溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“快速易用的Python數據可視化方法有哪些”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“快速易用的Python數據可視化方法有哪些”文章能幫助大家解決問題。
數據可視化是數據科學或機器學習項目中十分重要的一環。通常,你需要在項目初期進行探索性的數據分析(EDA),從而對數據有一定的了解,而且創建可視化確實可以使分析的任務更清晰、更容易理解,特別是對于大規模的高維數據集。在項目接近尾聲時,以一種清晰、簡潔而引人注目的方式展示最終結果也是非常重要的,讓你的受眾(通常是非技術人員的客戶)能夠理解。
熱力圖(Heat Map)是數據的一種矩陣表示方法,其中每個矩陣元素的值通過一種顏色表示。不同的顏色代表不同的值,通過矩陣的索引將需要被對比的兩項或兩個特征關聯在一起。熱力圖非常適合于展示多個特征變量之間的關系,因為你可以直接通過顏色知道該位置上的矩陣元素的大小。通過查看熱力圖中的其他點,你還可以看到每種關系與數據集中的其它關系之間的比較。顏色是如此直觀,因此它為我們提供了一種非常簡單的數據解釋方式。
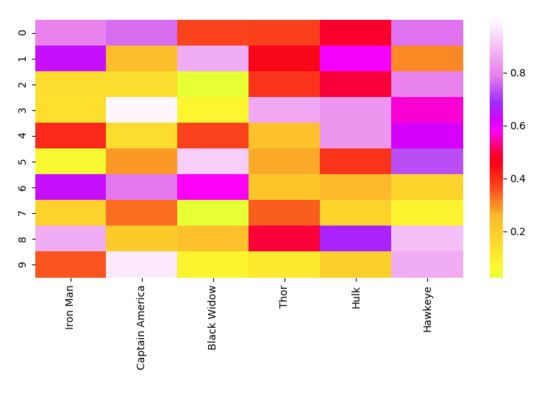
現在讓我們來看看實現代碼。與「matplotlib」相比,「seaborn」可以被用于繪制更加高級的圖形,它通常需要更多的組件,例如多種顏色、圖形或變量。「matplotlib」可以被用于顯示圖形,「NumPy」可被用于生成數據,「pandas」可以被用于處理數據!繪圖只是「seaborn」的一個簡單的功能。
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
二維密度圖(2D Density Plot)是一維版本密度圖的直觀擴展,相對于一維版本,其優點是能夠看到關于兩個變量的概率分布。例如,在下面的二維密度圖中,右邊的刻度圖用顏色表示每個點的概率。我們的數據出現概率最大的地方(也就是數據點最集中的地方),似乎在 size=0.5,speed=1.4 左右。正如你現在所知道的,二維密度圖對于迅速找出我們的數據在兩個變量的情況下最集中的區域非常有用,而不是像一維密度圖那樣只有一個變量。當你有兩個對輸出非常重要的變量,并且希望了解它們如何共同作用于輸出的分布時,用二維密度圖觀察數據是十分有效的。
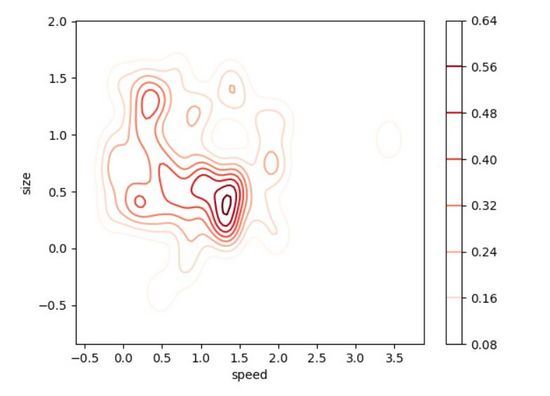
事實再次證明,使用「seaborn」編寫代碼是十分便捷的!這一次,我們將創建一個偏態分布,讓數據可視化結果更有趣。你可以對大多數可選參數進行調整,讓可視化看結果看起來更清楚。
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
蜘蛛網圖(Spider Plot)是顯示一對多關系的最佳方法之一。換而言之,你可以繪制并查看多個與某個變量或類別相關的變量的值。在蜘蛛網圖中,一個變量相對于另一個變量的顯著性是清晰而明顯的,因為在特定的方向上,覆蓋的面積和距離中心的長度變得更大。如果你想看看利用這些變量描述的幾個不同類別的對象有何不同,可以將它們并排繪制。在下面的圖表中,我們很容易比較復仇者聯盟的不同屬性,并看到他們各自的優勢所在!(請注意,這些數據是隨機設置的,我對復仇者聯盟的成員們沒有偏見。)
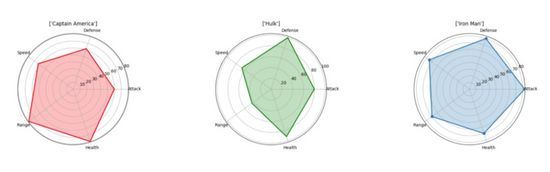
在這里,我們可以直接使用「matplotlib」而非「seaborn」來創建可視化結果。我們需要讓每個屬性沿圓周等距分布。我們將在每個角上設置標簽,然后將值繪制為一個點,它到中心的距離取決于它的值/大小。最后,為了顯示更清晰,我們將使用半透明的顏色來填充將屬性點連接起來得到的線條所包圍的區域。
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()我們從小學就開始使用樹狀圖(Tree Diagram)了!樹狀圖是自然而直觀的,這使它們容易被解釋。直接相連的節點關系密切,而具有多個連接的節點則不太相似。在下面的可視化結果中,我根據 Kaggle 的統計數據(生命值、攻擊力、防御力、特殊攻擊、特殊防御、速度)繪制了一小部分口袋妖怪游戲的數據集的樹狀圖。
因此,統計意義上最匹配的口袋妖怪將被緊密地連接在一起。例如,在圖的頂部,阿柏怪 和尖嘴鳥是直接連接的,如果我們查看數據,阿柏怪的總分為 438,尖嘴鳥則為 442,二者非常接近!但是如果我們看看拉達,我們可以看到其總得分為 413,這和阿柏怪、尖嘴鳥就具有較大差別了,所以它們在樹狀圖中是被分開的!當我們沿著樹往上移動時,綠色組的口袋妖怪彼此之間比它們和紅色組中的任何口袋妖怪都更相似,即使這里并沒有直接的綠色的連接。
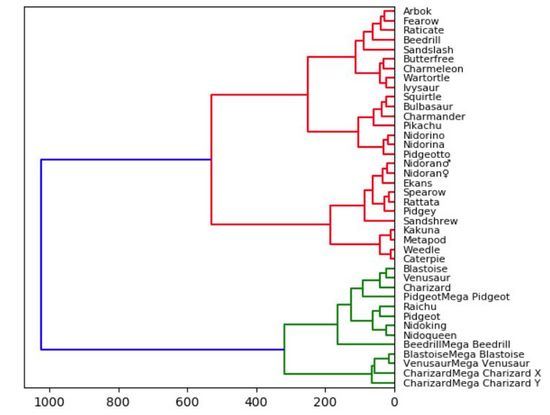
對于樹狀圖,我們實際上需要使用「Scipy」來繪制!讀取數據集中的數據之后,我們將刪除字符串列。這么做只是為了使可視化結果更加直觀、便于理解,但在實踐中,將這些字符串轉換為分類變量會得到更好的結果和對比效果。我們還設置了數據幀的索引,以便能夠恰當地將其用作引用每個節點的列。最后需要告訴大家的是,在「Scipy」中計算和繪制樹狀圖只需要一行簡單的代碼。
# Import libs
import pandas as pd
from matplotlib import pyplot as plt
from scipy.cluster import hierarchy
import numpy as np
# Read in the dataset
# Drop any fields that are strings
# Only get the first 40 because this dataset is big
df = pd.read_csv('Pokemon.csv')
df = df.set_index('Name')
del df.index.name
df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1)
df = df.head(n=40)
# Calculate the distance between each sample
Z = hierarchy.linkage(df, 'ward')
# Orientation our tree
hierarchy.dendrogram(Z, orientation="left", labels=df.index)
plt.show()關于“快速易用的Python數據可視化方法有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





