溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Java怎么使用DFA算法實現敏感詞過濾”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Java怎么使用DFA算法實現敏感詞過濾”吧!
敏感詞過濾就是你在項目中輸入某些字(比如輸入xxoo相關的文字時)時要能檢測出來,很多項目中都會有一個敏感詞管理模塊,在敏感詞管理模塊中你可以加入敏感詞,然后根據加入的敏感詞去過濾輸入內容中的敏感詞并進行相應的處理,要么提示,要么高亮顯示,要么直接替換成其它的文字或者符號代替。
敏感詞過濾的做法有很多,其中有比較常用的如下幾種:
1.查詢數據庫當中的敏感詞,循環每一個敏感詞,然后去輸入的文本中從頭到尾搜索一遍,看是否存在此敏感詞,有則做相應的處理,這種方式講白了就是找到一個處理一個。
優點:so easy。用java代碼實現基本沒什么難度。
缺點:這效率是非常低的,如果是英文時你會發現一個很無語的事情,比如英文a是敏感詞,那我如果是一篇英文文檔,那程序它得處理多少次敏感詞?誰能告訴我?
2.傳說中的DFA算法(有限狀態機),也正是我要給大家分享的,畢竟感覺比較通用,算法的原理希望大家能夠自己去網上查查
資料,這里就不詳細說明了。
優點:至少比上面那sb效率高點。
缺點:對于學過算法的應該不難,對于沒學過算法的用起來也不難,就是理解起來有點gg疼,匹配效率也不高,比較耗費內存,
敏感詞越多,內存占用的就越大。
在項目啟動前讀取數據,將敏感詞加載到Map中,具體實現如下:
建表語句:
CREATE TABLE `sensitive_word` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `content` varchar(50) NOT NULL COMMENT '關鍵詞', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4; INSERT INTO `fuying`.`sensitive_word` (`id`, `content`, `create_time`, `update_time`) VALUES (1, '吳名氏', '2023-03-02 14:21:36', '2023-03-02 14:21:36');
實體類SensitiveWord.java:
package com.wkf.workrecord.tools.dfa.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
/**
* @author wuKeFan
* @date 2023-03-02 13:48:58
*/
@Data
@TableName("sensitive_word")
public class SensitiveWord implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
private String content;
private Date createTime;
private Date updateTime;
}數據庫持久類SensitiveWordMapper.java:
package com.wkf.workrecord.tools.dfa.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.wkf.workrecord.tools.dfa.entity.SensitiveWord;
/**
* @author wuKeFan
* @date 2023-03-02 13:50:16
*/
public interface SensitiveWordMapper extends BaseMapper<SensitiveWord> {
}service類SensitiveWordService.java和SensitiveWordServiceImpl.java:
package com.wkf.workrecord.tools.dfa.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.wkf.workrecord.tools.dfa.entity.SensitiveWord;
import java.util.Set;
/**
* 敏感詞過濾服務類
* @author wuKeFan
* @date 2023-03-02 13:47:04
*/
public interface SensitiveWordService extends IService<SensitiveWord> {
Set<String> sensitiveWordFiltering(String text);
}package com.wkf.workrecord.tools.dfa.service;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.wkf.workrecord.tools.dfa.mapper.SensitiveWordMapper;
import com.wkf.workrecord.tools.dfa.SensitiveWordUtils;
import com.wkf.workrecord.tools.dfa.entity.SensitiveWord;
import org.springframework.stereotype.Service;
import java.util.Set;
/**
* @author wuKeFan
* @date 2023-03-02 13:48:04
*/
@Service
public class SensitiveWordServiceImpl extends ServiceImpl<SensitiveWordMapper, SensitiveWord> implements SensitiveWordService{
@Override
public Set<String> sensitiveWordFiltering(String text) {
// 得到敏感詞有哪些,傳入2表示獲取所有敏感詞
return SensitiveWordUtils.getSensitiveWord(text, 2);
}
}敏感詞過濾工具類SensitiveWordUtils:
package com.wkf.workrecord.tools.dfa;
import com.wkf.workrecord.tools.dfa.entity.SensitiveWord;
import lombok.extern.slf4j.Slf4j;
import java.util.*;
/**
* 敏感詞過濾工具類
* @author wuKeFan
* @date 2023-03-02 13:45:19
*/
@Slf4j
@SuppressWarnings("unused")
public class SensitiveWordUtils {
/**
* 敏感詞庫
*/
public static final Map<Object, Object> sensitiveWordMap = new HashMap<>();
/**
* 只過濾最小敏感詞
*/
public static int minMatchTYpe = 1;
/**
* 過濾所有敏感詞
*/
public static int maxMatchType = 2;
/**
* 初始化敏感詞
*/
public static void initKeyWord(List<SensitiveWord> sensitiveWords) {
try {
// 從敏感詞集合對象中取出敏感詞并封裝到Set集合中
Set<String> keyWordSet = new HashSet<>();
for (SensitiveWord s : sensitiveWords) {
keyWordSet.add(s.getContent().trim());
}
// 將敏感詞庫加入到HashMap中
addSensitiveWordToHashMap(keyWordSet);
}
catch (Exception e) {
log.error("初始化敏感詞出錯,", e);
}
}
/**
* 封裝敏感詞庫
*
* @param keyWordSet 敏感詞庫列表
*/
private static void addSensitiveWordToHashMap(Set<String> keyWordSet) {
// 敏感詞
String key;
// 用來按照相應的格式保存敏感詞庫數據
Map<Object, Object> nowMap;
// 用來輔助構建敏感詞庫
Map<Object, Object> newWorMap;
// 使用一個迭代器來循環敏感詞集合
for (String s : keyWordSet) {
key = s;
// 等于敏感詞庫,HashMap對象在內存中占用的是同一個地址,所以此nowMap對象的變化,sensitiveWordMap對象也會跟著改變
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
// 截取敏感詞當中的字,在敏感詞庫中字為HashMap對象的Key鍵值
char keyChar = key.charAt(i);
// 判斷這個字是否存在于敏感詞庫中
Object wordMap = nowMap.get(keyChar);
if (wordMap != null) {
nowMap = (Map<Object, Object>) wordMap;
} else {
newWorMap = new HashMap<>();
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
// 如果該字是當前敏感詞的最后一個字,則標識為結尾字
if (i == key.length() - 1) {
nowMap.put("isEnd", "1");
}
log.info("封裝敏感詞庫過程:" + sensitiveWordMap);
}
log.info("查看敏感詞庫數據:" + sensitiveWordMap);
}
}
/**
* 敏感詞庫敏感詞數量
*
* @return 返回數量
*/
public static int getWordSize() {
return SensitiveWordUtils.sensitiveWordMap.size();
}
/**
* 是否包含敏感詞
*
* @param txt 敏感詞
* @param matchType 匹配類型
* @return 返回結果
*/
public static boolean isContainSensitiveWord(String txt, int matchType) {
boolean flag = false;
for (int i = 0; i < txt.length(); i++) {
int matchFlag = checkSensitiveWord(txt, i, matchType);
if (matchFlag > 0) {
flag = true;
}
}
return flag;
}
/**
* 獲取敏感詞內容
*
* @param txt 敏感詞
* @param matchType 匹配類型
* @return 敏感詞內容
*/
public static Set<String> getSensitiveWord(String txt, int matchType) {
Set<String> sensitiveWordList = new HashSet<>();
for (int i = 0; i < txt.length(); i++) {
int length = checkSensitiveWord(txt, i, matchType);
if (length > 0) {
// 將檢測出的敏感詞保存到集合中
sensitiveWordList.add(txt.substring(i, i + length));
i = i + length - 1;
}
}
return sensitiveWordList;
}
/**
* 替換敏感詞
*
* @param txt 敏感詞
* @param matchType 匹配類型
* @param replaceChar 代替詞
* @return 返回敏感詞
*/
public static String replaceSensitiveWord(String txt, int matchType, String replaceChar) {
String resultTxt = txt;
Set<String> set = getSensitiveWord(txt, matchType);
Iterator<String> iterator = set.iterator();
String word;
String replaceString;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
}
return resultTxt;
}
/**
* 替換敏感詞內容
*
* @param replaceChar 需要替換的敏感詞
* @param length 替換長度
* @return 返回結果
*/
private static String getReplaceChars(String replaceChar, int length) {
StringBuilder resultReplace = new StringBuilder(replaceChar);
for (int i = 1; i < length; i++) {
resultReplace.append(replaceChar);
}
return resultReplace.toString();
}
/**
* 檢查敏感詞數量
*
* @param txt 敏感詞
* @param beginIndex 開始下標
* @param matchType 匹配類型
* @return 返回數量
*/
public static int checkSensitiveWord(String txt, int beginIndex, int matchType) {
boolean flag = false;
// 記錄敏感詞數量
int matchFlag = 0;
char word;
Map<Object, Object> nowMap = SensitiveWordUtils.sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
word = txt.charAt(i);
// 判斷該字是否存在于敏感詞庫中
nowMap = (Map<Object, Object>) nowMap.get(word);
if (nowMap != null) {
matchFlag++;
// 判斷是否是敏感詞的結尾字,如果是結尾字則判斷是否繼續檢測
if ("1".equals(nowMap.get("isEnd"))) {
flag = true;
// 判斷過濾類型,如果是小過濾則跳出循環,否則繼續循環
if (SensitiveWordUtils.minMatchTYpe == matchType) {
break;
}
}
}
else {
break;
}
}
if (!flag) {
matchFlag = 0;
}
return matchFlag;
}
}項目啟動完成后執行初始化敏感關鍵字StartInit.java:
package com.wkf.workrecord.tools.dfa;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.wkf.workrecord.tools.dfa.entity.SensitiveWord;
import com.wkf.workrecord.tools.dfa.mapper.SensitiveWordMapper;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.List;
/**
* 初始化敏感關鍵字
* @author wuKeFan
* @date 2023-03-02 13:57:45
*/
@Component
public class StartInit {
@Resource
private SensitiveWordMapper sensitiveWordMapper;
@PostConstruct
public void init() {
// 從數據庫中獲取敏感詞對象集合(調用的方法來自Dao層,此方法是service層的實現類)
List<SensitiveWord> sensitiveWords = sensitiveWordMapper.selectList(new QueryWrapper<>());
// 構建敏感詞庫
SensitiveWordUtils.initKeyWord(sensitiveWords);
}
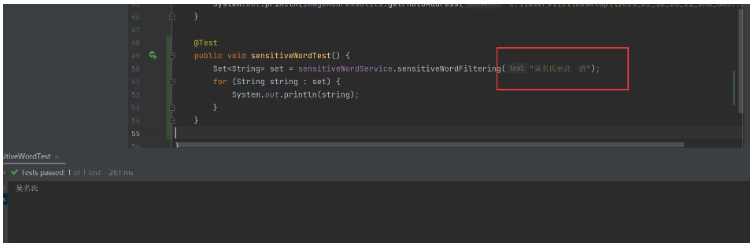
}編寫測試腳本測試效果.代碼如下:
@Test
public void sensitiveWordTest() {
Set<String> set = sensitiveWordService.sensitiveWordFiltering("吳名氏到此一游");
for (String string : set) {
System.out.println(string);
}
}執行結果如下:
到此,相信大家對“Java怎么使用DFA算法實現敏感詞過濾”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





