溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“MySQL調優之SQL查詢深度分頁問題怎么解決”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“MySQL調優之SQL查詢深度分頁問題怎么解決”吧!
例如當前存在一張表test_user,然后往這個表里面插入3百萬的數據:
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵id', `user_id` varchar(36) NOT NULL COMMENT '用戶id', `user_name` varchar(30) NOT NULL COMMENT '用戶名稱', `phone` varchar(20) NOT NULL COMMENT '手機號碼', `lan_id` int(9) NOT NULL COMMENT '本地網', `region_id` int(9) NOT NULL COMMENT '區域', `create_time` datetime NOT NULL COMMENT '創建時間', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
在數據庫開發過程中我們經常會使用分頁,核心技術是使用用 limit start, count 分頁語句進行數據的讀取。
我們分別看下從0、10000、100000、500000、1000000、1800000開始分頁的執行時長(每頁取100條)。
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
我們已經看出隨著起始記錄的增加,時間也隨著增大。這說明分頁語句limit跟起始頁碼是有很大關系的,那么我們把起始記錄改為290w看下:
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
我們驚訝的發現MySQL在數據量大的情況下分頁起點越大,查詢速度越慢!
那么為什么會出現上述這種情況呢?
答案: 因為 limit 2900000,100 的語法實際上是mysql掃描到前2900100條數據,之后丟棄前面的3000000行,這個步驟其實是浪費掉的。
從中我們也能總結出以下兩件事情:
limit語句的查詢時間與起始記錄的位置成正比。
mysql的limit語句是很方便,但是對記錄很多的表并不適合直接使用。
limit子句可以被用于強制select語句返回指定的記錄數,其語法格式如下:
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;
limit接受一個或兩個數字參數,參數必須是一個整數常量,如果給定兩個參數:
第一個參數指定第一個返回記錄行的偏移量
第二個參數指定返回記錄行的最大數目
2.1 m代表從m+1條記錄行開始檢索,n代表取出n條數據。(m可設為0)
SELECT * FROM 表名 limit 6,5;
上述SQL表示從第7條記錄行開始算,取出5條數據
2.2 值得注意的是,n可以被設置為-1,當n為-1時,表示從m+1行開始檢索,直到取出最后一條數據
SELECT * FROM 表名 limit 6,-1;
上述SQL表示取出第6條記錄行以后的所有數據
2.3 若只給出m,則表示從第1條記錄行開始算一共取出m條
SELECT * FROM 表名 limit 6;
2.4 以年齡倒序后取出前3行
select * from student order by age desc limit 3;
2.5 跳過前3行后再2取行
select * from student order by age desc limit 3,2;
即先找到上次分頁的最大id,然后利用id上的索引來查詢:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
使用此優化SQL相比于前面的查詢速度已經快了11倍。除了主鍵ID,也可以利用唯一索引快速定位部分數據,避免全表掃描。例如讀取第1000到1019行數據(pk是唯一鍵),則相對應的優化SQL如下:
SELECT * FROM 表名稱 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
原因:索引掃描,速度會很快。
適用場景:如果數據查詢出來是按照pk或者id進行排序,并且全部數據沒有缺失的話則可以這樣優化,否則分頁操作會漏數據。
我們都知道,利用了索引查詢的語句中如果只包含了那個索引列(也就是索引覆蓋),那么這種情況會查詢很快。
為什么索引覆蓋查詢會很快呢?
答案:因為利用索引查找有優化算法,且數據就在查詢索引上面,不用再去找相關的數據地址了,這樣節省了很多時間。另外Mysql中也有相關的索引緩存,在并發高的時候利用緩存就效果更好了。
在我們的測試表test_user中,id字段是主鍵,自然就包含了默認的主鍵索引。現在讓我們看看利用覆蓋索引的查詢效果如何。
這次我們查詢第1000001到1000100行的數據(利用覆蓋索引,只包含id列):
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
從這個結果中發現查詢速度比全表掃描速度還要慢(當然在重復執行這條SQL,多次查詢之后速度還是變快了很多,幾乎省了一半時間,這是由于緩存的原因), 接著使用explain命令來查看該SQL的執行計劃,發現該SQL執行采用的普通索引 idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
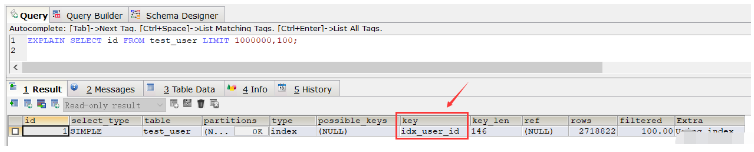
如果我們把普通索引給刪除的話,就會發現執行上述SQL其采用的會是主鍵索引。那如果不刪除普通索引的話,針對這種情況,我們要讓上述SQL走主鍵索引的話,則可以使用order by語句:
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
那么如果我們也要查詢所有列,有兩種方法,一種是id>=的形式,另一種就是利用join。
第一種寫法:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
上述SQL查詢時間為0.281秒
第二種寫法:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
上述SQL查詢時間為0.252秒
其中pageNum表示頁碼,其取值從0開始;pageSize表示指的是每頁多少條數據。
SELECT * FROM 表名稱 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
適應場景:
適用于數據量多的情況
最好ORDER BY后的列對象是主鍵或唯一索引
id數據沒有缺失,可以作為序號使用
使用ORDER BY操作能利用索引被消除,但結果集是穩定的
原因:
索引掃描,速度會很快
但MySQL的排序操作,只有ASC沒有DESC。MySQL中索引存儲的排序方式是ASC的,沒有DESC的索引。這就能夠理解為啥order by 默認是按照ASC來排序的了吧
PREPARE預編譯一個SQL語句,并為其分配一個名稱 stmt_name,以便以后引用該語句,預編譯好的語句用EXECUTE執行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查詢時間為0.047秒。
對于定義好的PREPARE預編譯語句,我們可以使用下述命令來釋放該預編譯語句:
DEALLOCATE PREPARE stmt_name;
原因:
索引掃描,速度會很快.
prepare語句又比一般的查詢語句快一點。
其中page表示頁碼,其取值從0開始;pagesize表示指的是每頁多少條數據。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
假設數據表 collect ( id, title ,info ,vtype) 就這4個字段,其中id是主鍵自增,title用定長,info用text, vtype是tinyint,vtype是一個普通索引。
現在往里面填充數據,填充10萬條記錄,數據庫表占用硬1.6G。
select id,title from collect limit 1000,10;
執行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再執行上述SQL,就發現非常慢,基本上平均8~9秒完成。
這個時候如果我們執行下述,我們會發現速度又變的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么這個現象的原因是什么?
答案:因為用了id主鍵做索引, 這里實現了索引覆蓋,當然快。
所以如果想一起查詢其它列的話,可以按照索引覆蓋進行優化,具體如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的語句,帶上where 條件:
select id from collect where vtype=1 order by id limit 90000,10;
可以發現這個速度上也是很慢的,用了8~9秒!
這里有一個疑惑:vtype 做了索引了啊?怎么會慢呢?
vtype做了索引是不錯,如果直接對vtype進行過濾:
select id from collect where vtype=1 limit 1000,10;
可以看到速度還是很快的,基本上0.05秒,如果從9萬開始,那就是0.05*90=4.5秒的速度了。
其實加了 order by id 就不走索引,這樣做還是全表掃描,解決的辦法是:復合索引!
因此針對下述SQL深度分頁優化時可以加一個search_index(vtype,id)復合索引:
select id from collect where vtype=1 order by id limit 90000,10;
綜上:
在進行SQL查詢深度分頁優化時,如果對于有where條件,又想走索引用limit的,必須設計一個索引,將where放第一位,limit用到的主鍵放第二位,而且只能select 主鍵。
最后根據查詢出的主鍵走一級索引找到對應的數據。
按這樣的邏輯,百萬級的limit 在0.0x秒就可以分完,完美解決了分頁問題。
感謝各位的閱讀,以上就是“MySQL調優之SQL查詢深度分頁問題怎么解決”的內容了,經過本文的學習后,相信大家對MySQL調優之SQL查詢深度分頁問題怎么解決這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





