溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“MySQL索引及優化的知識點有哪些”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“MySQL索引及優化的知識點有哪些”文章能幫助大家解決問題。
索引是幫助MySQL進行高效查詢的一種數據結構。好比一本書的目錄,能加快查詢的速度
索引可以有B-Tree索引,Hash索引。索引是在存儲引擎中實現的
InnoDB / MyISAM 僅支持 B-Tree索引
Memory/Heap 支持B-Tree索引和Hash索引
B-Tree
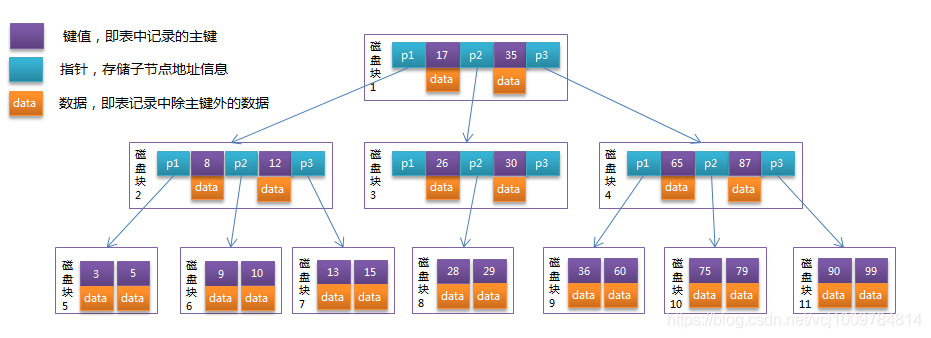
B-Tree是一種非常適合用于磁盤操作的數據結構。它是一棵多路平衡查找樹。其高度一般在2-4,其非葉子節點,葉子節點,都會存儲數據。其所有的葉子節點,都在同一層。下圖是一顆B-Tree
B+ Tree:B+樹是在B-Tree基礎上的一種優化。它和B樹的主要區別在于:B+樹的數據全部存儲在葉子節點中,且葉子節點被一個鏈表串了起來。下圖是一顆B+樹
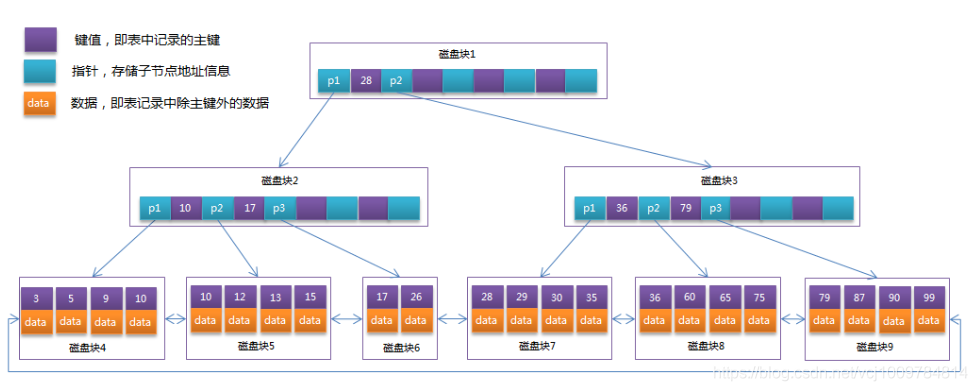
InnoDB中一個頁的大小為16KB(一個頁即B+樹上的一個節點),若表的主鍵為INT,大小為4字節,那一個節點也能夠存儲4K個鍵值,假設指針和鍵值都占相同大小,那么高度為3的B+樹,第二層有2048個節點,第三層的葉子節點數為2048*2048 = 4194304,一個節點為16KB,則一共可容納67108864KB,即65536MB,即64G的數據。
由于葉子節點是被一個鏈表串起來的,所以若order by 索引列,則默認已經是排好序的,所以效率會很高。
MyISAM索引
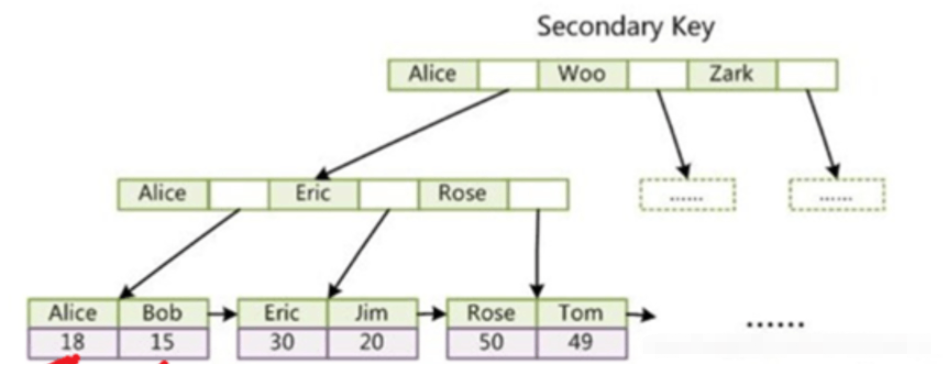
MyISAM的索引和數據是分開存放的。在MyISAM的主鍵索引中,B+樹葉子節點里,存的是記錄的地址,故MyISAM通過索引查詢,需要經過2次IO
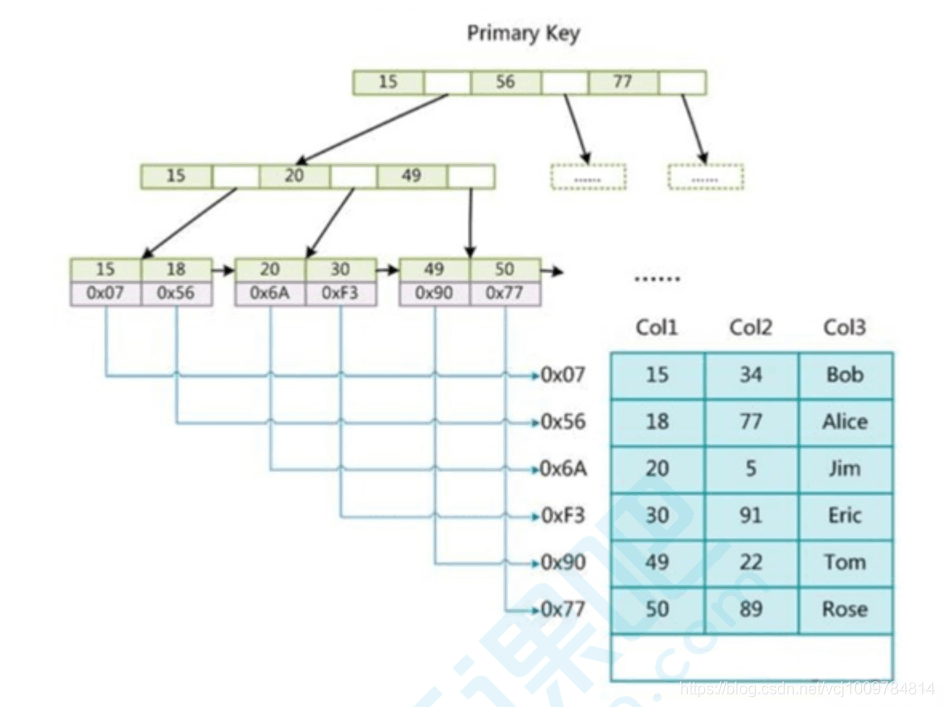
MyISAM的輔助索引和主鍵索引一樣,唯一的區別是,輔助索引中的key可以重復,而主鍵索引的key不能重復
InnoDB索引
InnoDB的數據和索引是存放在一起的,又稱聚集索引。數據通過主鍵索引,存放在主鍵索引B+樹的葉子節點上。
InnoDB主鍵索引,數據已經包含在了葉子節點中,即索引和數據存放在一起,是為聚集索引。
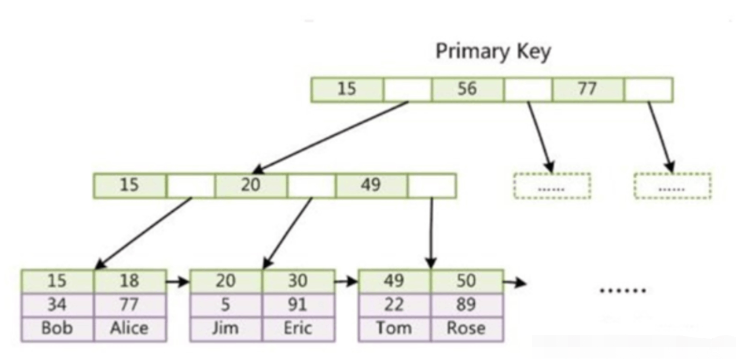
InnoDB的輔助索引,葉子節點中存的是主鍵值,而不是地址。走輔助索引,需要檢索2次。
InnoDB和MyISAM索引的區別:
InnoDB使用聚集索引,其主鍵索引葉子節點中直接存儲了數據,而其輔助索引中葉子節點存的是主鍵的值
MyISAM使用非聚集索引,數據和索引不在同一個文件中,其主鍵索引中葉子節點上存的是該行記錄所在的地址,其輔助索引中葉子節點上存的也是記錄所在的地址,只是輔助索引的key可以重復,而主鍵索引的key不能重復
問題:
InnoDB為什么不要使用過長的字段做主鍵?
過長的主鍵,會使得輔助索引所占空間變得很大
為什么推薦InnoDB使用自增主鍵?
若使用自增主鍵,則每次插入新的記錄,就會順序的將新記錄添加到當前索引節點的后續位置,一頁寫滿了,才會進行開辟新的一頁,這樣使得索引結構很緊湊,且每次插入時不需要移動已有數據,非常高效。而如果不使用自增主鍵,則每次插入新記錄時,都要選擇一個插入位置,并且可能需要移動數據,使得效率不高,且索引結構不緊湊
為什么要用B+樹,不用B樹
索引本身也比較大,一般會存儲在磁盤中,索引和數據可能是分開存放的(MyISAM的非聚集索引),也可能是一起存放的(InnoDB的聚集索引)
優點
降低IO成本,提高數據查詢效率
降低排序成本(被索引的列會自動排序,使用order by 效率會提高很多)
缺點
索引會額外占據存儲空間
索引會降低更新表數據的效率。進行增刪改操作時,不僅要保存數據,還要更新對應的索引
單列索引
主鍵索引
唯一索引
普通索引
組合索引
建立索引
CREATE INDEX index_name ON table_name(col_name); -- 或者 ALTER TABLE table_name ADD INDEX index_name(col_name)
刪除索引
DROP INDEX index_name ON table_name;
需要建立索引的場景
頻繁作為查詢條件的列,需建索引
多表關聯中,關聯字段需建索引
查詢中排序的字段,需建索引
不適用索引的場景
寫多讀少的表,不適合建索引
頻繁更新的字段,不適合建索引
現有一張user表,其索引如下所示

其中name,age,address 三個字段作為一個組合索引
可以使用explain對某個SQL語句進行性能分析
explain select * from user where name = 'am';

possible_keys
可能用到的索引
key
實際用到的索引
key_len
用于查詢的索引的長度
ref
如果是等值查詢,這里會會是const
rows
預計需要掃描的行數(不是精確值)
extra
額外信息,如
using where
表示存儲引擎返回的結果,還需要在SQL Layer層過濾
using index
表示不需要回表查詢,一般在使用了覆蓋索引時會是這個值。覆蓋索引指的是,select中的列,全是索引列。不需要回表查詢指的是,直接走輔助索引,就能拿到索引列的值,不需要再去主鍵索引上取記錄了
using index condition
MySQL 5.6.x之后支持ICP特性(Index Condition Pushdown),可以把檢查條件下推到存儲引擎層,不符合條件的記錄,直接不讀取,而不是像原來一樣,先讀取出來,再在SQL Layer層過濾,這樣減少了存儲引擎層掃描的行數

using filesort
排序時無法用到索引
type
system : 表中只有1行數據,或空表
const : 使用唯一索引或主鍵索引,且用where等值查詢,返回記錄是1行,又叫唯一索引掃描

ref : 針對非唯一索引,使用等值where條件,或者最左前綴規則的查詢。
下面是滿足了最左前綴規則,即對idx_name_age_add來說,滿足了最左前綴,第一個索引為name

range:索引范圍掃描,常見于>,<,between,in,like等查詢


注意like時,通配符%不能放在開頭,否則會導致全表掃描

index : 沒有完全匹配上索引,但不用回表查詢的


all: 全表掃描,然后再在SQL Layer層過濾符合要求的記錄
全值匹配
在索引列上使用等值查詢
explain select * from user where name = 'y' and age = 15;

2. 最左前綴
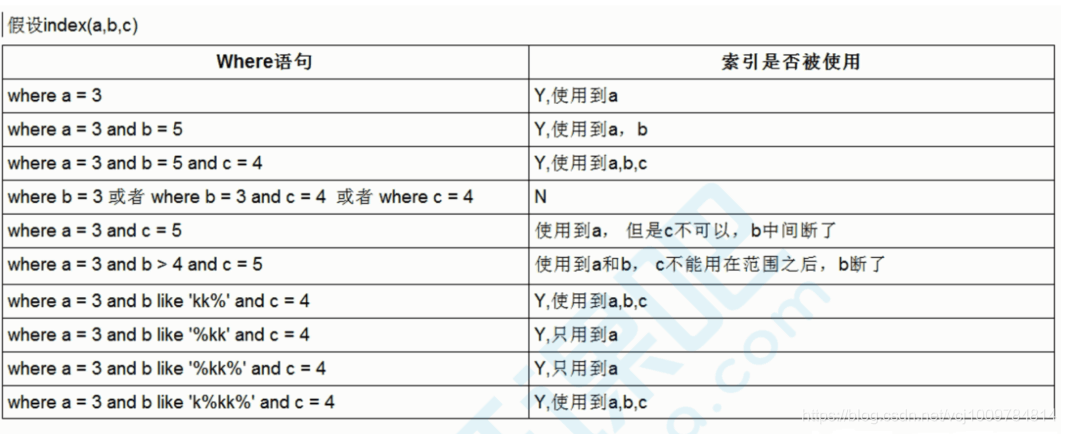
組合索引中,查詢條件要從組合索引的最左列開始,如上述example中組合索引idx_name_age_add,是建立在三個列name,age,address的,若跳過name,直接用age查詢,則會變為全表掃描
explain select * from user where age = 15;

3. 不要在索引列上做計算
4. 范圍條件右側的索引列會失效
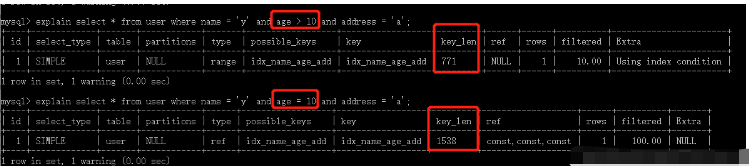
看到第一個SQL語句,沒有用上addresss索引
5. 盡量使用覆蓋索引
explain select name,age from user where name = 'y' and age = 1;
可以避免回表查詢
6. 索引字段不要使用不等(!= 或 <>),不要判斷null(is null/ is not null)
會導致索引失效,轉為全表掃描


7. 索引字段上使用like時,不要以%開頭

8. 索引字段如果是字符串,記得加單引號

9. 索引字段不要用or

關于“MySQL索引及優化的知識點有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





