溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python時間序列如何實現”,在日常操作中,相信很多人在Python時間序列如何實現問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python時間序列如何實現”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
時間序列(Time Series)是一種重要的結構化數據形式。時間序列的數據意義取決于具體的應用場景,主要有以下幾種:
時間戳(timestamp):特定的時刻
固定時期(period):2007年1月或2010年全年
時間間隔(interval):由起始和結束時間戳表示。時期(period)可以被看作間隔的特例。
datetime.datetime對象(以下簡稱datetime對象)以毫秒形式存儲日期和時間。datetime.timedelta表示datetime對象之間的時間差。
import pandas as pd import numpy as np from datetime import datetime,timedelta %matplotlib inline now = datetime.now() #now為datetime.datetime對象
now
輸出:
datetime.datetime(2019, 10, 11, 15, 33, 5, 701305)
now.year,now.month,now.day
輸出:
(2019, 10, 11)
delta = datetime.now()-datetime(2019,1,1) #delta為datetime.timedelta對象
datetime.now() + timedelta(12)
輸出:
datetime.datetime(2023, 3, 10, 22, 13, 25, 3470)
(1) 利用str或datetime.strftime方法(傳入一個格式化字符串),datetime對象和pandas的Timestamp對象可以被格式化為字符串;datetime.strptime可以將字符串轉換為日期。
stamp = datetime(2011,1,3)
stamp.strftime('%Y-%m-%d') #或str(stamp)輸出:
‘2011-01-03’
datetime.strptime('2019-10-01','%Y-%m-%d')輸出:
datetime.datetime(2019, 10, 1, 0, 0)
(2) 對于一些常見的日期格式,可以使用datautil中的parser.parse方法(不支持中文)
from dateutil.parser import parse
parse('2019-10-01') #形成datetime.datetime對象輸出:
datetime.datetime(2019, 10, 1, 0, 0)
(3) pandas的to_datetime方法可以解析多種不同的日期表示形式
import pandas as pd datestrs = ['7/6/2019','8/6/2019'] dates = pd.to_datetime(datestrs) #將字符串列表轉換為Timestamp對象
type(dates)
輸出:
pandas.core.indexes.datetimes.DatetimeIndex
dates[0]
輸出:
Timestamp(‘2019-07-06 00:00:00’)
pandas最基本的時間序列類型就是以時間戳(通常以Python字符串或datetime對象表示)為索引的Series。
時期(period)表示的是時間時區,比如數日、數月、數季、數年等。
from datetime import datetime dates = [datetime(2019,1,1),datetime(2019,1,2),datetime(2019,1,5),datetime(2019,1,10),datetime(2019,2,10),datetime(2019,10,1)] ts = pd.Series(np.random.randn(6),index = dates) #ts就成為一個時間序列,datetime對象實際上是被存放在一個DatetimeIndex中
ts
輸出:
2019-01-01 1.175755
2019-01-02 -0.520842
2019-01-05 -0.678080
2019-01-10 0.195213
2019-02-10 2.201572
2019-10-01 0.115911
dtype: float64
dates = pd.DatetimeIndex(['2019/01/01','2019/01/02','2019/01/02','2019/5/01','3/15/2019']) #同一時間點上多個觀測數據 dup_ts = pd.Series(np.arange(5),index = dates)
dup_ts
輸出:
2019-01-01 0
2019-01-02 1
2019-01-02 2
2019-05-01 3
2019-03-15 4
dtype: int32
dup_ts.groupby(level = 0).count()
輸出:
2019-01-01 1
2019-01-02 2
2019-03-15 1
2019-05-01 1
dtype: int64
pd.date_range可用于生成指定長度的DatetimeIndex
pd.date_range('2019/01/01','2019/2/1') #默認情況下產生按天計算的時間點。輸出:
DatetimeIndex([‘2019-01-01’, ‘2019-01-02’, ‘2019-01-03’, ‘2019-01-04’,
‘2019-01-05’, ‘2019-01-06’, ‘2019-01-07’, ‘2019-01-08’,
‘2019-01-09’, ‘2019-01-10’, ‘2019-01-11’, ‘2019-01-12’,
‘2019-01-13’, ‘2019-01-14’, ‘2019-01-15’, ‘2019-01-16’,
‘2019-01-17’, ‘2019-01-18’, ‘2019-01-19’, ‘2019-01-20’,
‘2019-01-21’, ‘2019-01-22’, ‘2019-01-23’, ‘2019-01-24’,
‘2019-01-25’, ‘2019-01-26’, ‘2019-01-27’, ‘2019-01-28’,
‘2019-01-29’, ‘2019-01-30’, ‘2019-01-31’, ‘2019-02-01’],
dtype=‘datetime64[ns]’, freq=‘D’)
pd.date_range('2010/01/01',periods = 30) # 傳入起始或結束日期及一個表示時間段的數字。輸出:
DatetimeIndex([‘2010-01-01’, ‘2010-01-02’, ‘2010-01-03’, ‘2010-01-04’,
‘2010-01-05’, ‘2010-01-06’, ‘2010-01-07’, ‘2010-01-08’,
‘2010-01-09’, ‘2010-01-10’, ‘2010-01-11’, ‘2010-01-12’,
‘2010-01-13’, ‘2010-01-14’, ‘2010-01-15’, ‘2010-01-16’,
‘2010-01-17’, ‘2010-01-18’, ‘2010-01-19’, ‘2010-01-20’,
‘2010-01-21’, ‘2010-01-22’, ‘2010-01-23’, ‘2010-01-24’,
‘2010-01-25’, ‘2010-01-26’, ‘2010-01-27’, ‘2010-01-28’,
‘2010-01-29’, ‘2010-01-30’],
dtype=‘datetime64[ns]’, freq=‘D’)
pd.date_range('2010/01/01','2010/12/1',freq = 'BM')
#傳入BM(business end of month),生成每個月最后一個工作日組成的日期索引輸出:
DatetimeIndex([‘2010-01-29’, ‘2010-02-26’, ‘2010-03-31’, ‘2010-04-30’,
‘2010-05-31’, ‘2010-06-30’, ‘2010-07-30’, ‘2010-08-31’,
‘2010-09-30’, ‘2010-10-29’, ‘2010-11-30’],
dtype=‘datetime64[ns]’, freq=‘BM’)
pd.Series(np.arange(13),index = pd.date_range('2010/01/01','2010/1/3',freq = '4h'))輸出:
2010-01-01 00:00:00 0
2010-01-01 04:00:00 1
2010-01-01 08:00:00 2
2010-01-01 12:00:00 3
2010-01-01 16:00:00 4
2010-01-01 20:00:00 5
2010-01-02 00:00:00 6
2010-01-02 04:00:00 7
2010-01-02 08:00:00 8
2010-01-02 12:00:00 9
2010-01-02 16:00:00 10
2010-01-02 20:00:00 11
2010-01-03 00:00:00 12
Freq: 4H, dtype: int32
period_range可用于創建規則的時期范圍
pd.Series(np.arange(10),index = pd.period_range('2019/1/1','2019/10/01',freq='M'))輸出:
2019-01 0
2019-02 1
2019-03 2
2019-04 3
2019-05 4
2019-06 5
2019-07 6
2019-08 7
2019-09 8
2019-10 9
Freq: M, dtype: int32
重采樣(resampling)指的是將時間序列從一個頻率轉換到另一個頻率的處理過程。
降采樣(downsampling):將高頻率數據聚合到低頻率數據
升采樣(upsampling):將低頻率數據轉換到高頻率
rng = pd.date_range('2019/01/01',periods = 100,freq='D')
ts = pd.Series(np.random.randn(len(rng)),index=rng)ts.resample('M').mean()輸出:
2019-01-31 0.011565
2019-02-28 -0.185584
2019-03-31 -0.323621
2019-04-30 0.043687
Freq: M, dtype: float64
ts.resample('M',kind='period').mean()輸出:
2019-01 0.011565
2019-02 -0.185584
2019-03 -0.323621
2019-04 0.043687
Freq: M, dtype: float64
rng = pd.date_range('2019/01/01',periods = 12,freq='T')
ts = pd.Series(np.random.randn(len(rng)),index=rng)
ts.resample('5min').sum()輸出:
2019-01-01 00:00:00 1.625143
2019-01-01 00:05:00 2.588045
2019-01-01 00:10:00 2.447725
Freq: 5T, dtype: float64
金融領域中有種時間序列聚合方式,稱為OHLC重采樣,即計算各面元的四個值:
Open:開盤
High:最高值
Low:最小值
Close:收盤
輸出:
| open | high | low | close | |
|---|---|---|---|---|
| 2019-01-01 00:00:00 | -0.345952 | 1.120258 | -0.345952 | 1.120258 |
| 2019-01-01 00:05:00 | -0.106197 | 2.448439 | -1.014186 | -1.014186 |
| 2019-01-01 00:10:00 | 1.445036 | 1.445036 | 1.002688 | 1.002688 |
另一種降采樣的辦法是實用pandas的groupby方法。
rng = pd.date_range('2019/1/1',periods = 100,freq='D')
ts = pd.Series(np.arange(len(rng)), index = rng)ts.resample('m').mean()輸出:
2019-01-31 15.0
2019-02-28 44.5
2019-03-31 74.0
2019-04-30 94.5
Freq: M, dtype: float64
ts.groupby(lambda x:x.month).mean()
輸出:
1 15.0
2 44.5
3 74.0
4 94.5
dtype: float64
需要加載stock.csv文件,該文件格式如下:
| AA | AAPL | GE | IBM | JNJ | MSFT | PEP | SPX | XOM | |
|---|---|---|---|---|---|---|---|---|---|
| 1990/2/1 0:00 | 4.98 | 7.86 | 2.87 | 16.79 | 4.27 | 0.51 | 6.04 | 328.79 | 6.12 |
| 1990/2/2 0:00 | 5.04 | 8 | 2.87 | 16.89 | 4.37 | 0.51 | 6.09 | 330.92 | 6.24 |
| 1990/2/5 0:00 | 5.07 | 8.18 | 2.87 | 17.32 | 4.34 | 0.51 | 6.05 | 331.85 | 6.25 |
| 1990/2/6 0:00 | 5.01 | 8.12 | 2.88 | 17.56 | 4.32 | 0.51 | 6.15 | 329.66 | 6.23 |
| 1990/2/7 0:00 | 5.04 | 7.77 | 2.91 | 17.93 | 4.38 | 0.51 | 6.17 | 333.75 | 6.33 |
close_px_all = pd.read_csv('datasets/stock.csv',parse_dates = True, index_col=0)
close_px = close_px_all[['AAPL','MSFT','XOM']]
close_px.plot() #'AAPL','MSFT','XOM'股價變化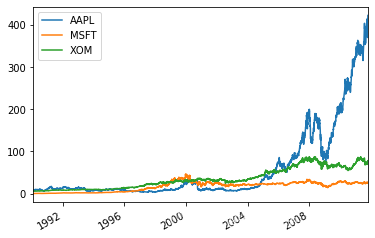
close_px.resample('B').ffill().plot() #填充工作日后,股價變化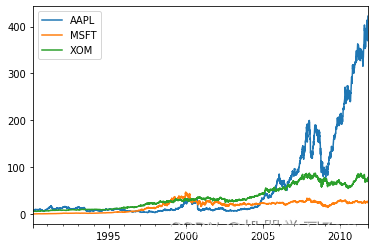
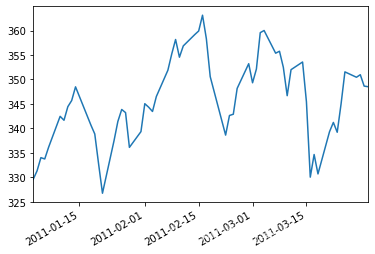
close_px.AAPL.loc['2011-01':'2011-03'].plot() #蘋果公司2011年1月到3月每日股價
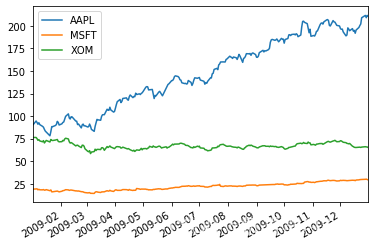
close_px.AAPL.loc['2011-01':'2011-03'].plot() #蘋果公司2011年1月到3月每日股價
移動窗口函數(moving window function)指在移動窗口(可帶指數衰減權數)上計算的各種統計函數,也包括窗口不定長的函數(如指數加權移動平均)。 與其他統計函數一樣,移動窗口函數會自動排除缺失值。
close_px.AAPL.plot() close_px.AAPL.rolling(250).mean().plot() #250日均線
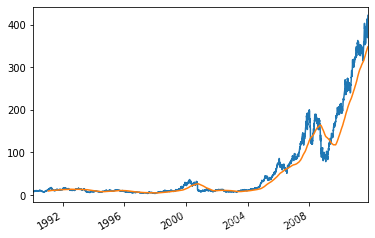
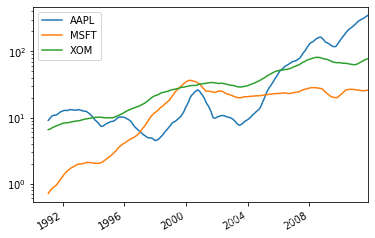
close_px.rolling(250).mean().plot(logy=True) #250日均線 對數坐標
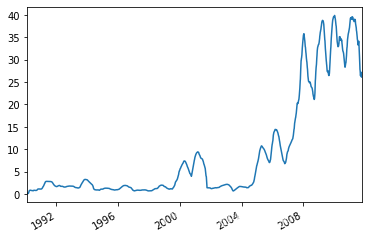
close_px.AAPL.rolling(250,min_periods=10).std().plot() #標準差
指數加權函數:定義一個衰減因子(decay factor),以賦予近期的觀測值擁有更大的權重。衰減因子常用時間間隔(span),可以使結果兼容于窗口大小等于時間間隔的簡單移動窗口(simple moving window)函數。
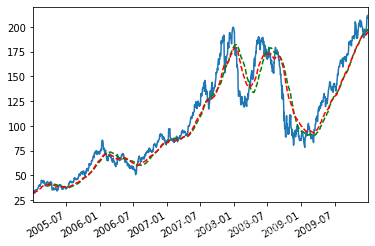
appl_px = close_px.AAPL['2005':'2009'] ma60 = appl_px.rolling(60,min_periods=50).mean() #60日移動平均 ewma60 = appl_px.ewm(span = 60).mean() #60日指數加權移動平均
appl_px.plot() ma60.plot(c='g',style='k--') ewma60.plot(c='r',style='k--') #相對于普通移動平均,能“適應”更快的變化
相關系數和協方差等統計運算需要在兩個時間序列上執行,如某只股票對某個參考指數(如標普500)的相關系數。
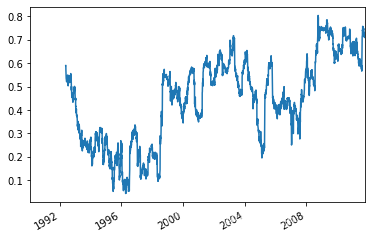
aapl_rets = close_px_all.AAPL['1992':].pct_change() spx_rets = close_px_all.SPX.pct_change() corr = aapl_rets.rolling(125,min_periods=100).corr(spx_rets) #APPL6個月回報與標準普爾500指數的相關系數 corr.plot()
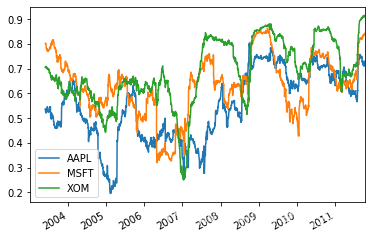
all_rets = close_px_all[['AAPL','MSFT','XOM']]['2003':].pct_change() corr = all_rets.rolling(125,min_periods=100).corr(spx_rets) #3支股票月回報與標準普爾500指數的相關系數 corr.plot()
到此,關于“Python時間序列如何實現”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





