b、c、d變量,這樣就只需要訪問一次內存了。此時,我們需要考慮,假如賦值b、c、d的過程中,a的值發生了改變了呢?那么對于b、c、d來說還是賦值的原值,所以就出現了問題。
這是一個很簡單的編譯器優化的例子,代碼就是假設的代碼,匯編也是偽匯編,那么,為得到讀者的認可,筆者也是寫了一個真實的案例。
// demo.c案例
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h>
#include <errno.h>
/*全局變量*/
int gnum = 1;
/*線程1的服務程序*/
static void pthread_func_1 (void)
{
while(gnum == 1){
}
}
int main (void)
{
/*線程的標識符*/
pthread_t pt_1 = 0;
int ret = 0;
/*
創建線程1
*/
ret = pthread_create( &pt_1, //線程標識符指針
NULL, //默認屬性
(void *)pthread_func_1,//運行函數
NULL); //無參數
if (ret != 0)
{
perror ("pthread_1_create");
}
/* 主線程停1秒,讓p1線程成功被CPU調度 */
sleep(1);
/* 改變全局屬性gnum的值,讓p1線程停下來。 */
gnum = 0;
/* 等待線程1的結束 */
pthread_join (pt_1, NULL);
printf ("main programme exit!/n");
return 0;
}這段代碼很簡單,使用pthread創建一個p1線程,p1線程里面寫了一個while循環,循環條件是判斷全局變量gnum是否為1。main線程啟動p1線程,同時main線程休眠1秒,讓p1線程得到CPU的調度,然后把全局變量gnum設置為0,讓p1線程的while結束。main線程使用join等待p1線程執行結束,p1線程結束后main線程打印main programme exit。
gcc普通編譯:
// gcc普通編譯后 gcc -pthread demo.c // objdump指令查看反匯編 objdump -S a.out // 反編譯后p1線程代碼段的匯編代碼 000000000040068d <pthread_func_1>: 40068d: 55 push %rbp 40068e: 48 89 e5 mov %rsp,%rbp 400691: 90 nop 400692: 8b 05 bc 09 20 00 mov 0x2009bc(%rip),%eax # 601054 <gnum> // 每次還從0x2009bc(%rip)獲取全局的gnum變量放入eax寄存器 400698: 83 f8 01 cmp $0x1,%eax // 拿1和eax寄存器做比較,比較結果放入到flags寄存器中。 40069b: 74 f5 je 400692 <pthread_func_1+0x5> // 如果比較成功就直接跳到400692這行代碼段地址,如果不成功就直接往下執行 40069d: 5d pop %rbp 40069e: c3 retq
可以清楚的看到每次都是從0x2009bc(%rip)獲取值給%eax寄存器,然后cmp做比較,je是成功就跳轉到400692代碼段地址。然后繼續mov獲取值,cmp比較,je跳轉,周而復始......
gcc -O4編譯:
// gcc -O4編譯后 gcc -O4 -pthread demo.c // objdump指令查看反匯編 objdump -S a.out // 反編譯后p1線程代碼段的匯編代碼 00000000004006f0 <pthread_func_1>: 4006f0: 83 3d 69 09 20 00 01 cmpl $0x1,0x200969(%rip) # 601060 <gnum> // 比較一次,把結果放入到flags寄存器中 4006f7: 75 07 jne 400700 <pthread_func_1+0x10> // 如果不等于就直接退出 4006f9: eb fe jmp 4006f9 <pthread_func_1+0x9> // 一直循環本行,也就是直接無腦死循環(沒有退出條件的死循環) 4006fb: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1) 400700: f3 c3 repz retq 400702: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 400709: 00 00 00 40070c: 0f 1f 40 00 nopl 0x0(%rax)
這里執行的話就直接死循環了。
這里也比較直觀,cmpl比較一次,如果不等于就jne直接返回,如果等于就執行jmp 4006f9,就開始無退出條件的死循環了,不管你后續全局變量gnum值是否改變都無條件死循環。所以這就是編譯器優化,導致的問題,那么使用volatile修飾全局變量gnum,看看效果。
volatile修飾后gcc -O4編譯:
// volatile修飾后gcc -O4編譯: gcc -O4 -pthread demo.c // objdump指令查看反匯編 objdump -S a.out // 反編譯后p1線程代碼段的匯編代碼 00000000004006f0 <pthread_func_1>: 4006f0: 8b 05 5e 09 20 00 mov 0x20095e(%rip),%eax # 601054 <gnum> // 每次從0x20095e(%rip)獲取全局的gnum變量放入eax寄存器 4006f6: 83 f8 01 cmp $0x1,%eax // 拿1和eax寄存器做比較,比較結果放入到flags寄存器中。 4006f9: 74 f5 je 4006f0 <pthread_func_1> // 如果比較成功就直接跳到4006f0這行代碼段地址,如果不成功就直接往下執行 4006fb: f3 c3 repz retq 4006fd: 0f 1f 00 nopl (%rax)
volatile 和gcc的O4優化后的代碼特別特別的精簡。可以清楚的看到mov 0x20095e(%rip),%eax每次都從0x20095e(%rip)地址獲取變量給eax寄存器,然后cmp比較,je跳轉。所以這跟普通編譯的寫法是是一樣的(單指操作被volatile修飾的變量)
內聯匯編volatile修飾后gcc -O4編譯:
int gnum = 1;
/*線程1的服務程序*/
static void pthread_func_1 (void)
{
while(gnum == 1){
__asm__ __volatile__("": : :"memory")
}
}// 使用內聯匯編volatile編譯器優化: gcc -O4 -pthread demo.c // objdump指令查看反匯編 objdump -S a.out // 反編譯后p1線程代碼段的匯編代碼 00000000004006f0 <pthread_func_1>: 4006f0: eb 06 jmp 4006f8 <pthread_func_1+0x8> 4006f2: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1) 4006f8: 83 3d 61 09 20 00 01 cmpl $0x1,0x200961(%rip) # 601060 <gnum> // 拿0x200961(%rip)全局變量gnum的值和1比較。 4006ff: 74 f7 je 4006f8 <pthread_func_1+0x8> // 如果相等就跳轉到4006f8。 400701: f3 c3 repz retq 400703: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 40070a: 00 00 00 40070d: 0f 1f 00 nopl (%rax)
這里cmpl直接比較,然后je跳轉。比較精簡。每次也是從0x200961(%rip)地址獲取最新值。所以不會出現無條件的死循環的情況。
在Linux內核中,禁止volatile關鍵字的出現,但是里面都是使用內聯匯編volatile的形式禁止編譯器優化,當然內存屏障也是可以禁止編譯器優化的(對于內存屏障這里點到即可,詳情看不同平臺的操作手冊)。當然Linux內核代碼量特別大,如果很多地方不讓編譯器優化的話,效率會降低,一個操作系統如果性能都不行,那肯定是說不過去的。
如下圖所示:使用了volatile修飾的變量在不同的代碼段之間執行都會影響到代碼段的優化,而內聯匯編volatile就可以按需選擇,就不會全部影響到。所以讀者可以按需選擇。
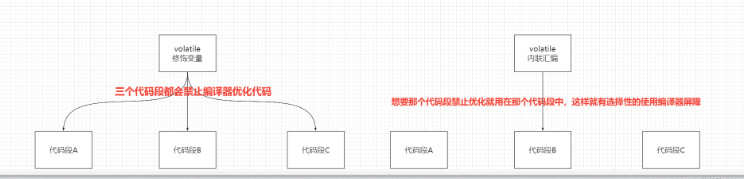
“C語言volatile關鍵字的作用是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





