溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python之string編碼問題怎么解決”,在日常操作中,相信很多人在Python之string編碼問題怎么解決問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python之string編碼問題怎么解決”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
通常我們所說的編碼一般為簡稱, 其實在平常的應用過程,編碼一般包括 編碼和解碼,如在編碼前指定 字符集UTF-8, 那么解碼時也必須為UTF-8,否則會出現所謂的 亂碼
字符集類似于中文,英文,是一個規則集合的抽象概念,其規定了某個文字對應的二進制數字存放方式,即為編碼過程,或者二進制數字對應的文字,即為解碼過程!
字符集包括如下:
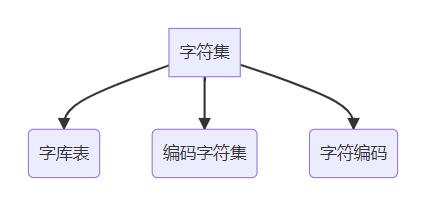
1.字庫表
字庫表是一個相當于所有可讀或者可顯示字符的數據庫,字庫表決定了整個字符集能夠展現表示的所有字符的范圍
2.編碼字符集(通常簡稱 字符集)
編碼字符集,用一個編碼值code point(二進制代碼)來表示一個字符(即該字符在字庫表中的位置)
3.字符編碼
字符編碼,是編碼字符集和實際存儲數值之間的轉換關系;
字符,是根據字符編碼方案轉換為一個二進制數值存儲在計算機中的
一個范例
下面以一個實例解釋下編解碼的過程
字符編碼: UTF-8
字符串:中國
Python版本:2.7
說明:
1.編碼轉換方式
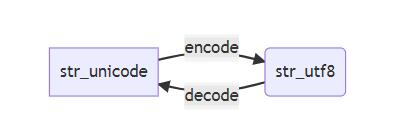
str_unicode為中間碼。
即對應編碼字符集 在字庫表中有唯一id代表一個字符, 理論上 unicode即可以映射表示所有字符,但是為了壓縮存儲的位數,發展出了 utf-8、utf-16等字符編碼,即在實際存儲和字符展現之間又建立了一層映射,這層映射表示了 utf-8 到 unicode的方式,然后unicode又根據字庫表展現改字符。
即 unicode有 utf-8及utf-16等多種方式的字符編碼方案,GBK字符集 則只有一種字符編碼 EUC-CN, 而對于Ascii碼來說,本身即是編碼字符集又是字符編碼,
2.以一次Python代碼執行為例, 解釋 字庫表、編碼字符集(字符集) 與 字符編碼的關系:

utf-8編碼如何規定的?
單字節的字符,字節的第一位設為0,對于英語文本,UTF-8碼只占用一個字節,和ASCII碼完全相同;
n個字節的字符(n>1),第一個字節的前n位設為1,第n+1位設為0,后面字節的前兩位都設為10,這n個字節的其余空位填充該字符unicode碼,高位用0補足。
UTF-8編碼方式
----------------------
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
utf-8和unicode的關系
utf 解釋為誒 Unicode TransferFormat 即 轉換Unicode。
unicode是一種字符編碼,規定了每個字符到數字的映射關系, 這個數字怎么存儲它沒有規定. 而如何存儲? 幾個字節表示? 這個是utf8等編碼方式來規定的。
有了unicode為什么還需要utf-8呢?
首先 unicode 規定了所有字符的二進制編碼,并沒有規定如何存儲
如果我們以統一4個字節來存儲所有unicode的編碼字符,那就會在表示一個字節編碼的ascii部分嚴重浪費存儲性能
另外因為統一4字節處理,那如果一個文件分片或者是一份缺失文件,那么此時該如何來判斷我們從頭讀取的 4字節是一個完整的字符呢?這就會造成很大的分析復雜度,可以說 無法分析, 這也是 utf-8等編碼的優點即utf-8錯誤編碼不會向后擴散
綜合考慮 utf-8 是一種unicode 標準的存儲方案,改方案規定了如何存儲unicode字符,即看上面的utf-8的規定,大白話講就是 utf-8 可變長編碼規定了 字符的起始位置,且極大可能節省存儲空間,總而言之很簡單就是在無序中找到秩序
下列四種影響Python執行的編碼方案,具體實例以最后所列案例為準
獲取解釋器默認編碼,Python3對應的默認編碼為 utf-8,Python2對應的默認編碼為ascii
import sys print(sys.getdefaultencoding())
Python2設置默認編碼方式,Python3解釋器默認utf-8所以去除該種設置方式
import sys
reload(sys)
sys.setdefaultencoding('utf-8')解釋器編碼有什么用?
當調用 decode() 和 encode() 進行編碼轉換時候,如果未指定編碼格式,會調用解釋器默認編碼進行編碼轉換
若未指定編碼方式 而有中文出現,此時會有報錯產生
python源文件的編碼與解碼,我們寫的python程序從產生到執行的過程如下(以Pycharm為例)
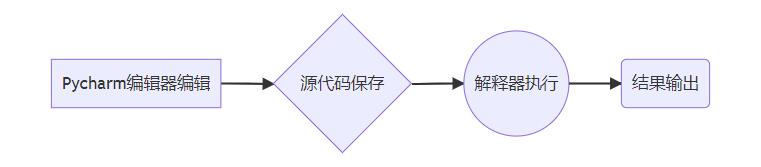
依次為
編輯器 決定源代碼的編碼格式(編輯器中設置)
pycharm 會根據文件開頭的編碼聲明進行文件格式保存
此種聲明保存的文件,是utf-8編碼的
# coding: utf-8
此種聲明保存的文件,是gbk編碼的
# coding: gbk
同時也可以在setting中進行設置
解釋器按照Ascii或者聲明指定的方式解碼源代碼, 以下是 官方文檔給的解釋
Python will default to ASCII as standard encoding if no other encoding hints are given.
※: Python2中會按照編碼聲明對源代碼進行解碼,如未指定 編碼聲明 則會以 Ascii進行解碼,此時如果有中文會報錯
※:Python3默認以utf-8進行解碼
若未指定編碼聲明, 而源代碼中有中文
此時Python2 會以Ascii 來進行源代碼的'解碼';Python3 會默認以 utf-8 進行源代碼的'解碼'。
若源文件編碼為utf-8, 而編碼聲明 為gbk
這種情況會出錯,因為磁盤中保存的格式時 gbk 格式的而卻以 utf-8 來進行解碼,則會出錯。
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 2-3: illegal multibyte sequence

注意1:Python3將源代碼讀取到內存中的字符串編碼為 unicode, 這樣的中間碼的方式,不會出現亂碼, Python2以文件頭聲明的方式將源代碼讀取到內存中
注意2:Python2 在日常編程中一定注意 文件編碼 和 文件聲明要一致,如 文件編碼為 utf-8 則此時應該如此聲明 # coding: utf-8, 若此時用gbk 做聲明,則此時會亂碼,一編一解 要成對
結果輸出,控制臺輸出 或 日志文件
解釋器如何知道該文件的編碼格式?
# coding: utf-8
locale 模塊獲取 操作系統編碼
import locale print locale.getdefaultencoding()
以open()函數為例
open() 函數會調用 Python操作系統默認編碼進行 編解碼
# coding: utf-8
import sys; reload(sys); sys.setdefaultencoding('utf-8')
str = '中國' # utf-8 bytes類型
str_unicode = str.decode() # unicode
with open('demo.txt', 'w') as f:
f.write(str) # 寫入bytes類型,則此時文件編碼為 utf-8
f.write(str_unicode) # 寫入 unicode,則此時會根據 sys.getdefaultencoding() 來進行文件編碼linux 下 vim打開以 gbk方式寫入的文件會出現亂碼,因為此時會調用操作系統的編碼方式進行解碼
終端編碼 繼承自操作系統的編碼
print("你好".encode('utf-8'))
>>> b'\xe4\xbd\xa0\xe5\xa5\xbd'很容易看出 其中的 16進制數 e4bda0e5a5bd
對于字節流(bytes: 如utf-8字節流)來說表示字節數
對于unicode則表示字符數
Pycharm編碼設置
字符串變量級別編碼
腳本級別的編碼
py文件級別的編碼
顯示窗口的編碼
問題收集 python3 unicode字符轉中文
a = "\\u4ea7\\u54c1\\u72b6\\u6001"
# 兩種方式
print(eval(f'u"{a}"'))
print(a.encode().decode("unicode_escape"))即 一個字符可以是一個中文漢字、一個英文字母、一個阿拉伯數字、一個標點符號等 ??
如:Unicode、ASCII
到此,關于“Python之string編碼問題怎么解決”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





