溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“python3 chromedrivers簽到如何實現”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“python3 chromedrivers簽到如何實現”吧!
爬蟲一般是useragent,或者js腳本交互驗算的方式來反機器人爬蟲,只是很多反爬蟲容易被偵測出來容易被攔截,這里有個思路可以用webdrivers來驅動瀏覽器去爬蟲,這樣就可以繞過大多數的防爬機制(有些高級的防反爬蟲也不行,比如驗證碼,鼠標軌跡驗證等技術這樣chromedriver就不管用了)
第一下載安裝chrome瀏覽器并查明版本號。
┌──(kali?kali)-[~]
└─$ apt-get install google-chrome-stable
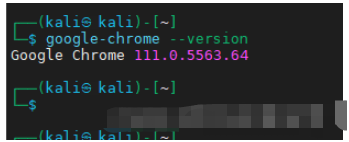
然后照著瀏覽器去下載相應的chromedriver

下載后解壓,將里面的chromedriver 復制到/usr/bin/ 目錄下面(pach環境變量里面)即可

下面開始寫腳本
from time import sleep
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
option = webdriver.ChromeOptions()
#設置chrome的瀏覽器選項
option.add_argument('--headless')
#設施chrome選項為無窗口運行
driver = webdriver.Chrome(chrome_options=option)
# 創建一個chrome瀏覽器,應用無窗口的配置。
driver.get("http://www.jsons.cn/ping/")
#用chrome去訪問網頁
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'txt_url')))
#讓chrome顯式等待driver這個對象,并最多等待10秒,當界面出現'txt_url'這個元素后在繼續往下
driver.find_element(By.XPATH, '//*[@id="txt_url"]').send_keys('ss111d.yqw5ey.dnslog.cn')
#再出現//*[@id="txt_url"]這個元素后往這個元素里面填入ss111d.yqw5ey.dnslog.cn這個數值
driver.find_element(By.XPATH, '//*[@id="startbtn"]').click()
#然后找到//*[@id="startbtn"] 這個按鈕模擬點擊它
sleep(1)
#等待一秒后退出find_element(By.XPATH, '//*[@id="txt_url"]') 這個元素怎么來的?如下:
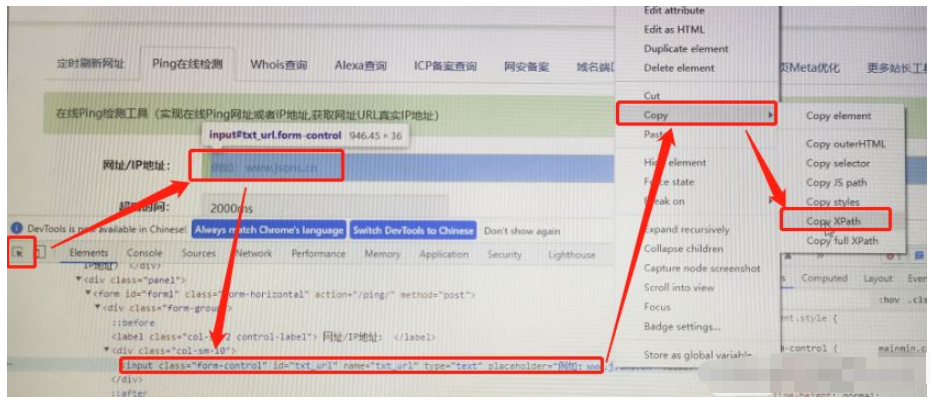
總的來說這個腳本就是用chrome 打開這個網站,然后輸入這個dnslog的網址去ping一下。模仿人點擊去測試網頁
其他:
下拉菜單如何選擇?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 創建一個 WebDriver 實例
driver = webdriver.Chrome()
# 訪問網頁
driver.get("https://example.com")
# 選擇下拉框元素
select_box = driver.find_element(By.ID, "my_select_box")
# 初始化 Select 類
select = Select(select_box)
# 選擇一個選項
select.select_by_value("option_value")
# 關閉 WebDriver 實例
driver.quit()在最新版本的 Selenium Python 包中,推薦使用 find_element 方法的新形式,即指定查找方式的參數 By,以及對應的選擇器表達式,具體有以下幾種用法:
通過元素 ID 查找元素:find_element(By.ID, id_)
通過元素 name 查找元素:find_element(By.NAME, name)
通過元素 class name 查找元素:find_element(By.CLASS_NAME, name)
通過元素標簽名查找元素:find_element(By.TAG_NAME, name)
通過元素鏈接文本查找元素:find_element(By.LINK_TEXT, text)
通過元素部分鏈接文本查找元素:find_element(By.PARTIAL_LINK_TEXT, text)
通過元素 CSS 選擇器查找元素:find_element(By.CSS_SELECTOR, css_selector)
通過元素 XPath 查找元素:find_element(By.XPATH, xpath)
感謝各位的閱讀,以上就是“python3 chromedrivers簽到如何實現”的內容了,經過本文的學習后,相信大家對python3 chromedrivers簽到如何實現這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





