溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“MySQL之join查詢如何優化”,在日常操作中,相信很多人在MySQL之join查詢如何優化問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”MySQL之join查詢如何優化”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
指定了聯接條件時,滿足查詢條件的記錄行數少的表為驅動表
未指定聯接條件時,行數少的表為驅動表(Important!)
如果你搞不清楚該讓誰做驅動表、誰 join 誰,就別指定誰 left/right join 誰了,請交給 MySQL優化器 運行時決定吧。
按經驗談,使用EXPLAIN, 第一行出現的表就是驅動表。
MySQL 表關聯的算法是 Nest Loop Join,是通過驅動表的結果集作為循環基礎數據,然后一條一條地通過該結果集中的數據作為過濾條件到下一個表中查詢數據,然后合并結果。
//例: user表10000條數據,class表20條數據 select * from user u left join class c u.userid=c.userid
上面sql的后果就是需要用user表循環10000次才能查詢出來,而如果用class表驅動user表則只需要循環20次就能查詢出來。
優化的目標是盡可能減少JOIN中Nested Loop的循環次數,以此保證:永遠用小結果集驅動大結果集。
排序的字段也有影響,有條原則:對驅動表可以直接排序,對非驅動表(的字段排序)需要對循環查詢的合并結果(臨時表)進行排序!
explain select * from user u left join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id WHERE 1=1 ORDER BY u.create_time DESC limit 0,10
夠復雜吧。假如,user表有千萬級記錄,class表要少得多,從執行計劃的得知驅動表(數據到千萬級)。由于動用了“LEFT JOIN”,所以相當于已經指定了驅動表。
如何優化?
//優化第一步:LEFT JOIN改為JOIN,對,直接 join! explain select * from user u join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id WHERE 1=1 ORDER BY u.create_time DESC limit 0,10 //優化第二步:從上面執行計劃得知, 有Using temporary(臨時表);Using filesort,解決方法是調整排序字段(借助前面講過排序的原則) explain select * from user u join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id WHERE 1=1 ORDER BY c.id DESC limit 0,10
總之,sql優化中explain工具是非常重要的武器。
#分類 CREATE TABLE IF NOT EXISTS `class` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`) ); #圖書 CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`bookid`) ); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));

看這個分析結果發現:在 class 表上添加的索引起的作用不大。
結論:
- **小表驅動大表**
- 小表:相對來說記錄較少的表
- 大表:相對來說記錄較多的表
- 驅動方式識別
left join:左邊驅動右邊(此時把小表放在左邊)
right join:右邊驅動左邊(此時把小表放在右邊)
- 加索引的方式:通常建議在大表(被驅動)的表加索引,效率提升更明顯。
- 原因:
原因1:被驅動表加了索引之后,收益更大。從 ALL -> ref
原因2:外連接首先讀取驅動表的全部數據,被驅動只讀取滿足連接條件的數據。
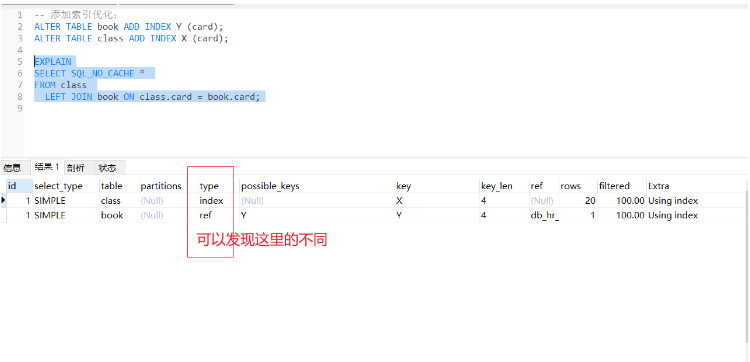
小結:
- 保證被驅動表的 join 字段被索引。join 字段就是作為連接條件的字段。
- left join 時,選擇小表作為驅動表(放左邊),大表作為被驅動表(放右邊)
- inner join 時,mysql 會自動將小結果集的表選為驅動表。
- 子查詢盡量不要放在被驅動表,衍生表建不了索引
- 能夠直接多表關聯的盡量直接關聯,不用子查詢
到此,關于“MySQL之join查詢如何優化”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





