溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何用scrapy框架爬取豆瓣讀書Top250的書類信息”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何用scrapy框架爬取豆瓣讀書Top250的書類信息”吧!
安裝方法:Windows:在終端輸入命令:pip install scrapy;mac:在終端輸入命令:pip3 install scrapy,按下enter鍵,再輸入cd Python,就能跳轉到Python文件夾。接著輸入cd Pythoncode,就能跳轉到Python文件夾里的Pythoncode子文件夾。最后輸入一行能幫我們創建Scrapy項目的命令:scrapy startproject douban,douban就是Scrapy項目的名字。按下enter鍵,一個Scrapy項目就創建成功了。
爬取豆瓣讀書Top250的書名,出版信息和評分
目標url為:https://book.douban.com/top250?start=0
整個scrapy項目的結構,如下圖
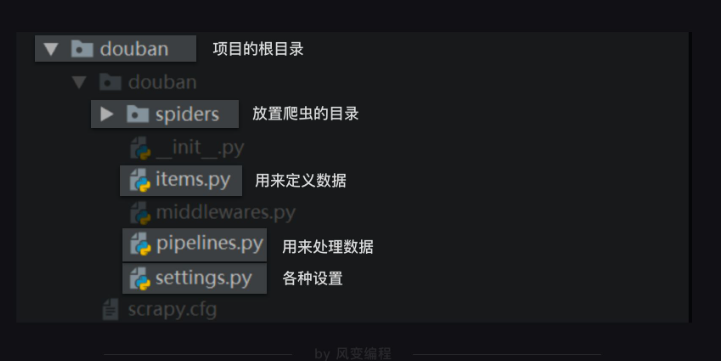
spiders是放置爬蟲的目錄。我們在spiders這個文件夾里創建爬蟲文件,我們把這個文件命名為top250,大部分代碼都需要在這個top250.py文件里編寫。在top250.py文件里導入我們需要的模塊:import scrapy , bs4
導入scrapy是我們要用創建類的方式寫這個爬蟲,我們所創建的類將直接繼承scrapy中的scrapy.Spider類。這樣,有許多好用屬性和方法,就能夠直接使用。
class DoubanSpider(scrapy.Spider): #定義一個爬蟲類DoubanSpider,DoubanSpider類繼承自scrapy.Spider類。 name = 'douban' #定義爬蟲的名字,這個名字是爬蟲的唯一標識。 allowed_domains = ['book.douban.com']#定義允許爬蟲爬取的網址域名(不需要加https://)。如果網址的域名不在這個列表里,就會被過濾掉。allowed_domains就限制了,我們這種關聯爬取的URL,一定在book.douban.com這個域名之下,不會跳轉到某個奇怪的廣告頁面。 start_urls = ['https://book.douban.com/top250?start=0']#定義起始網址,就是爬蟲從哪個網址開始抓取 def parse(self, response):#parse是Scrapy里默認處理response的一個方法,中文是解析。 print(response.text) #這里我們并不需要寫類似requests.get()的語句,scrapy框架會為我們代勞做這件事,寫好你的請求,接下來你就可以直接寫對響應如何做處理
每一次,當數據完成記錄,它會離開spiders,來到Scrapy Engine(引擎),引擎將它送入Item Pipeline(數據管道)處理。定義這個類的py文件,正是items.py。
如果要爬取豆瓣讀書的書名、出版信息和評分,示例:
import scrapy #導入scrapy class DoubanItem(scrapy.Item): #定義一個類DoubanItem,它繼承自scrapy.Item title = scrapy.Field() #定義書名的數據屬性 publish = scrapy.Field() #定義出版信息的數據屬性 score = scrapy.Field() #定義評分的數據屬性
scrapy.Field()這行代碼實現的是,讓數據能以類似字典的形式記錄,它輸出的結果非常像字典,但它卻并不是dict,它的數據類型是我們定義的DoubanItem,屬于自定義的Python字典.我們利用類似上述代碼的樣式,去重新寫top250.py
import scrapy
import bs4
from ..items import DoubanItem
# 需要引用DoubanItem,它在items里面。因為是items在top250.py的上一級目錄,所以要用..items,這是一個固定用法。
class DoubanSpider(scrapy.Spider):
#定義一個爬蟲類DoubanSpider。
name = 'douban'
#定義爬蟲的名字為douban。
allowed_domains = ['book.douban.com']
#定義爬蟲爬取網址的域名。
start_urls = []
#定義起始網址。
for x in range(3):
url = 'https://book.douban.com/top250?start=' + str(x * 25)
start_urls.append(url)
#把豆瓣Top250圖書的前3頁網址添加進start_urls。
def parse(self, response):
#parse是默認處理response的方法。
bs = bs4.BeautifulSoup(response.text,'html.parser')
#用BeautifulSoup解析response。
datas = bs.find_all('tr',class_="item")
#用find_all提取<tr class="item">元素,這個元素里含有書籍信息。
for data in datas:
#遍歷data。
item = DoubanItem()
#實例化DoubanItem這個類。
item['title'] = data.find_all('a')[1]['title']
#提取出書名,并把這個數據放回DoubanItem類的title屬性里。
item['publish'] = data.find('p',class_='pl').text
#提取出出版信息,并把這個數據放回DoubanItem類的publish里。
item['score'] = data.find('span',class_='rating_nums').text
#提取出評分,并把這個數據放回DoubanItem類的score屬性里。
print(item['title'])
#打印書名。
yield item
#yield item是把獲得的item傳遞給引擎。當我們每一次,要記錄數據的時候,比如前面在每一個最小循環里,都要記錄“書名”,“出版信息”,“評分”。我們會實例化一個item對象,利用這個對象來記錄數據。
每一次,當數據完成記錄,它會離開spiders,來到Scrapy Engine(引擎),引擎將它送入Item Pipeline(數據管道)處理。這里,要用到yield語句。
yield語句它有點類似return,不過它和return不同的點在于,它不會結束函數,且能多次返回信息。
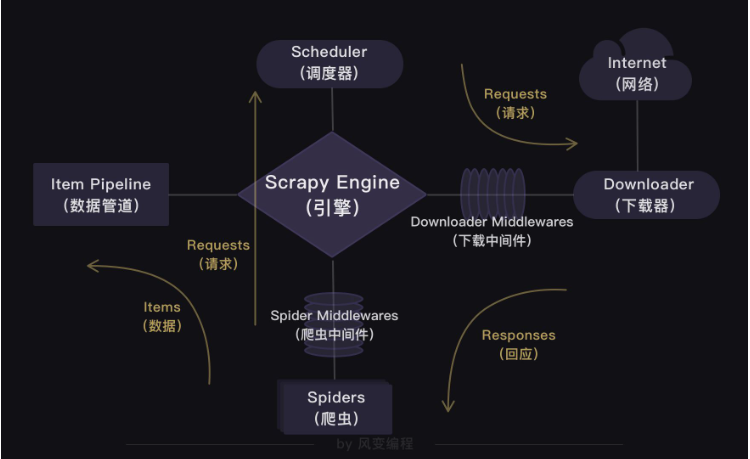
就如同上圖所示:爬蟲(Spiders)會把豆瓣的10個網址封裝成requests對象,引擎會從爬蟲(Spiders)里提取出requests對象,再交給調度器(Scheduler),讓調度器把這些requests對象排序處理。然后引擎再把經過調度器處理的requests對象發給下載器(Downloader),下載器會立馬按照引擎的命令爬取,并把response返回給引擎。
緊接著引擎就會把response發回給爬蟲(Spiders),這時爬蟲會啟動默認的處理response的parse方法,解析和提取出書籍信息的數據,使用item做記錄,返回給引擎。引擎將它送入Item Pipeline(數據管道)處理。
點擊settings.py文件,把USER _AGENT的注釋取消(刪除#),然后替換掉user-agent的內容,就是修改了請求頭。
因為Scrapy是遵守robots協議的,如果是robots協議禁止爬取的內容,Scrapy也會默認不去爬取,所以修改Scrapy中的默認設置。把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots協議換成無需遵從robots協議,這樣Scrapy就能不受限制地運行。
想要運行Scrapy有兩種方法,一種是在本地電腦的終端跳轉到scrapy項目的文件夾
(跳轉方法:cd+文件夾的路徑名如:
cd D:\python\Pythoncode\douban\douban)
然后輸入命令行:scrapy crawl douban(douban 就是我們爬蟲的名字)。)
另一種運行方式需要我們在最外層的大文件夾里新建一個main.py文件(與scrapy.cfg同級)。
然后在這個main.py文件里,輸入以下代碼,點擊運行,Scrapy的程序就會啟動。
from scrapy import cmdline #導入cmdline模塊,可以實現控制終端命令行。 cmdline.execute(['scrapy','crawl','douban']) #用execute()方法,輸入運行scrapy的命令。
第1行代碼:在Scrapy中有一個可以控制終端命令的模塊cmdline。導入了這個模塊,我們就能操控終端。
第2行代碼:在cmdline模塊中,有一個execute方法能執行終端的命令行,不過這個方法需要傳入列表的參數。我們想輸入運行Scrapy的代碼scrapy crawl douban,就需要寫成[‘scrapy’,‘crawl’,‘douban’]這樣。
在實際項目實戰中,我們應該先定義數據,再寫爬蟲。所以,流程圖應如下:
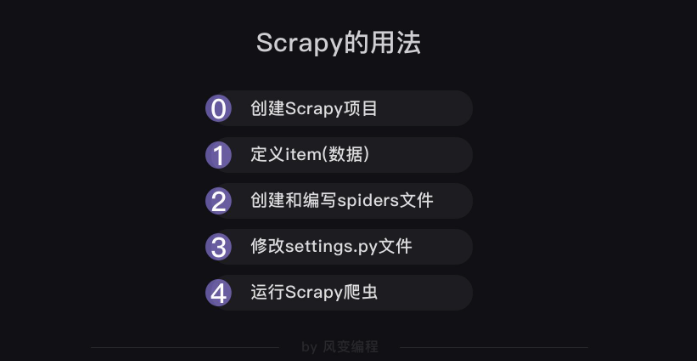
最后,存儲數據需要修改pipelines.py文件
感謝各位的閱讀,以上就是“如何用scrapy框架爬取豆瓣讀書Top250的書類信息”的內容了,經過本文的學習后,相信大家對如何用scrapy框架爬取豆瓣讀書Top250的書類信息這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





