溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下怎么使用Python3+pycuda實現執行簡單GPU計算任務的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
GPU的加速技術在深度學習、量子計算領域都已經被廣泛的應用。其適用的計算模型是小內存的密集型計算場景,如果計算的模型內存較大,則需要使用到共享內存,這會直接導致巨大的數據交互的運算量,通信開銷較大。因為pycuda的出現,也使得我們可以直接在python內直接使用GPU函數,當然也可以直接在python代碼中集成一些C++的代碼,用于構建GPU計算的函數。
pycuda的安裝環境很大程度上取決約顯卡驅動本身是否能夠安裝成功,除了安裝pycuda庫本身之外,重點是需要確保如下的指令可以運行成功:
[dechin@dechin-manjaro pycuda]$ nvidia-smi
Sun Mar 21 20:26:43 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.45.01 Driver Version: 455.45.01 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce MX250 Off | 00000000:3C:00.0 Off | N/A |
| N/A 48C P0 N/A / N/A | 0MiB / 2002MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
上述返回的結果是一個沒有GPU任務情況下的展示界面,包含有顯卡型號、顯卡內存等信息。如果存在執行的任務,則顯示結果如下案例所示:
[dechin@dechin-manjaro pycuda]$ nvidia-smi
Sun Mar 21 20:56:04 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.45.01 Driver Version: 455.45.01 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce MX250 Off | 00000000:3C:00.0 Off | N/A |
| N/A 47C P0 N/A / N/A | 31MiB / 2002MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 18427 C python3 29MiB |
+-----------------------------------------------------------------------------+
我們發現這里多了一個pid為18427的python的進程正在使用GPU進行計算。在運算過程中,如果任務未能夠執行成功,有可能在內存中遺留一個進程,這需要我們自己手動去釋放。最簡單粗暴的方法就是:直接使用kill -9 pid來殺死殘留的進程。我們可以使用pycuda自帶的函數接口,也可以自己寫C++代碼來實現GPU計算的相關功能,當然一般情況下更加推薦使用pycuda自帶的函數。以下為一部分已經實現的接口函數,比如gpuarray的函數:
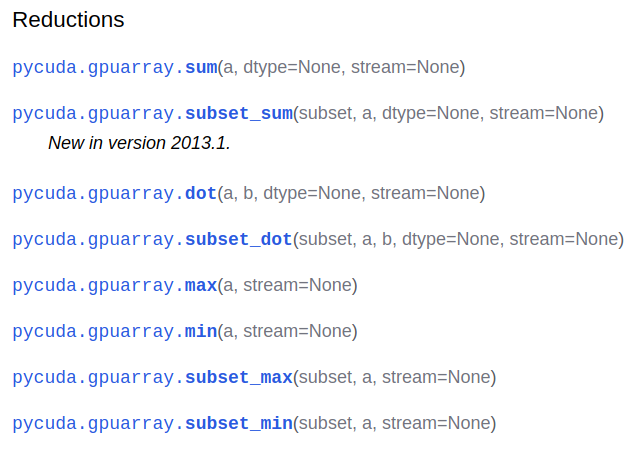
再比如cumath的函數:
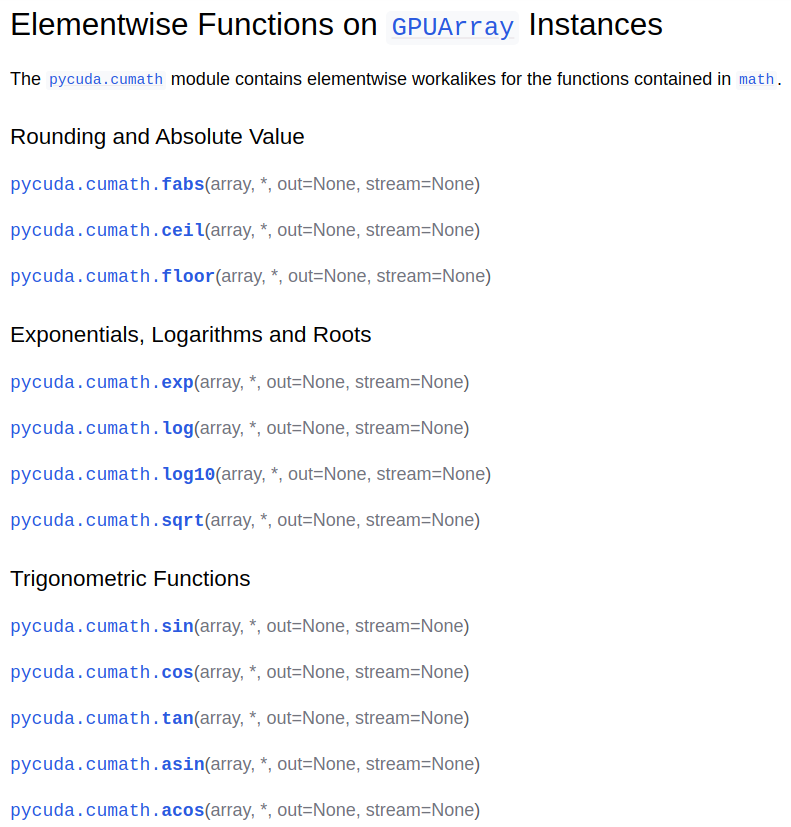
對于一個向量的指數而言,其實就是將每一個的向量元素取指數。當然,這與前面一篇關于量子門操作的博客中介紹的矩陣指數略有區別,這點要注意區分。
在下面的示例中,我們對比了numpy中實現的指數運算和pycuda中實現的指數運算。
# array_exp.py import pycuda.autoinit import pycuda.gpuarray as ga import pycuda.cumath as gm import numpy as np import sys if sys.argv[1] == '-l': length = int(sys.argv[2]) # 從命令行獲取參數值 np.random.seed(1) array = np.random.randn(length).astype(np.float32) array_gpu = ga.to_gpu(array) exp_array = np.exp(array) print (exp_array) exp_array_gpu = gm.exp(array_gpu) gpu_exp_array = exp_array_gpu.get() print (gpu_exp_array)
這里面我們計算一個隨機向量的指數,向量的維度length是從命令行獲取的一個參數,上述代碼的執行方式和執行結果如下所示:
[dechin@dechin-manjaro pycuda]$ python3 array_exp.py -l 5
[5.0750957 0.5423974 0.58968204 0.34199178 2.3759744 ]
[5.075096 0.5423974 0.58968204 0.34199178 2.3759747 ]
我們先確保兩者計算出來的結果是一致的,這里我們可以觀察到,兩個計算的結果只保障了7位的有效數字是相等的,這一點在大部分的場景下精度都是有保障的。接下來我們使用timeit來統計和對比兩者的性能:
# array_exp.py
import pycuda.autoinit
import pycuda.gpuarray as ga
import pycuda.cumath as gm
import numpy as np
import sys
import timeit
if sys.argv[1] == '-l':
length = int(sys.argv[2])
np.random.seed(1)
array = np.random.randn(length).astype(np.float32)
array_gpu = ga.to_gpu(array)
def npexp():
exp_array = np.exp(array)
def gmexp():
exp_array_gpu = gm.exp(array_gpu)
# gpu_exp_array = exp_array_gpu.get()
if __name__ == '__main__':
n = 1000
t1 = timeit.timeit('npexp()', setup='from __main__ import npexp', number=n)
print (t1)
t2 = timeit.timeit('gmexp()', setup='from __main__ import gmexp', number=n)
print (t2)這里也順便介紹一下timeit的使用方法:這個函數的輸入分別是:函數名、函數的導入方式、函數的重復次數。這里需要特別說明的是,如果在函數的導入方式中,不使用__main__函數進行導入,即使是本文件下的python函數,也是無法被導入成功的。在輸入的向量達到一定的規模大小時,我們發現在執行時間上相比于numpy有非常大的優勢。當然還有一點需要注意的是,由于我們測試的是計算速度,原本使用了get()函數將GPU中計算的結果進行導出,但是這部分其實不應該包含在計算的時間內,因此后來又注釋掉了。具體的測試數據如下所示:
[dechin@dechin-manjaro pycuda]$ python3 array_exp.py -l 10000000
26.13127974300005
3.469969915000547
以上就是“怎么使用Python3+pycuda實現執行簡單GPU計算任務”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





