溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“java分布式流式處理組件Producer分區的作用是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“java分布式流式處理組件Producer分區的作用是什么”吧!
合理的使用存儲資源:把海量的數據按照分區切割成一小塊的數據存儲在多臺Broker上。此時能夠保證每臺服務器存儲資源能夠被充分利用到。而且小塊數據在尋址時間上更有優勢~
如果將全部的數據存儲在一臺機器上,那么要對當前數據做副本的時候,由于服務器資源配置不同,就有可能會出現副本數據存放失敗,從而增加數據丟失的可能性。
同時,如果單個文件過大,副本放置時間、內容檢索時間都會極大的延長,從而導致Kafka性能降低。
負載均衡: 數據生產或消費期間,生產者已分區的單位發送數據,消費者分區的單位進行消費。 期間,各分區生產和消費數據互不影響,這樣能夠達到合理控制分區任務的程度,提高任務的并行度。從而達到負載均衡的效果。
剛才我們提到:生產者已分區為單位向Broker發送數據。那么問題來了:
生產者是怎么知道該向哪個分區發送數據呢?
這就是我們接下來要研究的分區策略。
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
// 如果在消息中指定了分區
if (record.partition() != null)
return record.partition();
if (partitioner != null) {
// 分區器通過計算得到分區
int customPartition = partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
if (customPartition < 0) {
throw new IllegalArgumentException(String.format(
"The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition));
}
return customPartition;
}
// 通過序列化key計算分區
if (serializedKey != null && !partitionerIgnoreKeys) {
// hash the keyBytes to choose a partition
return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size());
} else {
// 返回-1
return RecordMetadata.UNKNOWN_PARTITION;
}
}下面的代碼可以說是整個分區器的核心部分,可以通過以下的步驟進行說明:
如果在生產消息的時候,已經指定了需要發送的分區位置,那么就會直接使用已經指定的份具體的位置,這樣子還節省了也不計算的時間
如果在生產者配置Properties中指定了分區策略類,那么消息生產就會通過已經指定的分區策略類進行分區計算
否則就會以serializedKey作為參數,通過hash取模的方式計算。如果serializedKey == null,那么就會采用粘性分區的邏輯。 這在Kafka中屬于默認分區器。
如果以上情況都沒有包含,那么他就會直接返回-1。相當于ack=0的情況。
在Kafka中分區策略我們是可以自定義的。當然Kafka也為我們內置了三種分區策略類。 接下來我們挑個重點來介紹,來給我們自定義分區器做一個鋪墊~

我們已經看到,DefaultPartitioner和UniformStickyPartitioner已經被標注為過期類,當然也并不妨礙我們來了解一下。
在當前版本中,如果沒有對partitioner.class進行配置,此時的分區策略就會采用當前類作為默認分區策略類。
而以下是DefaultPartitioner策略類的核心實現方式,并且標記部分的代碼實現其實就是UniformStickyPartitioner的計算邏輯
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
if (keyBytes == null) {
// 就是這段屬于UniformStickyPartitioner的實現邏輯
return stickyPartitionCache.partition(topic, cluster);
}
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}還有一段代碼讓我們來一起看看
public static int partitionForKey(final byte[] serializedKey, final int numPartitions) {
return Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;
}這段代碼不管有多復雜,調用方法有多少,但最終我們是能夠發現:
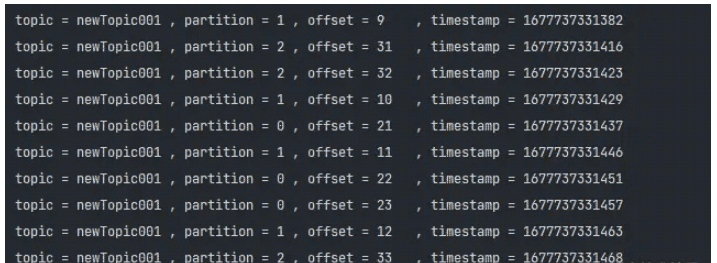
它的本質其實是在對序列化Key做哈希計算,然后通過hash值和分區數做取模運算,然后得到結果分區位置
這是一種比較重要的計算方式,但卻不是唯一的方式
---這是分割線---
接下來繼續,我們看看如果無法對序列化Key計算,會是怎么樣的計算邏輯?
我們先開始來看一下,是在哪個地方得到的serializedKey,并且什么情況下serializedKey會是NULL
看看下面的這個代碼眼熟不?
// 生產者生產消息對象 ProducerRecord<String, String> record = new ProducerRecord<>( "newTopic001", "data from " + KafkaQuickProducer.class.getName() );
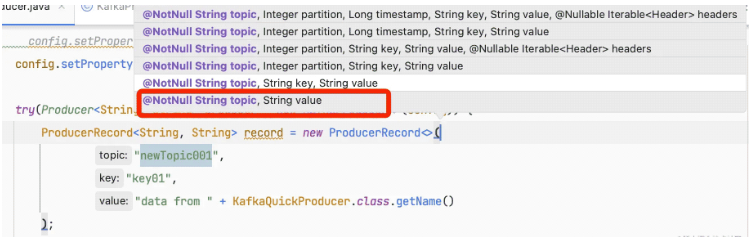
// KafkaProducer#doSend() // line994 serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
public class StringSerializer implements Serializer<String> {
// 省略。。。
@Override
public byte[] serialize(String topic, String data) {
if (data == null) {
return null;
} else {
return data.getBytes(encoding);
}
}
}從上面的代碼來看,基本上能夠實錘了:
當在生成ProducerRecord對象的時候,如果沒有對消息設置key參數,此時序列化之后的key就是個null
那么當序列化之后的Key為NULL之后,此時分區計算邏輯就會改變。
此時相當于我們已經進入到UniformStickyPartitioner的計算邏輯, 當然了在我們使用的3.3版本中當前類也已經被標注為過期
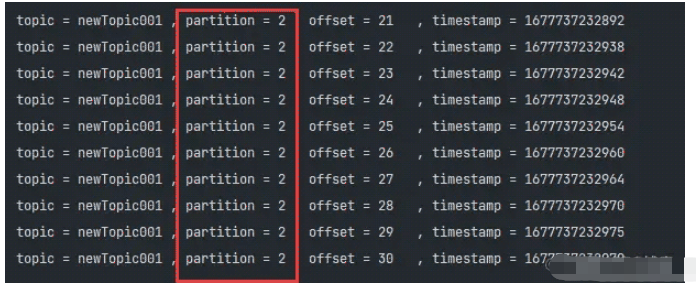
根據前面的說法,粘性分區主要解決了消息無Key的分區計算邏輯,那么粘性分區并不是說每次都使用同一個分區
它是通過一個大的Batch為單位,盡量將batch內的消息固定在同一個分區內,這樣在很大程度上能夠保證:
防止消息無規律的分散在不同的分區內,降低分區傾斜
同時不需要每次進行分區計算,也降低了Producer的延遲
而實現方式是采用ConcurrentMap來進行緩存,感興趣的大家可以看看StickyPartitionCache的源碼
而當Batch內消息滿足發送條件被發送出去之后,才會開始再次計算下一個分區,為此在KafkaProducer中還專門調用了新的方法
partitioner.onNewBatch(topic, cluster, prevPartition);
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
這是在當前版本中唯一沒有被標注的類,未來說不定會成為默認分區策略類,我們不看,就瞄一眼
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.computeIfAbsent(topic, k -> new AtomicInteger(0));
return counter.getAndIncrement();
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
}這個類的解釋,嗯。。你們看那個合適吧~

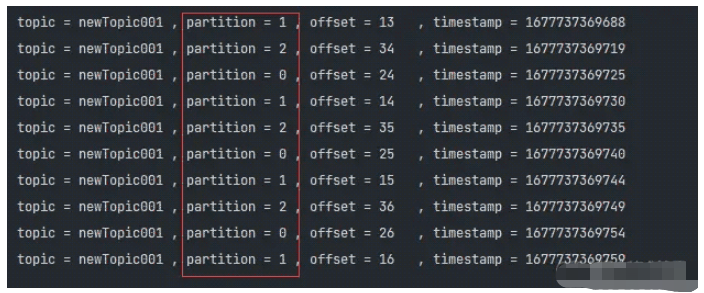
其實這個邏輯非常簡單:
通過AtomicInteger.getAndIncrement()的方式將每次寫入平均分配到不同的分區中
不同與其他分區策略類,它不關心Key是否為NULL
我們先來做個小實驗吧: 將分區策略類修改為RoundRobinPartitioner,也方便后續自定義分區器的配置操作
config.setProperty( ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );
就這樣就能實現,看結果驗證~
中間穿插了一點小知識,那么接下來就會進入到我們最后一個環節:嘗試自定義分區器
前面我們也提到過,相信大家沒有忘記partitioner.class這個配置
那么接下來就進入到重頭戲:自定義分區器實戰編碼環節。
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
// nothing
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 如果keyBytes == null
// 直接去0號位置
if (null == keyBytes) {
return 0;
}
// 已默認分區策略實現
int numPartitions = cluster.partitionsForTopic(topic).size();
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}
@Override
public void close() {
// nothing
}
}我們就先做的簡單一點,主要是想讓大家明白自定義分區器的實現:
如果沒有給定指定key,那么就默認全部去0號分區
否則就通過key做取模計算
當自定義分區器實現完成之后,接下來我們就需要通過發送者進行驗證。當然了,主要還是通過partitioner.class進行修改
// 給出關鍵代碼,其他的都是一樣的。就不贅述了~~~ config.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, "top.zopx.kafka.partitioner.CustomPartitioner");
通過執行之后,我們來看看它的運行效果是否滿足我們的預期
另一種運行結果與默認分區器有Key的情況類似,這里就不再重復貼圖
感謝各位的閱讀,以上就是“java分布式流式處理組件Producer分區的作用是什么”的內容了,經過本文的學習后,相信大家對java分布式流式處理組件Producer分區的作用是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





