溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“C++11中的可變參數模板和lambda表達式怎么使用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
C++11的新特性可變參數模板能夠讓我們創建可以接受可變參數的函數模板和類模板,相比C++98和C++03,類模板和函數模板中只能含固定數量的模板參數,可變參數模板無疑是一個巨大的改進。可是可變參數模板比較抽象,因此這里只會寫出夠我們使用的部分。
下面是一個基本可變參數的函數模板
// Args是一個模板參數包,args是一個函數形參參數包
// 聲明一個參數包Args...args,這個參數包中可以包含0到任意個模板參數。
template <class ...Args>
void ShowList(Args... args)
{}上面的參數args前面有省略號,所以它就是一個可變模版參數,我們把帶省略號的參數稱為“參數
包”,它里面包含了0到N(N>=0)個模版參數。我們無法直接獲取參數包args中的每個參數的,只能通過展開參數包的方式來獲取參數包中的每個參數,這是使用可變模版參數的一個主要特點,也是最大的難點,即如何展開可變模版參數。
//遞歸終止函數
template <class T>
void showList(const T& t)
{
cout << y << endl;
}
//展開函數
template<class T,class ...Args>
void showList(T value, Args... args)
{
cout << value << " ";
showList(args...);
}
int main()
{
showList(1);
showList(1,'A');
showList(1,'A',std::string("sort"));
return 0;
}
代碼分析:
①showList(1): 如果只有一個參數,那會直接調用第一個showList函數。
②showList(1,'A'): 匹配到第二個showList函數后,先將1打印出來。然后通過遞歸,看看args里面有多少個參數,如果只有一個,比如這里的'A',那么就會去調用第一個showList函數。
③showList(1,'A',"sort"): 匹配到第二個showList函數后,先將1打印出來。然后通過遞歸,看看args里面有多少個參數,這里有兩個,那么繼續調用第二個showList函數,此時的value變成了'A',依次類推。
這種展開參數包的方式,不需要通過遞歸終止函數,是直接在expand函數體中展開的, printarg不是一個遞歸終止函數,只是一個處理參數包中每一個參數的函數。這種就地展開參數包的方式實現的關鍵是逗號表達式。我們知道逗號表達式會按順序執行逗號前面的表達式。
expand函數中的逗號表達式:(printarg(args), 0),也是按照這個執行順序,先執行printarg(args),再得到逗號表達式的結果0。同時還用到了C++11的另外一個特性——初始化列表,通過初始化列表來初始化一個變長數組, {(printarg(args), 0)...}將會展開成((printarg(arg1),0),(printarg(arg2),0), (printarg(arg3),0), etc... ),最終會創建一個元素值都為0的數組int arr[sizeof...(Args)]。由于是逗號表達式,在創建數組的過程中會先執行逗號表達式前面的部分printarg(args)打印出參數,也就是說在構造int數組的過程中就將參數包展開了,這個數組的目的純粹是為了在數組構造的過程展開參數包。
template <class T>
void PrintArg(T t)
{
cout << t << " ";
}
//展開函數
template <class ...Args>
void ShowList(Args... args)
{
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
int main()
{
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
}STL容器中的empalce相關接口函數:
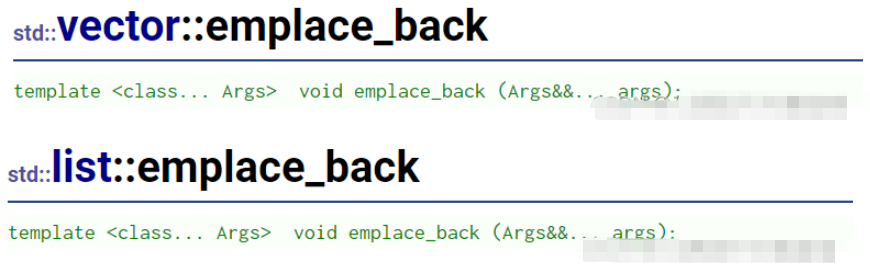
template <class... Args> void emplace_back (Args&&... args)
首先我們看到的emplace系列的接口,支持模板的可變參數,并且萬能引用。那么相對insert和
emplace系列接口的優勢到底在哪里呢
int main()
{
std::list< std::pair<int, char> > mylist;
// emplace_back支持可變參數,拿到構建pair對象的參數后自己去創建對象
// 那么在這里我們可以看到除了用法上,和push_back沒什么太大的區別
mylist.emplace_back(10, 'a');
mylist.emplace_back(20, 'b');
mylist.emplace_back(make_pair(30, 'c'));
mylist.push_back(make_pair(40, 'd'));
mylist.push_back({ 50, 'e' });
for (auto e : mylist)
cout << e.first << ":" << e.second << endl;
return 0;
}在C++98中,如果想要對一個數據集合中的元素進行排序,可以使用std::sort方法
int main()
{
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
// 默認按照小于比較,排出來結果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
// 如果需要降序,需要改變元素的比較規則
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
return 0;
}如果待排序元素為自定義類型,還需要我們定義排序時的比較規則。隨著C++語法的發展,人們開始覺得這種寫法太復雜了,每次為了實現一個algorithm算法,都要重新去寫一個類,如果每次比較的邏輯不一樣,還要去實現多個類,特別是相同類的命名,這些都給編程者帶來了極大的不便。因此,在C++11語法中出現了Lambda表達式。
//自定義類型
struct Goods
{
string _name; // 名字
double _price; // 價格
int _evaluate; // 評價
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
int main()
{
vector<Goods> v = { { "蘋果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠蘿", 1.5, 4 } };
//比較價格
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price; });
//比較評價
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate < g2._evaluate; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate > g2._evaluate; });
return 0;
}上述代碼就是使用C++11中的lambda表達式來解決,可以看出lambda表達式實際是一個匿名函數。
ambda表達式書寫格式:[capture-list] (parameters) mutable -> return-type { statement}
lambda表達式各部分說明:
[capture-list] : 捕捉列表,該列表總是出現在lambda函數的開始位置,編譯器根據[]來判斷接下來的代碼是否為lambda函數,捕捉列表能夠捕捉上下文中的變量供lambda函數使用。
(parameters):參數列表。與普通函數的參數列表一致,如果不需要參數傳遞,則可以連同()一起省略
mutable:默認情況下,lambda函數總是一個const函數,mutable可以取消其常量性。使用該修飾符時,參數列表不可省略(即使參數為空)。
->returntype:返回值類型。用追蹤返回類型形式聲明函數的返回值類型,沒有返回值時此部分可省略。返回值類型明確情況下,也可省略,由編譯器對返回類型進行推導。
{statement}:函數體。在該函數體內,除了可以使用其參數外,還可以使用所有捕獲到的變量。
注意:
在lambda函數定義中,參數列表和返回值類型都是可選部分,而捕捉列表和函數體可以為空。因此C++11中最簡單的lambda函數為:[]{}; 該lambda函數不能做任何事情。
int main()
{
// 最簡單的lambda表達式, 該lambda表達式沒有任何意義
[] {};
// 省略參數列表和返回值類型,返回值類型由編譯器推導為int
int a = 3, b = 4;
[=] {return a + 3; };
// 省略了返回值類型,無返回值類型
auto fun1 = [&](int c) {b = a + c; };
fun1(10)
cout << a << " " << b << endl;
// 各部分都很完善的lambda函數
auto fun2 = [=, &b](int c)->int {return b += a + c; };
cout << fun2(10) << endl;
// 復制捕捉x
int x = 10;
auto add_x = [x](int a) mutable { x *= 2; return a + x; };
cout << add_x(10) << endl;
return 0;
}通過上述例子可以看出,lambda表達式實際上可以理解為無名函數,該函數無法直接調用,如果想要直接調用,可借助auto將其賦值給一個變量。
捕獲列表說明:
捉列表描述了上下文中那些數據可以被lambda使用,以及使用的方式傳值還是傳引用。
[var]:表示值傳遞方式捕捉變量var
[=]:表示值傳遞方式捕獲所有父作用域中的變量(包括this)
[&var]:表示引用傳遞捕捉變量var
[&]:表示引用傳遞捕捉所有父作用域中的變量(包括this)
[this]:表示值傳遞方式捕捉當前的this指針
注意:
a. 父作用域指包含lambda函數的語句塊
b. 語法上捕捉列表可由多個捕捉項組成,并以逗號分割。比如:[=, &a, &b]:以引用傳遞的方式捕捉變量a和b,值傳遞方式捕捉其他所有變量[&,a, this]:值傳遞方式捕捉變量a和this,引用方式捕捉其他變量
c. 捕捉列表不允許變量重復傳遞,否則就會導致編譯錯誤。比如:[=, a]:=已經以值傳遞方式捕捉了所有變量,捕捉a重復
d. 在塊作用域以外的lambda函數捕捉列表必須為空。
e. 在塊作用域中的lambda函數僅能捕捉父作用域中局部變量,捕捉任何非此作用域或者非局部變量都會導致編譯報錯。
f. lambda表達式之間不能相互賦值,即使看起來類型相同
“C++11中的可變參數模板和lambda表達式怎么使用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





