溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“C++數據結構之哈希表如何實現”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“C++數據結構之哈希表如何實現”吧!
二叉搜索樹具有對數時間的表現,但這樣的表現建立在一個假設上:輸入的數據有足夠的隨機性。哈希表又名散列表,在插入、刪除、搜索等操作上具有「常數平均時間」的表現,而且這種表現是以統計為基礎,不需依賴輸入元素的隨機性。
聽起來似乎不可能,倒也不是,例如:
假設所有元素都是 8-bits 的正整數,范圍 0~255,那么簡單得使用一個數組就可以滿足上述要求。首先配置一個數組 Q,擁有 256 個元素,索引號碼 0~255,初始值全部為 0。每一個元素值代表相應的元素的出現次數。如果插入元素 i,就執行 Q[i]++,如果刪除元素 i,就執行 Q[i]--,如果查找元素 i,就看 Q[i] 是否為 0。
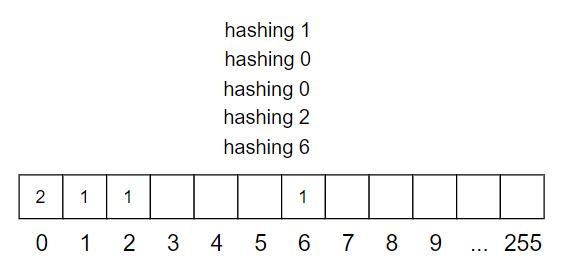
這個方法有兩個很嚴重的問題。
如果元素是 32-bits,數組的大小就是232=4GB,這就太大了,更不用說 64-bits 的數了
如果元素類型是字符串而非整數,就需要某種方法,使其可用作數組的索引
如何避免使用一個太大的數組,以及如何將字符串轉化為數組的索引呢?一種常見的方法就是使用某種映射函數,將某一元素映射為一個「大小可接受的索引」,這樣的函數稱為散列函數。
散列函數應有以下特性:
函數的定義域必須包含需要存儲的全部關鍵字,當散列表有 m 個地址時,其值域在 0 到 m - 1 之間
函數計算出來的地址能均勻分布在整個空間
取關鍵字的某個線性函數為散列地址:Hash(Key)=A∗Key+B
優點:簡單、均勻
缺點:需要事先知道關鍵字的分布情況
使用場景:數據范圍比較集中的情況
設散列表的索引個數為 m,取一個不大于 m,但最接近 m 的質數 p 最為除數,按照散列函數:Hash(Key)=key,將關鍵字轉化為哈希地址
假設關鍵字為 1230,它的平方是 1512900,取中間的 3 位 129 作為哈希地址;
再比如關鍵字為 321,它的平方是 103041,取中間的 3 位 304(或 30)作為哈希地址。
使用散列函數會帶來一個問題:可能有不同的元素被映射到相同的位置。這無法避免,因為元素個數大于數組的容量,這便是「哈希沖突」。解決沖突問題的方法有很有,包括線性探測、二次探測、開散列等。
當散列函數計算出某個元素的插入位置,而該位置上已有其他元素了。最簡單的方法就是向下一一尋找(到達尾端,就從頭開始找),直到找到一個可用位置。
進行元素搜索時同理,如果散列函數計算出來的位置上的元素值與目標不符,就向下一一尋找,直到找到目標值或遇到空。
至于元素的刪除,必須采用偽刪除,即只標記刪除記號,實際刪除操作在哈希表重新整理時再進行。這是因為哈希表中的每一個元素不僅表示它自己,也影響到其他元素的位置。
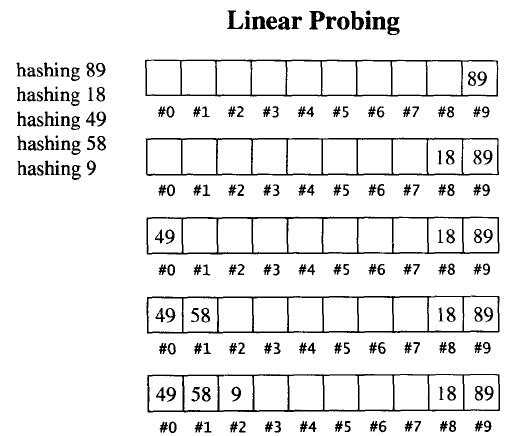
從上述插入過程我們可以看出,當哈希表中元素變多時,發生沖突的概率也變大了。由此,我們引出哈希表一個重要概念:負載因子。
負載因子定義為:Q = 表中元素個數 / 哈希表的長度
負載因子越大,剩余可用空間越少,發生沖突可能越大
負載因子越小,剩余可用空間越多,發生沖突可能越小,同時空間浪費更多
因此,控制負載因子是個非常重要的事。對于開放定址法(發生了沖突,就找下一個可用位置),負載因子應控制在 0.7~0.8 以下。超過 0.8,查找時的 CPU 緩存不命中按照指數曲線上升。
線性探測的缺陷是產生沖突的數據會堆在一起,這與其找下一個空位置的方式有關,它找空位置的方式是挨著往后逐個去找。二次探測主要用來解決數據堆積的問題,其命名由來是因為解決碰撞問題的方程式F(i)=i2是個二次方程式。
更具體地說,如果散列函數計算出新元素的位置為 H,而該位置實際已被使用,那么將嘗試H+12,H+22,H+32,...,H+i2,而不是像線性探測那樣依次嘗試H+1,H+2,H+3,...,H+i。
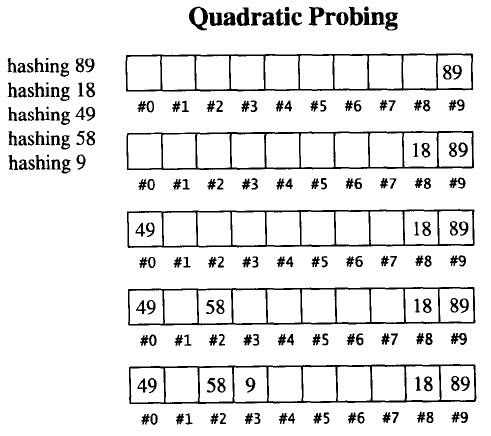
大量實驗表明:當表格大小為質數,而且保持負載因子在 0.5 以下(超過 0.5 就重新配置),那么就可以確定每插入一個新元素所需要的探測次數不超過 2。
這種方法是在每一個表格元素中維護一個鏈表,在呢個鏈表上執行元素的插入、查詢、刪除等操作。這時表格內的每個單元不再只有一個節點,而可能有多個節點。
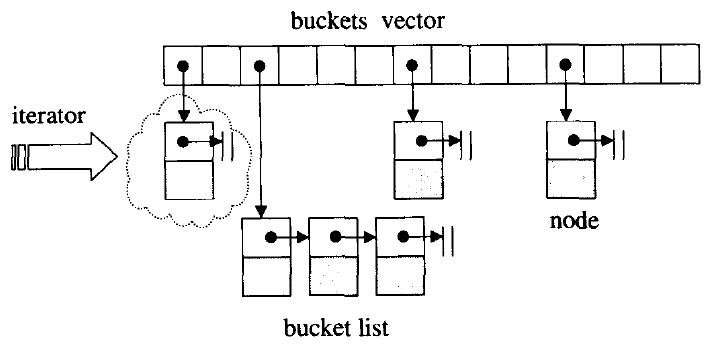
節點的定義:
template <class Value>
struct __hashtable_node {
__hashtable_node* next;
Value val;
};接口總覽
template <class K, class V>
class HashTable {
struct Elem {
pair<K, V> _kv;
State _state = EMPTY;
};
public:
Elem* Find(const K& key);
bool Insert(const pair<K, V>& kv);
bool Erase(const K& key);
private:
vector<Elem> _table;
size_t _n = 0;
};節點的結構
因為在閉散列的哈希表中的每一個元素不僅表示它自己,也影響到其他元素的位置。所以要使用偽刪除,我們使用一個變量來表示。
/// @brief 標記每個位置狀態
enum State {
EMPTY, // 空
EXIST, // 有數據
DELETE // 有數據,但已被刪除
};哈希表的節點結構,不僅存儲數據,還存儲狀態。
/// @brief 哈希表的節點
struct Elem {
pair<K, V> _kv; // 存儲數據
State _state; // 存儲狀態
};查找
查找的思路比較簡單:
利用散列函數獲取映射后的索引
遍歷數組看是否存在,直到遇到空表示查找失敗
/// @brief 查找指定 key
/// @param key 待查找節點的 key 值
/// @return 找到返回節點的指針,沒找到返回空指針
Elem* Find(const K& key) {
if (_table.empty()) {
return nullptr;
}
// 使用除留余數法的簡化版本,并沒有尋找質數
// 同時,該版本只能用于正整數,對于字符串等需使用其他散列函數
size_t start = key % _table.size();
size_t index = start;
size_t i = 1;
// 直到找到空位置停止
while (_table[index]._state != EMPTY) {
if (_table[index]._state == EXIST && _table[index]._kv.first == key) {
return &_table[index];
}
index = start + i;
index %= _table.size();
++i;
// 判斷是否重復查找
if (index == start) {
return nullptr;
}
}
return nullptr;
}在上面代碼的查找過程中,加了句用于判斷是否重復查找的代碼。理論上上述代碼不會出現所有的位置都有數據,查找不存在的數據陷入死循環的情況,因為哈希表會擴容,閉散列下負載因子不會到 1。
但假如,我們插入了 5 個數據,又刪除了它們,之后又插入了 5 個數據,將 10 個初始位置都變為非 EMPTY。此時我們查找的值不存在的話,是會陷入死循環的。
插入
插入的過程稍微復雜一些:
1.首先檢查待插入的 key 值是否存在
2.其次需要檢查是否需要擴容
3.使用線性探測方式將節點插入
/// @brief 插入節點
/// @param kv 待插入的節點
/// @return 插入成功返回 true,失敗返回 false
bool Insert(const pair<K, V>& kv) {
// 檢查是否已經存在
Elem* res = Find(kv.first);
if (res != nullptr) {
return false;
}
// 看是否需要擴容
if (_table.empty()) {
_table.resize(10);
} else if (_n > 0.7 * _table.size()) { // 變化一下負載因子計算,可以避免使用除法
HashTable backUp;
backUp._table.resize(2 * _table.size());
for (auto& [k, s] : _table) {
// C++ 17 的結構化綁定
// k 綁定 _kv,s 綁定 _state
if (s == EXIST) {
backUp.Insert(k);
}
}
// 交換這兩個哈希表,現代寫法
_table.swap(backUp._table);
}
// 將數據插入
size_t start = kv.first % _table.size();
size_t index = start;
size_t i = 1;
// 找一個可以插入的位置
while (_table[index]._state == EXIST) {
index = start + i;
index %= _table.size();
++i;
}
_table[index]._kv = kv;
_table[index]._state = EXIST;
++_n;
return true;
}刪除
刪除的過程非常簡單:
1.查找指定 key
2.找到了就將其狀態設為 DELETE,并減少表中元素個數
/// @brief 刪除指定 key 值
/// @param key 待刪除節點的 key
/// @return 刪除成功返回 true,失敗返回 false
bool Erase(const K& key) {
Elem* res = Find(key);
if (res != nullptr) {
res->_state = DELETE;
--_n;
return true;
}
return false;
}接口總覽
template <class K, class V>
class HashTable {
struct Elem {
Elem(const pair<K, V>& kv)
: _kv(kv)
, _next(nullptr)
{}
pair<K, V> _kv;
Elem* _next;
};
public:
Elem* Find(const K& key);
bool Insert(const pair<K, V>& kv);
bool Erase(const K& key);
private:
vector<Elem*> _table;
size_t _n = 0;
};節點的結構
使用鏈地址法解決哈希沖突就不再需要偽刪除了,但需要一個指針,指向相同索引的下一個節點。
/// @brief 哈希表的節點
struct Elem {
Elem(const pair<K, V>& kv)
: _kv(kv)
, _next(nullptr)
{}
pair<K, V> _kv; // 存儲數據
Elem* _next; // 存在下一節點地址
};查找
查找的實現比較簡單:
1.利用散列函數獲取映射后的索引
2.遍歷該索引位置的鏈表
/// @brief 查找指定 key
/// @param key 待查找節點的 key 值
/// @return 找到返回節點的指針,沒找到返回空指針
Elem* Find(const K& key) {
if (_table.empty()) {
return nullptr;
}
size_t index = key % _table.size();
Elem* cur = _table[index];
// 遍歷該位置鏈表
while (cur != nullptr) {
if (cur->_kv.first == key) {
return cur;
}
cur = cur->_next;
}
return nullptr;
}插入
開散列下的插入比閉散列簡單:
1.首先檢查待插入的 key 值是否存在
2.其次需要檢查是否需要擴容
3.將新節點以頭插方式插入
/// @brief 插入節點
/// @param kv 待插入的節點
/// @return 插入成功返回 true,失敗返回 false
bool Insert(const pair<K, V>& kv) {
// 檢查是否已經存在
Elem* res = Find(kv.first);
if (res != nullptr) {
return false;
}
// 檢查是否需要擴容
if (_table.size() == _n) {
vector<Elem*> backUp;
size_t newSize = _table.size() == 0 ? 10 : 2 * _table.size();
backUp.resize(newSize);
// 遍歷原哈希表,將所有節點插入新表
for (int i = 0; i < _table.size(); ++i) {
Elem* cur = _table[i];
while (cur != nullptr) {
// 取原哈希表的節點放在新表上,不用重新申請節點
Elem* tmp = cur->_next;
size_t index = cur->_kv.first % backUp.size();
cur->_next = backUp[index];
backUp[index] = cur;
cur = tmp;
}
_table[i] = nullptr;
}
_table.swap(backUp);
}
// 將新節點以頭插的方式插入
size_t index = kv.first % _table.size();
Elem* newElem = new Elem(kv);
newElem->_next = _table[index];
_table[index] = newElem;
++_n;
return true;
}刪除
開散列的刪除與閉散列有些許不同:
1.獲取 key 對應的索引
2.遍歷該位置鏈表,找到就刪除
/// @brief 刪除指定 key 值
/// @param key 待刪除節點的 key
/// @return 刪除成功返回 true,失敗返回 false
bool Erase(const K& key) {
size_t index = key % _table.size();
Elem* prev = nullptr;
Elem* cur = _table[index];
while (cur != nullptr) {
if (cur->_kv.first == key) {
if (prev == nullptr) {
// 是該位置第一個節點
_table[index] = cur->_next;
} else {
prev->_next = cur->_next;
}
delete cur; // 釋放該節點
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}到此,相信大家對“C++數據結構之哈希表如何實現”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





