溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“PostgreSQL數據庫性能調優的注意點及pg數據庫性能優化方法是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“PostgreSQL數據庫性能調優的注意點及pg數據庫性能優化方法是什么”吧!
優化思路:
0、為每個表執行 ANALYZE
然后分析 EXPLAIN (ANALYZE,BUFFERS) sql。
1、對于多表查詢,查看每張表數據,然后改進連接順序。
2、先查找那部分是重點語句,比如上面SQL,外面的嵌套層對于優化來說沒有意義,可以去掉。
3、查看語句中,where等條件子句,每個字段能過濾的效率。找出可優化處。
比如oc.order_id = oo.order_id是關聯條件,需要加索引
oc.op_type = 3 能過濾出1/20的數據,
oo.event_type IN (…) 能過濾出1/10的數據,
這兩個是優化的重點,也就是實現確保op_type與event_type已經加了索引,其次確保索引用到了。
盡量避免
排序的數據量盡量少,并保證在內存里完成排序。
(至于具體什么數據量能在內存中完成排序,不同數據庫有不同的配置:oracle是sort_area_size;postgresql是work_mem (integer),單位是KB,默認值是4MB。mysql是sort_buffer_size 注意:該參數對應的分配內存是每連接獨占!)
過濾的數據量比較少,一般來說<20%,應該走索引。20%-40% 可能走索引也可能不走索引。> 40% ,基本不走索引(會全表掃描)
保證值的數據類型和字段數據類型要一直。
對索引的字段進行計算時,必須在運算符右側進行計算。也就是 to_char(oc.create_date, ‘yyyyMMdd’)是沒用的
表字段之間關聯,盡量給相關字段上添加索引。
復合索引,遵從最左前綴的原則,即最左優先。(單獨右側字段查詢沒有索引的)
1、hash join
放內存里進行關聯。
適用于結果集比較大的情況。
比如都是200000數據
2、nest loop
從結果1 逐行取出,然后與結果集2進行匹配。
適用于兩個結果集,其中一個數據量遠大于另外一個時。
結果集一:1000
結果集二:1000000
在多表聯查時,需要考慮連接順序問題。
1、當postgresql中進行查詢時,如果多表是通過逗號,而不是join連接,那么連接順序是多表的笛卡爾積中取最優的。如果有太多輸入的表, PostgreSQL規劃器將從窮舉搜索切換為基因概率搜索,以減少可能性數目(樣本空間)。基因搜索花的時間少, 但是并不一定能找到最好的規劃。
2、對于JOIN
LEFT JOIN / RIGHT JOIN 會一定程度上指定連接順序,但是還是會在某種程度上重新排列:
FULL JOIN 完全強制連接順序。
如果要強制規劃器遵循準確的JOIN連接順序,我們可以把運行時參數join_collapse_limit設置為 1
主要有如下幾個方面。
EXPLAIN命令可以查看執行計劃,這個方法是我們最主要的調試工具。
由于統計信息不是每次操作數據庫都進行更新的,一般是在 VACUUM 、 ANALYZE 、 CREATE INDEX等DDL執行的時候會更新統計信息,
因此執行計劃所用的統計信息很有可能比較舊。 這樣執行計劃的分析結果可能誤差會變大。
以下是表tenk1的相關的一部分統計信息。
SELECT relname, relkind, reltuples, relpages FROM pg_class WHERE relname LIKE 'tenk1%';
| relname | relkind | reltuples | relpages |
|---|---|---|---|
| tenk1 | r | 10000 | 358 |
| tenk1_hundred | i | 10000 | 30 |
| tenk1_thous_tenthous | i | 10000 | 30 |
| tenk1_unique1 | i | 10000 | 30 |
| tenk1_unique2 | i | 10000 | 30 |
(5 rows)
其中 relkind是類型,r是自身表,i是索引index;reltuples是項目數;relpages是所占硬盤的塊數。
一般寫法:
SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;
如果明確用join的話,執行時候執行計劃相對容易控制一些。
例子:
SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id = b.id AND b.ref = c.id; SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);
(autocommit=false)
我們有的處理中要對同一張表執行很多次insert操作。這個時候我們用copy命令更有效率。因為insert一次,其相關的index都要做一次,比較花費時間。
有時候我們在備份和重新導入數據的時候,如果數據量很大的話,要很幾個小時才能完成。這個時候可以先把index刪除掉。導入在建index。
如果表的有外鍵的話,每次操作都沒去check外鍵整合性。因此比較慢。數據導入后在建立外鍵也是一種選擇。
增加這個參數可以提升CREATE INDEX和ALTER TABLE ADD FOREIGN KEY的執行效率。
增加這個參數可以提升大量數據導入時候的速度。
這個參數設置為無效的時候,能夠提升以下的操作的速度
CREATE TABLE AS SELECT
CREATE INDEX
ALTER TABLE SET TABLESPACE
CLUSTER等。
表中數據大量變化的時候建議執行VACUUM ANALYZE。
對生產運行的數據庫要用定時任務crontb執行如下操作:
psql -U username -d databasename -c "vacuum verbose analyze tablename;"
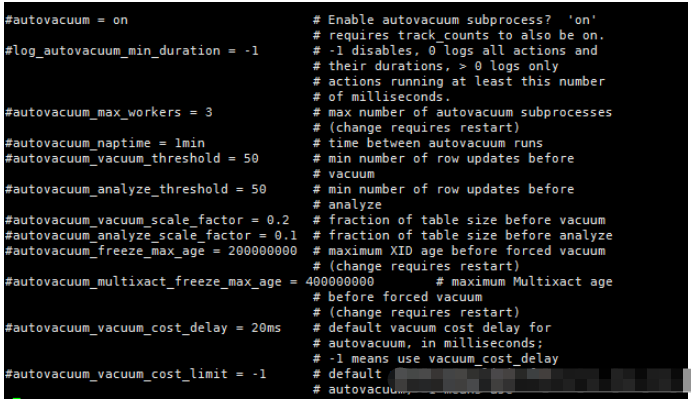
autovacuum: 默認為on,表示是否開起autovacuum。默認開起。特別的,當需要凍結xid時,盡管此值為off,PG也會進行vacuum。 autovacuum_naptime: 下一次vacuum的時間,默認1min。 這個naptime會被vacuum launcher分配到每個DB上。autovacuum_naptime/num of db。 log_autovacuum_min_duration: 記錄autovacuum動作到日志文件,當vacuum動作超過此值時。 “-1”表示不記錄。“0”表示每次都記錄。 autovacuum_max_workers: 最大同時運行的worker數量,不包含launcher本身。 autovacuum_work_mem: 每個worker可使用的最大內存數。 autovacuum_vacuum_threshold: 默認50。與autovacuum_vacuum_scale_factor配合使用,autovacuum_vacuum_scale_factor默認值為20%。當update,delete的tuples數量超過autovacuum_vacuum_scale_factor*table_size+autovacuum_vacuum_threshold時,進行vacuum。如果要使vacuum工作勤奮點,則將此值改小。 autovacuum_analyze_threshold: 默認50。與autovacuum_analyze_scale_factor配合使用。 autovacuum_analyze_scale_factor: 默認10%。當update,insert,delete的tuples數量超過autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold時,進行analyze。 autovacuum_freeze_max_age:200 million。離下一次進行xid凍結的最大事務數。 autovacuum_multixact_freeze_max_age: 400 million。離下一次進行xid凍結的最大事務數。 autovacuum_vacuum_cost_delay: 如果為-1,取vacuum_cost_delay值。 autovacuum_vacuum_cost_limit: 如果為-1,到vacuum_cost_limit的值,這個值是所有worker的累加值。
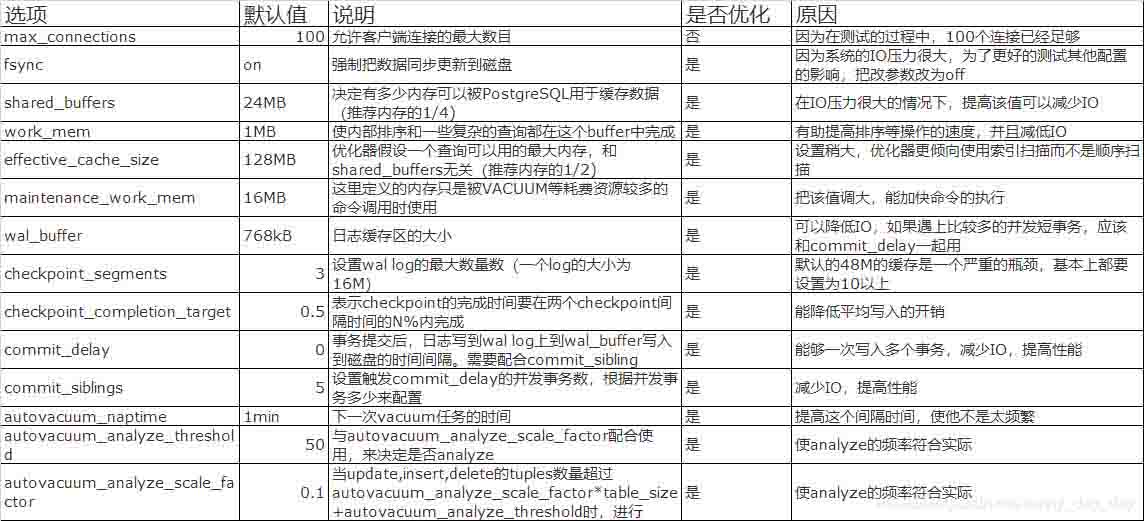
| 選項 | 默認值 | 說明 | 是否優化 | 原因 |
|---|---|---|---|---|
| max_connections | 100 | 允許客戶端連接的最大數目 | 否 | 因為在測試的過程中,100個連接已經足夠 |
| fsync | on | 強制把數據同步更新到磁盤 | 是 | 因為系統的IO壓力很大,為了更好的測試其他配置的影響,把改參數改為off |
| shared_buffers | 24MB | 決定有多少內存可以被PostgreSQL用于緩存數據(推薦內存的1/4) | 是 | 在IO壓力很大的情況下,提高該值可以減少IO |
| work_mem | 1MB | 使內部排序和一些復雜的查詢都在這個buffer中完成 | 是 | 有助提高排序等操作的速度,并且減低IO |
| effective_cache_size | 128MB | 優化器假設一個查詢可以用的最大內存,和shared_buffers無關(推薦內存的1/2) | 是 | 設置稍大,優化器更傾向使用索引掃描而不是順序掃描 |
| maintenance_work_mem | 16MB | 這里定義的內存只是被VACUUM等耗費資源較多的命令調用時使用 | 是 | 把該值調大,能加快命令的執行 |
| wal_buffer | 768kB | 日志緩存區的大小 | 是 | 可以降低IO,如果遇上比較多的并發短事務,應該和commit_delay一起用 |
| checkpoint_segments | 3 | 設置wal log的最大數量數(一個log的大小為16M) | 是 | 默認的48M的緩存是一個嚴重的瓶頸,基本上都要設置為10以上 |
| checkpoint_completion_target | 0.5 | 表示checkpoint的完成時間要在兩個checkpoint間隔時間的N%內完成 | 是 | 能降低平均寫入的開銷 |
| commit_delay | 0 | 事務提交后,日志寫到wal log上到wal_buffer寫入到磁盤的時間間隔。需要配合commit_sibling | 是 | 能夠一次寫入多個事務,減少IO,提高性能 |
| commit_siblings | 5 | 設置觸發commit_delay的并發事務數,根據并發事務多少來配置 | 是 | 減少IO,提高性能 |
| autovacuum_naptime | 1min | 下一次vacuum任務的時間 | 是 | 提高這個間隔時間,使他不是太頻繁 |
| autovacuum_analyze_threshold | 50 | 與autovacuum_analyze_scale_factor配合使用,來決定是否analyze | 是 | 使analyze的頻率符合實際 |
| autovacuum_analyze_scale_factor | 0.1 | 當update,insert,delete的tuples數量超過autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold時,進行analyze。 | 是 | 使analyze的頻率符合實際 |
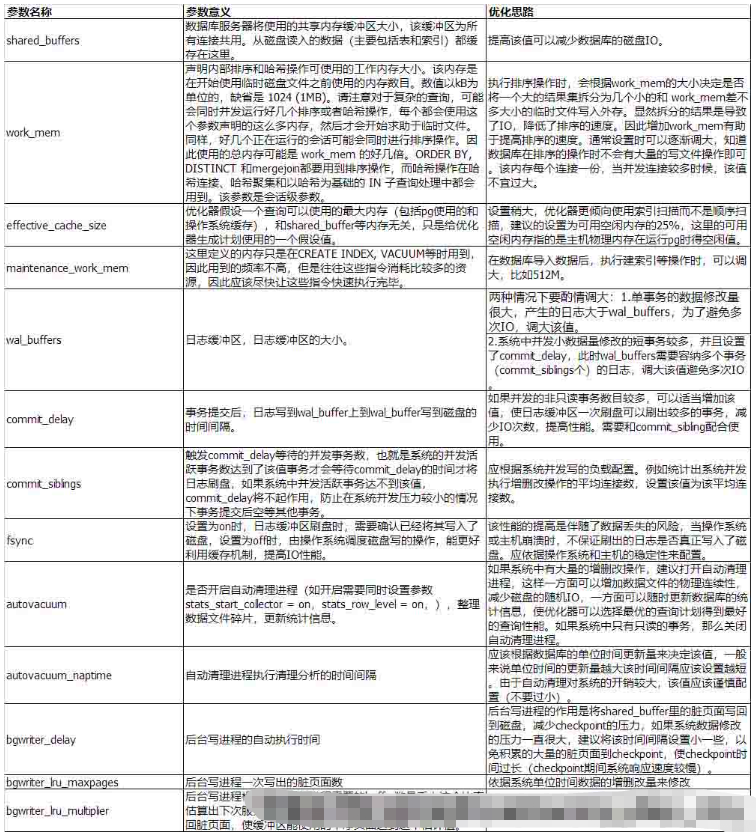
| 參數名稱 | 參數意義 | 優化思路 |
|---|---|---|
| shared_buffers | 數據庫服務器將使用的共享內存緩沖區大小,該緩沖區為所有連接共用。從磁盤讀入的數據(主要包括表和索引)都緩存在這里。 | 提高該值可以減少數據庫的磁盤IO。 |
| work_mem | 聲明內部排序和哈希操作可使用的工作內存大小。該內存是在開始使用臨時磁盤文件之前使用的內存數目。數值以kB為單位的,缺省是 1024 (1MB)。請注意對于復雜的查詢,可能會同時并發運行好幾個排序或者哈希操作,每個都會使用這個參數聲明的這么多內存,然后才會開始求助于臨時文件。同樣,好幾個正在運行的會話可能會同時進行排序操作。因此使用的總內存可能是 work_mem 的好幾倍。ORDER BY, DISTINCT 和mergejoin都要用到排序操作,而哈希操作在哈希連接、哈希聚集和以哈希為基礎的 IN 子查詢處理中都會用到。該參數是會話級參數。 | 執行排序操作時,會根據work_mem的大小決定是否將一個大的結果集拆分為幾個小的和 work_mem差不多大小的臨時文件寫入外存。顯然拆分的結果是導致了IO,降低了排序的速度。因此增加work_mem有助于提高排序的速度。通常設置時可以逐漸調大,知道數據庫在排序的操作時不會有大量的寫文件操作即可。該內存每個連接一份,當并發連接較多時候,該值不宜過大。 |
| effective_cache_size | 優化器假設一個查詢可以使用的最大內存(包括pg使用的和操作系統緩存),和shared_buffer等內存無關,只是給優化器生成計劃使用的一個假設值。 | 設置稍大,優化器更傾向使用索引掃描而不是順序掃描,建議的設置為可用空閑內存的25%,這里的可用空閑內存指的是主機物理內存在運行pg時得空閑值。 |
| maintenance_work_mem | 這里定義的內存只是在CREATE INDEX, VACUUM等時用到,因此用到的頻率不高,但是往往這些指令消耗比較多的資源,因此應該盡快讓這些指令快速執行完畢。 | 在數據庫導入數據后,執行建索引等操作時,可以調大,比如512M。 |
| wal_buffers | 日志緩沖區,日志緩沖區的大小。 | 兩種情況下要酌情調大:1.單事務的數據修改量很大,產生的日志大于wal_buffers,為了避免多次IO,調大該值。 |
| 2.系統中并發小數據量修改的短事務較多,并且設置了commit_delay,此時wal_buffers需要容納多個事務(commit_siblings個)的日志,調大該值避免多次IO。 | ||
| commit_delay | 事務提交后,日志寫到wal_buffer上到wal_buffer寫到磁盤的時間間隔。 | 如果并發的非只讀事務數目較多,可以適當增加該值,使日志緩沖區一次刷盤可以刷出較多的事務,減少IO次數,提高性能。需要和commit_sibling配合使用。 |
| commit_siblings | 觸發commit_delay等待的并發事務數,也就是系統的并發活躍事務數達到了該值事務才會等待commit_delay的時間才將日志刷盤,如果系統中并發活躍事務達不到該值,commit_delay將不起作用,防止在系統并發壓力較小的情況下事務提交后空等其他事務。 | 應根據系統并發寫的負載配置。例如統計出系統并發執行增刪改操作的平均連接數,設置該值為該平均連接數。 |
| fsync | 設置為on時,日志緩沖區刷盤時,需要確認已經將其寫入了磁盤,設置為off時,由操作系統調度磁盤寫的操作,能更好利用緩存機制,提高IO性能。 | 該性能的提高是伴隨了數據丟失的風險,當操作系統或主機崩潰時,不保證刷出的日志是否真正寫入了磁盤。應依據操作系統和主機的穩定性來配置。 |
| autovacuum | 是否開啟自動清理進程(如開啟需要同時設置參數stats_start_collector = on,stats_row_level = on,),整理數據文件碎片,更新統計信息。 | 如果系統中有大量的增刪改操作,建議打開自動清理進程,這樣一方面可以增加數據文件的物理連續性,減少磁盤的隨機IO,一方面可以隨時更新數據庫的統計信息,使優化器可以選擇最優的查詢計劃得到最好的查詢性能。如果系統中只有只讀的事務,那么關閉自動清理進程。 |
| autovacuum_naptime | 自動清理進程執行清理分析的時間間隔 | 應該根據數據庫的單位時間更新量來決定該值,一般來說單位時間的更新量越大該時間間隔應該設置越短。由于自動清理對系統的開銷較大,該值應該謹慎配置(不要過小)。 |
| bgwriter_delay | 后臺寫進程的自動執行時間 | 后臺寫進程的作用是將shared_buffer里的臟頁面寫回到磁盤,減少checkpoint的壓力,如果系統數據修改的壓力一直很大,建議將該時間間隔設置小一些,以免積累的大量的臟頁面到checkpoint,使checkpoint時間過長(checkpoint期間系統響應速度較慢)。 |
| bgwriter_lru_maxpages | 后臺寫進程一次寫出的臟頁面數 | 依據系統單位時間數據的增刪改量來修改 |
| bgwriter_lru_multiplier | 后臺寫進程根據最近服務進程需要的buffer數量乘上這個比率估算出下次服務進程需要的buffer數量,在使用后臺寫進程寫回臟頁面,使緩沖區能使用的干凈頁面達到這個估計值。 | 依據系統單位時間數據的增刪改量來修改。 |
到此,相信大家對“PostgreSQL數據庫性能調優的注意點及pg數據庫性能優化方法是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





