溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“C++ vector的基本使用方法是什么”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“C++ vector的基本使用方法是什么”文章能幫助大家解決問題。
1.vector底層也是用動態順序表實現的,和string是一樣的,但是string默認存儲的就是字符串,而vector的功能較為強大一些,vector不僅能存字符,理論上所有的內置類型和自定義類型都能存,vector的內容可以是一個自定義類型的對象,也可以是一個內置類型的變量。
2.vector在使用時需要進行類模板的實例化,因為傳遞的模板參數不同,則vector存儲的元素類型就會有變化,所以在使用vector的時候要進行類模板的顯式實例化。
類模板的第二個參數是空間配置器,這個學到后面再說,而且這個參數是有缺省值的,我們只用這個缺省值就歐克了,所以在使用vector時,只需要關注第一個參數即可。

void test_vector1()
{
string s;
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//string和vector底層都是用數組實現的,所以他們都支持迭代器、范圍for、下標+[]的遍歷方式
for (size_t i = 0; i < v.size(); i++)
{
cout << v[i] << " ";//string和vector的底層都是數組,所以可以使用[],但list就不能使用[]了,所以萬能的方法是迭代器。
}
cout << endl;
vector<int>::iterator it = v.begin();//iterator實際是某種類型的重定義,在使用時要指定好類域。
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : v)//不就是迭代器嗎?
{
cout << e << " ";
}
cout << endl;
cout << v.max_size() << endl;//int是10億多,因為int占4個字節,42億÷4。
cout << s.max_size() << endl;//max_size的大小是數據的個數,我的編譯器的char是21億多。不用管他,這接口沒價值。
//vector<char> vstr;
//string str;
//vector<char>不能替代string,即使兩者都是字符數組也不行,因為string有\0
}1.對于string和vector,reserve和resize是獨有的,因為他們的底層都是動態順序表實現的,list就沒有reserve和resize,因為他底層是鏈表嘛。
2.對于reserve這個函數來說,官方并沒有將其設定為能夠兼容實現縮容的功能,明確規定這個函數在其他情況下,例如預留空間要比當前小的情況下,這個函數的調用是不會引起空間的重新分配的,也就是說容器vector的capacity是不會被影響的。

3.有的人可能認為縮容只要丟棄剩余的空間就好了,但其實沒有那么簡單,你從C語言階段free空間不能分兩次free進行釋放就可以看出來,一塊已經申請好的空間就是一塊兒獨立的個體,不能說你保留空間的一部分丟棄剩余的一部分,這樣是不行的,本質上和操作系統的內存管理有關系,如果對這部分知識有興趣,可以下去研究一下。
4.但值得注意的是縮容表面看起來是降低了空間的使用率,想要提高程序的效率,但實際上并未提高效率,縮容是需要異地縮容的,需要重新開空間和拷貝數據,代價不小,所以平常不建議對空間進行縮容。

5.vector的resize和string的resize同樣具有三種情況,但vector明顯功能比string要更健壯一些,string類型只能針對于字符,而vector在使用resize進行初始化空間數據時,對內置類型和自定義類型均可以調用對應的拷貝構造來初始化,所以其功能更為健壯,默認將整型類型初始化為0,指針類型初始化為空指針。

void test_vector2()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
//resize和reserve對于vector和string是獨有的,對于list而言,就沒有reserve和resize
cout << v.capacity() << endl;
v.reserve(10);
cout << v.capacity() << endl;
v.reserve(4);
cout << v.capacity() << endl;//并不會縮容,縮容并不會提高效率,縮容是有代價的,某種程度上就是以空間換時間。
v.resize(8);//int、指針這些內置類型的默認構造就把他們初始化為0和空指針這些。
v.resize(15, 1);
v.resize(3);//不縮容,也是采用惰性刪除的方式,將size調整為3就可以了,顯示數組內容的時候按照size大小顯示就可以了。
}1.在vs上擴容機制采用1.5倍的大小,g++上采用2倍的大小,對于空間的擴容,如果開大了會造成空間浪費,開小了不夠用,又會導致頻繁擴容帶來性能的損耗,而2倍的大小可以說是剛剛好,至于微軟的工程師為什么選擇1.5來進行擴容,是由于內存的某種對其因素導致。
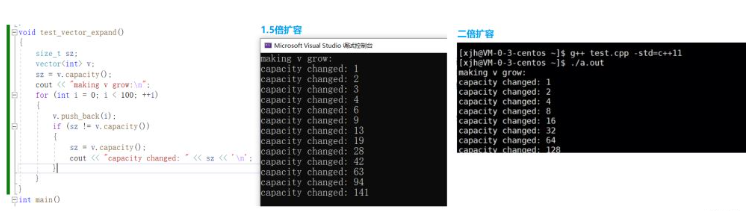
void test_vector_expand()//擴容機制大概是1.5倍進行擴容
{
size_t sz;
vector<int> v;
//v.reserve(100);//已知開辟空間大小時,我們應該調用reserve來提前預留空間,進行擴容。
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}1.對于reserve的設計理念就是不去縮容,就算手動調用reserve進行縮容,編譯器也不會理你,空間的大小始終都不會變,capacity的值一直是不動的,這樣的設計理念本質上就是用空間來換時間,因為異地縮容需要開空間和拷貝數據,比較浪費時間。
2.相反shrink_to_fit就是縮容函數,強制性的將capacity的大小降低到適配size大小的值,它的設計理念就是以空間來換時間,但日常人們所使用的手機或者PC空間實際上是足夠的,不夠的是時間,所以這種函數還是不要使用的為好,除非說你后面肯定不會插入數據了,不再進行任何modify操作,那你可以試著將空間還給操作系統,減少空間的使用率。
void test_vector7()
{
vector<int> v;
v.reserve(10);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
cout << v.size() << endl;
cout << v.capacity() << endl;
//C++不會太推薦使用malloc來進行空間的初始化了,因為很有可能存在自定義類型對象沒有初始化的問題,如果用new會自動調用構造。
//設計理念就是不去縮容,因為異地縮容的代價很大,所以就算你用reserve或是resize調整大小以改變capacity,但編譯器不會管你。
// 因為它的設計理念不允許它這么做,而遇到shrink_to_fit就沒轍了,因為他是縮容函數!!!
//---不動空間,不去縮容,以空間換時間的設計理念,因為縮容雖然空間資源多了,但是時間就長了,為了提高時間,就用空間換。
//shrink_to_fit就是反面的函數,進行了縮容。
v.reserve(3);
cout << v.size() << endl;
cout << v.capacity() << endl;
//設計理念:以時間換空間,一般縮容都是異地縮容,代價不小,一般不要輕易使用。通常情況下,我們是不缺空間的,缺的是時間。
v.shrink_to_fit();//縮容函數,代價很大,通常的縮容的方式,就是找一塊新的較小的空間,然后將原有數據拷貝進去
v.resize(3);
cout << v.size() << endl;
cout << v.capacity() << endl;
v.clear();//clear都是不動空間的
}楊輝三角
1.對于C語言實現的話,需要一個返回值和兩個輸出型參數來返回到后臺接口里面,第一個參數代表二維數組的大小,這道題我們知道返回的二維數組的大小,但其他題是有可能不知道的,而leetcode的后臺測試用例是統一設計的,為了兼容其他不知道返回數組大小的題目,這里統一使用了輸出型參數來控制。第二個參數的原因也是如此。
2.二維數組、二維數組里面的元素、需要返回二維數組里面的一維數組的元素個數,這些數組都需要malloc出來。
//后臺實現的地方:int returnSize=0;int returnColumnSizes[];
//grenerate(num,&returnSize,&returnColumnSizes);//函數調用
int** generate(int numRows, int* returnSize, int** returnColumnSizes)
{
int** p = (int**)malloc(numRows * sizeof(int*));
*returnSize = numRows;
*returnColumnSizes = (int*)malloc(sizeof(int) * numRows);
for (int i = 0; i < numRows; i++)
{
p[i] = (int*)malloc(sizeof(int) * (i + 1));//給每一個二維數組的元素動態開辟一個空間
(*returnColumnSizes)[i] = i + 1;
p[i][0] = p[i][i] = 1;
//for(int j = i; j < i + 1; j++)//條件控制有問題
//for (int j = 0; j < i + 1 ; j++)
for (int j = 1; j < i ; j++)
{
if (p[i][j]!=1)
{
p[i][j]=p[i-1][j-1]+p[i-1][j];
}
}
}
return p;
}3.對于vector來講的話,動態開辟就不需要我們自己做,通過resize就可以控制容器的空間大小,不用malloc動態開辟了,所以對于動態開辟的二維數組來講,vector實際上要簡便許多。
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
vv.resize(numRows);
//第二個參數不傳就是匿名對象,會自動調用容器中元素的構造函數。內置類型或自定義類型的構造。
for(size_t i=0; i<vv.size(); i++)
{
vv[i].resize(i+1, 0);//給每一個vector<int>容器預留好空間并進行初始化
vv[i][0] = vv[i][vv[i].size() - 1] = 1;
}
for(int i=0; i<vv.size(); i++)
{
for(int j=0; j<vv[i].size(); j++)
{
if(vv[i][j]==0)
{
vv[i][j]=vv[i-1][j]+vv[i-1][j-1];
}
}
}
return vv;
}
};1.下面所展示的代碼是比較經典的錯誤,就是我們用reserve擴容之后,就利用[]和下標來進行容器元素的訪問,擴容之后空間的使用權確實屬于我們,但是operator[]的越界訪問檢查機制,導致了我們程序的崩潰,assert(pos<size),所以對于元素的訪問,是要用resize來進行size的調整的,而reserve的主要作用是用來提前預留空間,在空間不夠使用的情況下進行調用,所以這里使用的情景有些不搭。
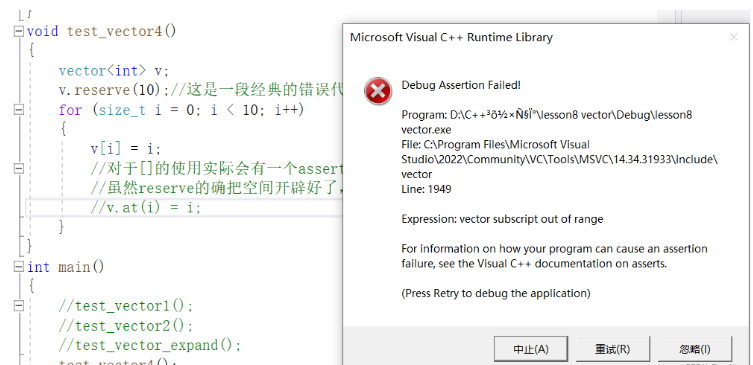
2.對于at的使用,所采用的越界訪問檢查機制是拋異常,catch捕獲異常之后,我們可以將異常信息打印出來,可以看到異常信息是無效的vector下標,指的也是所傳下標是無用的,實際就是下標位置超過了size。
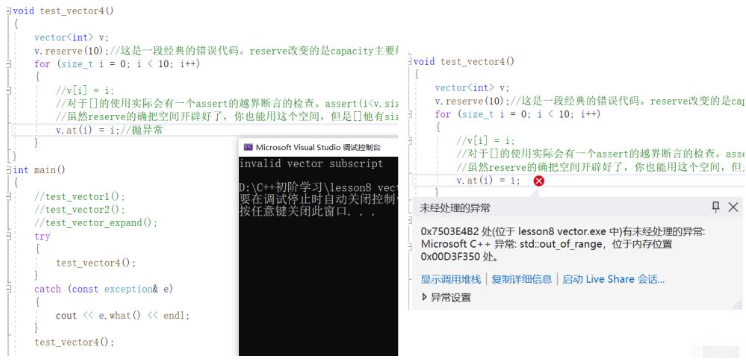
void test_vector4()
{
vector<int> v;
v.reserve(10);
//這是一段經典的錯誤代碼。reserve改變的是capacity主要解決的是插入數據時涉及到的擴容問題。
//resize改變的是size,平常對于vector的容量增加,還是resize多一點,resize可以直接包攬reserve的活,并且除此之外還能初始化空間。
for (size_t i = 0; i < 10; i++)
{
//v[i] = i;
//對于[]的使用實際會有一個assert的越界斷言的檢查。assert(i<v.size()),你的下標不能超過size。
//雖然reserve的確把空間開辟好了,你也能用這個空間,但是[]他有size和下標的越界檢查,所以你的程序就會報錯。
//reserve=開空間+初始化(有默認值)
v.at(i) = i;//拋異常
//斷言報錯真正的問題是在于,release版本下面,斷言就失效了,斷言在release版本下面是不起作用的。
}
}
int main()
{
//test_vector1();
//test_vector2();
//test_vector_expand();
try
{
//test_vector6();
}
catch (const exception& e)
{//在這個地方捕獲異常然后進行打印
cout << e.what() << endl;//報錯valid vector subscript,無效的vector下標
}
//test_vector4();
//test_vector5();
//test_vector6();
test_vector7();
//string算是STL的啟蒙,string的源碼我們就不看了
return 0;
}1.assign有兩種使用方式,一種是用n個value來進行容器元素的覆蓋,一種是用迭代器區間的元素來進行容器元素的覆蓋,這里的迭代器采用模板形式,因為迭代器類型不僅僅可能是vector類型,也有可能是其他容器類型,所以這里采用模板泛型的方式。
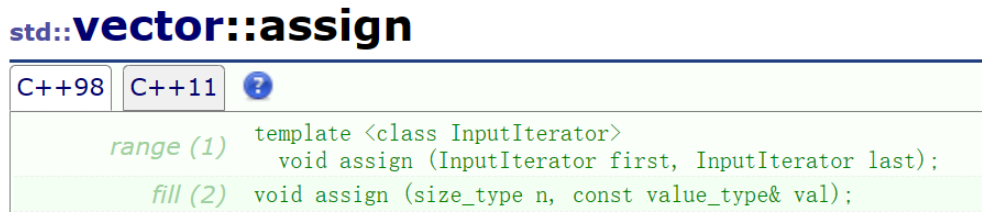
2.而且迭代器使用起來實際是非常方便的,由于vector的底層是連續的順序表,所以我們可以通過指針±整數的方式來控制迭代器賦值的區間,所以采用迭代器作為參數是非常靈活的。
void test_vector5()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
//void assign(size_type n, const value_type & val);前后類型分別為size_t和模板參數T的類型typedef,那就是int類型
v.assign(10, 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
vector<int> v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
//template <class InputIterator> void assign(InputIterator first, InputIterator last);
v.assign(v1.begin(), v1.end());
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
string str("hello world");
v.assign(str.begin(), str.end());//assign里面的迭代器類型是不確定的,既有可能是他自己的iterator也有可能是其他容器的迭代器類型。
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.assign(++str.begin(), --str.end());//你可以控制迭代器的區間,指定assign的容器元素內容的長度。
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}1.對于順序表這種結構來說,頭插和頭刪的效率是非常低的,所以vector只提供了push_back和pop_back,而難免遇到頭插和頭刪的情況時,可以偶爾使用insert和erase來進行頭插和頭刪,并且insert和erase的參數都使用了迭代器類型作為參數,因為迭代器更具有普適性。
2.如果要在vector的某個位置進行插入時,肯定是需要使用find接口的,但其實vector的默認成員函數并沒有find接口,這是為什么呢?因為大多數的容器都會用到查找接口,也就是find,所以C++直接將這個接口放到算法庫里面去了,實現一個函數模板,這個函數的實現實際也比較簡單,只要遍歷一遍迭代器然后返回對應位置的迭代器即可,所以這個函數不單獨作為某個類的成員函數,而是直接放到了算法庫里面去。

void test_vector6()//測試insert和find
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.insert(v.begin(), 4);
v.insert(v.begin() + 2, 4);
//vector的迭代器能夠直接+2,源自于vector的底層是連續的空間,迭代器也就是連續的,而list的底層不是連續空間,而是一個個的節點,
//所以迭代器就不能++來進行使用了
//如果要在vector里面的數字3位置插入一個元素的話:std::find,find的實現就是遍歷一遍迭代器,找到了就返回對應位置的迭代器。
//而vector、list、deque等容器都會用到find,所以find直接實現一個模板即可。
vector<int>::iterator it = std::find(v.begin(), v.end(), 3);
//string沒有實現find的原因是string不僅僅要找某一個字符,而且還要找一個字串,所以算法庫的find就不怎么適用,string就自己造輪子
v.insert(it, 30);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}vector類內的swap用于兩個對象的交換,在swap實現里面再調用std的swap進行內置類型的交換,但C++用心良苦,如果你不小心使用的格式是std里面的swap格式的話,也沒有關系,因為類外面有一個匹配vector的swap,所以會優先調用類外的swap,C++極力不想讓你調用算法庫的swap,就是因為如果交換的類型是自定義類型的情況下,算法庫的swap會進行三次深拷貝,代價極大,所以為了極力防止你調用算法庫的swap,C++不僅在類內定義了swap,在類外也定義了已經實例化好的swap,調用時會優先調用最匹配的swap。
void test_vector8()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
vector<int> v1;
v1.swap(v);
swap(v1, v);//一不小心這樣用呢?那也不會去調用算法庫里面的三次深拷貝的swap
//這里會優先匹配vector的類外成員函數,既然有vector作為類型實例化出來的swap函數模板,就沒有必要調用算法庫里面的模板進行實例化
//template <class T, class Alloc>
//void swap(vector<T, Alloc>&x, vector<T, Alloc>&y);
}1.看源碼框架的方法:將類成員變量先抽出來,看一看成員函數的聲明具體都實現了什么功能,如果想要看實現,那就去.c文件抽出來具體函數去看
2.看某些書籍時的道理和看源碼是一樣的,要進行抽絲剝繭,不要想著第一遍就把看到的所有東西都弄回,如果你覺得這本書或源碼非常不錯,你可以多次反復的去看,要循序漸進的去學,一段時間之后,你的知識儲備上來之后,可能再去看書籍或者源碼又有新的不同的感受,所以不要想著一遍就把所有的東西都搞明白,第一遍弄懂個70%-80%就很不錯,如果你想學扎實一點,那就增加遍數。
關于“C++ vector的基本使用方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





