溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“go開源Hugo站點怎么構建集結渲染”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“go開源Hugo站點怎么構建集結渲染”吧!

Assemble所做的事情很純粹,那就是創建站點頁面實例 - pageState。 因為支持多站點,contentMaps有多個。 所以Assemble不僅要創建pageState,還需要管理好所有的pages,這就用到了PageMaps。
type pageMap struct {
s *Site
*contentMap
}
type pageMaps struct {
workers *para.Workers
pmaps []*pageMap
}實際上pageMap就是由contentMap組合而來的。 而contentMap中的組成樹的結點就是contentNode。
正好,每個contentNode又對應一個pageState。
type contentNode struct {
p *pageState
// Set if source is a file.
// We will soon get other sources.
fi hugofs.FileMetaInfo
// The source path. Unix slashes. No leading slash.
path string
...
}所以Assemble不僅要為前面Process處理過生成的contentNode創建pageState,還要補齊一些缺失的contentNode,如Section。
可以看出,Assemble的重點就是組建PageState,那她到底長啥樣:
type pageState struct {
// This slice will be of same length as the number of global slice of output
// formats (for all sites).
pageOutputs []*pageOutput
// This will be shifted out when we start to render a new output format.
*pageOutput
// Common for all output formats.
*pageCommon
...
}從注解中可以看出普通信息將由pageCommon提供,而輸出信息則由pageOutput提供。 比較特殊的是pageOutputs,是pageOutput的數組。 在 基礎架構中,對這一點有作分析。 這要歸因于Hugo的多站點渲染策略 - 允許在不同的站點中重用其它站點的頁面。
// hugo-playground/hugolib/page__new.go // line 97 // Prepare output formats for all sites. // We do this even if this page does not get rendered on // its own. It may be referenced via .Site.GetPage and // it will then need an output format. ps.pageOutputs = make([]*pageOutput, len(ps.s.h.renderFormats))
那在Assemble中Hugo是如何組織pageState實例的呢?
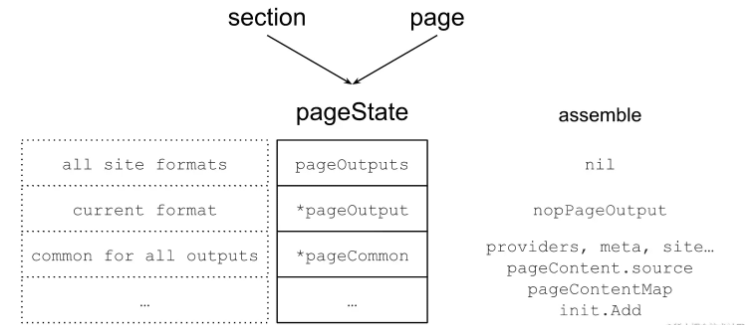
從上圖中,可以看出Assemble階段主要是新建pageState。 其中pageOutput在這一階段只是一個占位符,空的nopPageOutput。 pageCommon則是在這一階段給賦予了很多的信息,像meta相關的信息,及各種細節信息的providers。
package main
import (
"fmt"
"html/template"
)
func main() {
outputFormats := createOutputFormats()
renderFormats := initRenderFormats(outputFormats)
s := &site{
outputFormats: outputFormats,
renderFormats: renderFormats,
}
ps := &pageState{
pageOutputs: nil,
pageOutput: nil,
pageCommon: &pageCommon{m: &pageMeta{kind: KindPage}},
}
ps.init(s)
// prepare
ps.pageOutput = ps.pageOutputs[0]
// render
fmt.Println(ps.targetPaths().TargetFilename)
fmt.Println(ps.Content())
fmt.Println(ps.m.kind)
}
type site struct {
outputFormats map[string]Formats
renderFormats Formats
}
type pageState struct {
// This slice will be of same length as the number of global slice of output
// formats (for all sites).
pageOutputs []*pageOutput
// This will be shifted out when we start to render a new output format.
*pageOutput
// Common for all output formats.
*pageCommon
}
func (p *pageState) init(s *site) {
pp := newPagePaths(s)
p.pageOutputs = make([]*pageOutput, len(s.renderFormats))
for i, f := range s.renderFormats {
ft, found := pp.targetPaths[f.Name]
if !found {
panic("target path not found")
}
providers := struct{ targetPather }{ft}
po := &pageOutput{
f: f,
pagePerOutputProviders: providers,
ContentProvider: nil,
}
contentProvider := newPageContentOutput(po)
po.ContentProvider = contentProvider
p.pageOutputs[i] = po
}
}
func newPageContentOutput(po *pageOutput) *pageContentOutput {
cp := &pageContentOutput{
f: po.f,
}
initContent := func() {
cp.content = template.HTML("<p>hello content</p>")
}
cp.initMain = func() {
initContent()
}
return cp
}
func newPagePaths(s *site) pagePaths {
outputFormats := s.renderFormats
targets := make(map[string]targetPathsHolder)
for _, f := range outputFormats {
target := "/" + "blog" + "/" + f.BaseName +
"." + f.MediaType.SubType
paths := TargetPaths{
TargetFilename: target,
}
targets[f.Name] = targetPathsHolder{
paths: paths,
}
}
return pagePaths{
targetPaths: targets,
}
}
type pagePaths struct {
targetPaths map[string]targetPathsHolder
}
type targetPathsHolder struct {
paths TargetPaths
}
func (t targetPathsHolder) targetPaths() TargetPaths {
return t.paths
}
type pageOutput struct {
f Format
// These interface provides the functionality that is specific for this
// output format.
pagePerOutputProviders
ContentProvider
// May be nil.
cp *pageContentOutput
}
// pageContentOutput represents the Page content for a given output format.
type pageContentOutput struct {
f Format
initMain func()
content template.HTML
}
func (p *pageContentOutput) Content() any {
p.initMain()
return p.content
}
// these will be shifted out when rendering a given output format.
type pagePerOutputProviders interface {
targetPather
}
type targetPather interface {
targetPaths() TargetPaths
}
type TargetPaths struct {
// Where to store the file on disk relative to the publish dir. OS slashes.
TargetFilename string
}
type ContentProvider interface {
Content() any
}
type pageCommon struct {
m *pageMeta
}
type pageMeta struct {
// kind is the discriminator that identifies the different page types
// in the different page collections. This can, as an example, be used
// to to filter regular pages, find sections etc.
// Kind will, for the pages available to the templates, be one of:
// page, home, section, taxonomy and term.
// It is of string type to make it easy to reason about in
// the templates.
kind string
}
func initRenderFormats(
outputFormats map[string]Formats) Formats {
return outputFormats[KindPage]
}
func createOutputFormats() map[string]Formats {
m := map[string]Formats{
KindPage: {HTMLFormat},
}
return m
}
const (
KindPage = "page"
)
var HTMLType = newMediaType("text", "html")
// HTMLFormat An ordered list of built-in output formats.
var HTMLFormat = Format{
Name: "HTML",
MediaType: HTMLType,
BaseName: "index",
}
func newMediaType(main, sub string) Type {
t := Type{
MainType: main,
SubType: sub,
Delimiter: "."}
return t
}
type Type struct {
MainType string `json:"mainType"` // i.e. text
SubType string `json:"subType"` // i.e. html
Delimiter string `json:"delimiter"` // e.g. "."
}
type Format struct {
// The Name is used as an identifier. Internal output formats (i.e. HTML and RSS)
// can be overridden by providing a new definition for those types.
Name string `json:"name"`
MediaType Type `json:"-"`
// The base output file name used when not using "ugly URLs", defaults to "index".
BaseName string `json:"baseName"`
}
type Formats []Format輸出結果:
/blog/index.html <p>hello content</p> page Program exited.
PageState線上可直接運行版本
基礎信息是由pageCommon提供了,那渲染過程中的輸出由誰提供呢?
沒錯,輪到pageOutput了:
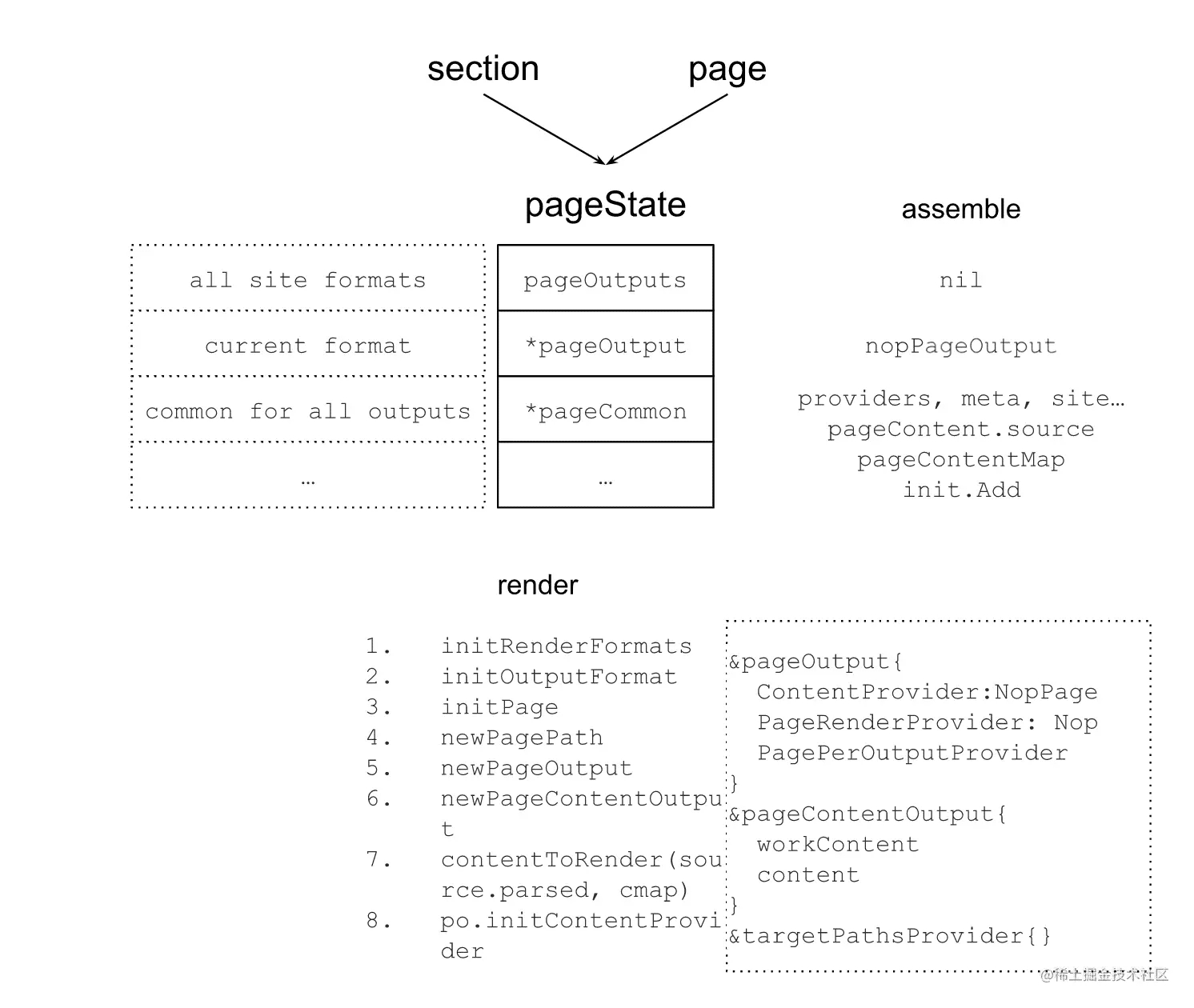
可以看到,在render階段,pageState的pageOutput得到了最終的處理,為發布做準備了。 為了發布,最重的信息是發布什么,以及發布到哪里去。 這些信息都在pageOutput中,其中ContentProvider是提供發布內容的,而targetPathsProvider則是提供發布地址信息的。 其中地址信息主要來源于PagePath,這又和站點的RenderFormats和OutputFormats相關,哪下圖所示:
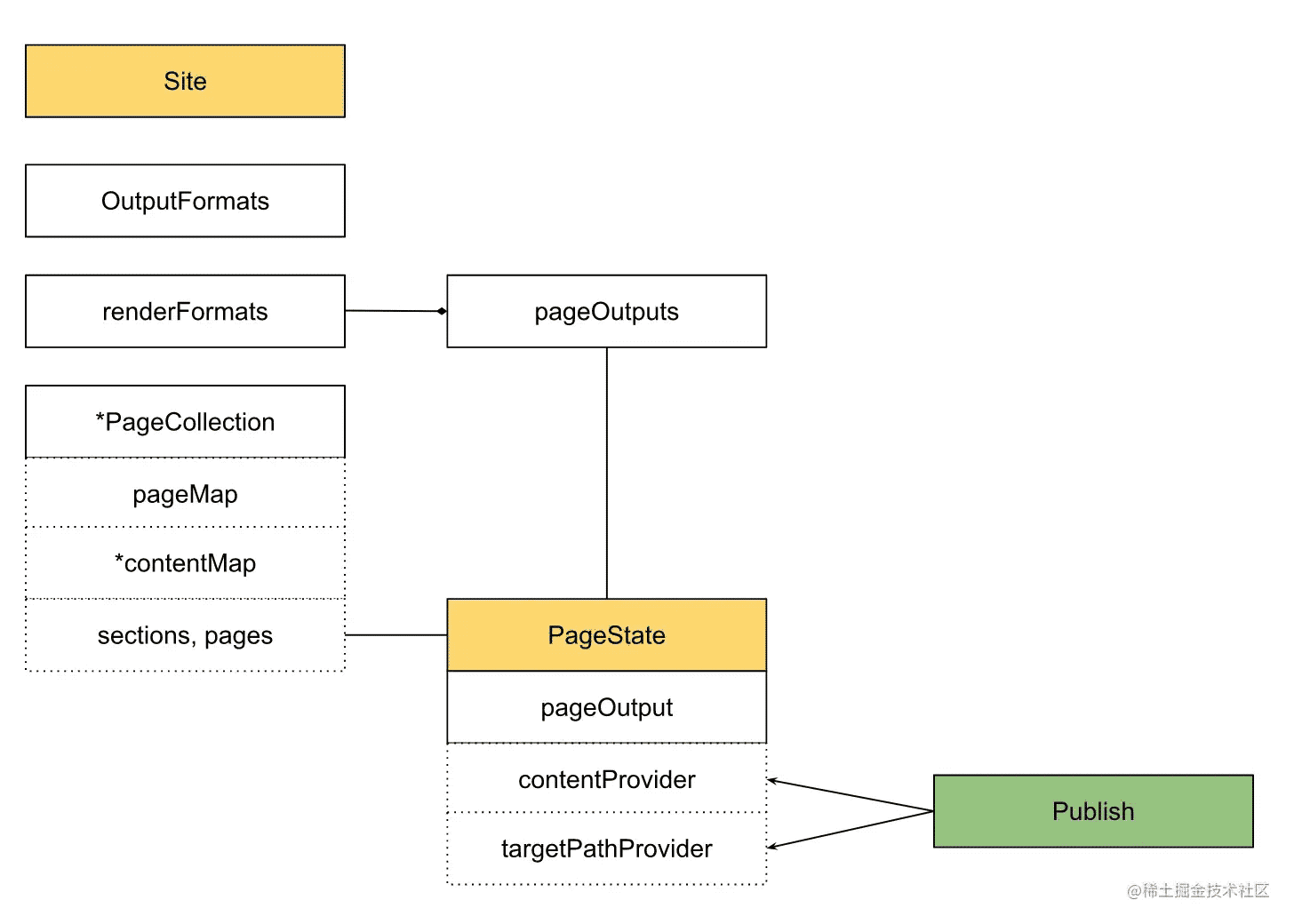
其中OutputFormats, RenderFormats及PageOutput之間的關系有在 基礎架構中有詳細提到,這里就不再贅述。
// We create a pageOutput for every output format combination, even if this
// particular page isn't configured to be rendered to that format.
type pageOutput struct {
...
// These interface provides the functionality that is specific for this
// output format.
pagePerOutputProviders
page.ContentProvider
page.TableOfContentsProvider
page.PageRenderProvider
// May be nil.
cp *pageContentOutput
}其中pageContentOutput正是實現了ContentProvider接口的實例。 其中有包含markdown文件原始信息的workContent字段,以及包含處理過后的內容content字段。 如Hugo Shortcode特性。 就是在這里經過contentToRender方法將原始信息進行處理,而最終實現的。
package main
import (
"bytes"
"fmt"
"io"
"os"
"path/filepath"
)
// publisher needs to know:
// 1: what to publish
// 2: where to publish
func main() {
// 1
// src is template executed result
// it is the source that we need to publish
// take a look at template executor example
// https://c.sunwei.xyz/template-executor.html
src := &bytes.Buffer{}
src.Write([]byte("template executed result"))
b := &bytes.Buffer{}
transformers := createTransformerChain()
if err := transformers.Apply(b, src); err != nil {
fmt.Println(err)
return
}
dir, _ := os.MkdirTemp("", "hugo")
defer os.RemoveAll(dir)
// 2
// targetPath is from pageState
// this is where we need to publish
// take a look at page state example
// https://c.sunwei.xyz/page-state.html
targetPath := filepath.Join(dir, "index.html")
if err := os.WriteFile(
targetPath,
bytes.TrimSuffix(b.Bytes(), []byte("\n")),
os.ModePerm); err != nil {
panic(err)
}
fmt.Println("1. what to publish: ", string(b.Bytes()))
fmt.Println("2. where to publish: ", dir)
}
func (c *Chain) Apply(to io.Writer, from io.Reader) error {
fb := &bytes.Buffer{}
if _, err := fb.ReadFrom(from); err != nil {
return err
}
tb := &bytes.Buffer{}
ftb := &fromToBuffer{from: fb, to: tb}
for i, tr := range *c {
if i > 0 {
panic("switch from/to and reset to")
}
if err := tr(ftb); err != nil {
continue
}
}
_, err := ftb.to.WriteTo(to)
return err
}
func createTransformerChain() Chain {
transformers := NewEmpty()
transformers = append(transformers, func(ft FromTo) error {
content := ft.From().Bytes()
w := ft.To()
tc := bytes.Replace(
content,
[]byte("result"), []byte("transferred result"), 1)
_, _ = w.Write(tc)
return nil
})
return transformers
}
// Chain is an ordered processing chain. The next transform operation will
// receive the output from the previous.
type Chain []Transformer
// Transformer is the func that needs to be implemented by a transformation step.
type Transformer func(ft FromTo) error
// FromTo is sent to each transformation step in the chain.
type FromTo interface {
From() BytesReader
To() io.Writer
}
// BytesReader wraps the Bytes method, usually implemented by bytes.Buffer, and an
// io.Reader.
type BytesReader interface {
// Bytes The slice given by Bytes is valid for use only until the next buffer modification.
// That is, if you want to use this value outside of the current transformer step,
// you need to take a copy.
Bytes() []byte
io.Reader
}
// NewEmpty creates a new slice of transformers with a capacity of 20.
func NewEmpty() Chain {
return make(Chain, 0, 2)
}
// Implements contentTransformer
// Content is read from the from-buffer and rewritten to to the to-buffer.
type fromToBuffer struct {
from *bytes.Buffer
to *bytes.Buffer
}
func (ft fromToBuffer) From() BytesReader {
return ft.from
}
func (ft fromToBuffer) To() io.Writer {
return ft.to
}輸出結果:
1. what to publish: template executed transferred result
2. where to publish: /tmp/hugo2834984546
Program exited.
Publish線上可直接運行版本
到此,相信大家對“go開源Hugo站點怎么構建集結渲染”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





