溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“數據庫分庫分表后非分片鍵怎么查詢”,在日常操作中,相信很多人在數據庫分庫分表后非分片鍵怎么查詢問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”數據庫分庫分表后非分片鍵怎么查詢”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我們知道在分庫分表中對于toC業務來說,需要選擇用戶屬性如 user_id 作為分片鍵,不推薦使用order_id這樣的作為分片鍵。
那問題來了,對于訂單表來說,選擇了user_id作為分片鍵以后如何查看訂單詳情呢?比如下面這樣一條SQL:
SELECT * FROM T_ORDER WHERE order_id = 801462878019256325
由于查詢條件中的order_id不是分片鍵,所以需要查詢所有分片才能得到最終的結果。如果下面有 1000 個分片,那么就需要執行 1000 次這樣的 SQL,這時性能就比較差了。
可以通過ShardingSphere-JDBC生成的SQL得知,根據order_id查詢會對所有分片進行查詢然后通過UNION ALL進行合并。

但是,我們知道 order_id 是主鍵,應該只有一條返回記錄,也就是說,order_id 只存在于一個分片中。這時,可以有以下三種設計:
冗余數據法
索引表法
基因分片法
當然,這三種設計的本質都是通過冗余實現空間換時間的效果,否則就需要掃描所有的分片,當分片數據非常多,效率就會變得極差。
下面我們逐一分析。
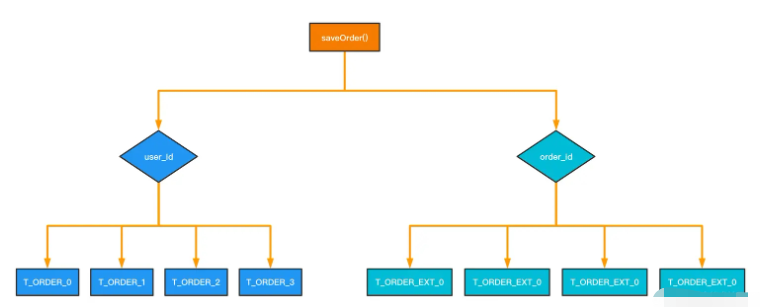
這種做法很容易理解,同一份訂單數據在插入時保存兩份,根據user_id 和 order_id分別做兩個分庫分表的實現。
通過對表進行冗余,對于 order_id 的查詢,只需要在 order_id = 801462878019256325 的分片中直接查詢就行,效率最高。但是這個方案設計的缺點又很明顯:冗余數據量太大。
索引表法是對第一種冗余法的改進,由于第一種方案冗余的數據量太大,所以索引表方案中只創建一個包含user_id和order_id的索引表,在插入訂單時再插入一條數據到索引表中。

表結構如下
CREATE TABLE idx_orderid_userid ( order_id bigint user_id bigint, PRIMARY KEY (order_id) )
在實現時可以將idx_orderid_userid表通過Redis緩存來代替,如果此表數據量很大也可以將其分庫分表,但是它的分片鍵是 order_id。
如果這時再根據字段 order_id 進行查詢,可以進行類似二級索引的回表實現:先通過查詢索引表得到記錄 order_id = 801462878019256325 對應的分片鍵 user_id 的值,接著再根據 user_id 進行查詢,最終定位到想要的數據,如:
原始SQL:
SELECT * FROM T_ORDER WHERE order_id = 801462878019256325
拆分后的SQL:
# step 1 SELECT user_id FROM idx_orderid_userid WHERE order_id = 801462890610556951 # step 2 SELECT * FROM T_ORDER WHERE user_id = ? AND order_id = 801462890610556951
這個例子是將一條 SQL 語句拆分成 2 條 SQL 語句,但是拆分后的 2 條 SQL 都可以通過分片鍵進行查詢,這樣能保證只需要在單個分片中完成查詢操作。不論有多少個分片,也只需要查詢 2個分片的信息,這樣 SQL 的查詢性能可以得到極大的提升。
通過索引表的方式,雖然存儲上較冗余全表容量小了很多,但是要根據另一個分片鍵進行數據的存儲,還是顯得不夠優雅。
因此,最優的設計,不是創建一個索引表,而是將分片鍵的信息保存在想要查詢的列中,這樣通過查詢的列就能直接知道所在的分片信息,這種方法也叫叫做基因法。
基因法的原理出自一個理論:對一個數取余2的n次方,那么余數就是這個數的二進制的最后n位數。
假如我們現在根據user_id進行分片,采用user_id % 16的方式來進行數據庫路由,這里的user_id%16,其本質是user_id的最后4個bit位 log(16,2) = 4 決定這行數據落在哪個分片上,這4個bit就是分片基因。
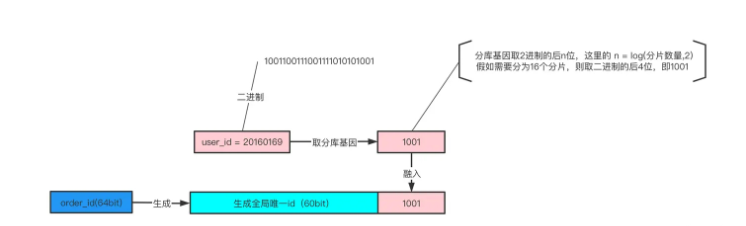
如上圖所示,user_id=20160169的用戶創建了一個訂單(20160169的二進制表示為:1001100111001111010101001)
使用user_id%16分片,決定這行數據要插入到哪個分片中
分庫基因是user_id的最后4個bit,log(16,2) = 4,即1001
在生成order_id時,先使用一種分布式ID生成算法生成前60bit(上圖中綠色部分)
將分庫基因加入到order_id的最后4個bit(上圖中粉色部分)
拼裝成最終的64bit訂單order_id(上圖中藍色部分)
這樣保證了同一個用戶創建的所有訂單都落到了同一個分片上,order_id的最后4個bit都相同,于是:
通過user_id %16 能夠定位到分片
通過order_id % 16也能定位到分片
不好理解的話,可以看下面這段代碼:
@Test
public void modIdTest(){
long userID = 20160169L;
//分片數量
int shardNum = 16;
String gen = getGen(userID, shardNum);
log.info("userID:{}的基因為:{}",userID,gen);
long snowId = IdWorker.getId(Order.class);
log.info("雪花算法生成的訂單ID為{}",snowId);
Long orderId = buildGenId(snowId,gen);
log.info("基因轉換后的訂單ID為{}",orderId);
Assert.assertEquals(orderId % shardNum , userID % shardNum);
}運行結果如下:

原始訂單ID為1595662702879973377,通過基因轉換后ID變成了1595662702879973385,對于用戶id 和 新生成的訂單id對其取模結果一樣。
上面那種做法是基因替換,替換掉訂單id的分片基因。下面這種做法就更顯直接。
將訂單表 orders 的主鍵設計為一個字符串,這個字符串中最后一部分包含分片鍵的信息,如:
order_id = string(order_id + user_id)
那么這時如果根據 order_id 進行查詢:
SELECT * FROM T_ORDER WHERE order_id = '1595662702879973377-20160169';
由于字段 order_id 的設計中直接包含了分片鍵信息,所以我們可以直接通過分片鍵部分直接定位到分片上。
同樣地,在插入時,由于可以知道插入時 user_id 對應的值,所以只要在業務層做一次字符的拼接,然后再插入數據庫就行了。
這樣的實現方式較冗余表和索引表的設計來說,效率更高,查詢時可以直接定位到數據對應的分片信息,只需 1 次查詢就能獲取想要的結果。
這樣實現的缺點是,主鍵值會變大一些,存儲也會相應變大。但是只要主鍵值是有序的,插入的性能就不會變差。而通過在主鍵值中保存分片信息,卻可以大大提升后續的查詢效率,這樣空間換時間的設計,總體上看是非常值得的。
實際上淘寶的訂單號也是這樣構建的

上圖是我的淘寶訂單信息,可以看到,訂單號的最后 6 位都是 607041,所以可以大概率推測出:
淘寶訂單表的分片鍵是用戶 ID;
淘寶訂單表,訂單表的主鍵包含用戶 ID,也就是分片信息。這樣通過訂單號進行查詢,可以獲得分片信息,從而查詢 1 個分片就能得到最終的結果。
到此,關于“數據庫分庫分表后非分片鍵怎么查詢”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





