溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“pytorch常用工具包有哪些”,內容詳細,步驟清晰,細節處理妥當,希望這篇“pytorch常用工具包有哪些”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
Pytorch是torch的python版本,是由Facebook開源的神經網絡框架,專門針對 GPU 加速的深度神經網絡(DNN)編程。Torch 是一個經典的對多維矩陣數據進行操作的張量
(tensor )庫,在機器學習和其他數學密集型應用有廣泛應用。
Pytorch的計算圖是動態的,可以根據計算需要實時改變計算圖。
由于Torch語言采用 Lua,導致在國內一直很小眾,并逐漸被支持 Python 的 Tensorflow 搶走用戶。作為經典機器學習庫 Torch 的端口,PyTorch 為 Python 語言使用者提供了舒適的寫代碼選擇。
1.簡潔:
PyTorch的設計追求最少的封裝,盡量避免重復造輪子。不像 TensorFlow 中充斥著session、graph、operation、name_scope、variable、tensor、layer等全新的概念,PyTorch 的設計遵循tensor→variable(autograd)→nn.Module 三個由低到高的抽象層次,分別代表高維數組(張量)、自動求導(變量)和神經網絡(層/模塊),而且這三個抽象之間聯系緊密,可以同時進行修改和操作。
2.速度:
PyTorch 的靈活性不以速度為代價,在許多評測中,PyTorch 的速度表現勝過 TensorFlow和Keras 等框架。
3.易用:
PyTorch 是所有的框架中面向對象設計的最優雅的一個。PyTorch的面向對象的接口設計來源于Torch,而Torch的接口設計以靈活易用而著稱,Keras作者最初就是受Torch的啟發才開發了Keras。
4.活躍的社區:
PyTorch 提供了完整的文檔,循序漸進的指南,作者親自維護的論壇,供用戶交流和求教問題。Facebook 人工智能研究院對 PyTorch 提供了強力支持。
torch :類似 NumPy 的張量庫,支持GPU;
torch.autograd :基于 type 的自動區別庫,支持 torch 之中的所有可區分張量運行;
torch.nn :為最大化靈活性而設計,與 autograd 深度整合的神經網絡庫;
torch.optim:與 torch.nn 一起使用的優化包,包含 SGD、RMSProp、LBFGS、Adam 等標準優化方式;
torch.multiprocessing: python 多進程并發,進程之間 torch Tensors 的內存共享;
torch.utils:數據載入器。具有訓練器和其他便利功能;
torch.legacy(.nn/.optim) :出于向后兼容性考慮,從 Torch 移植來的 legacy 代碼;
特別注意一個問題:
通道問題:不同視覺庫對于圖像讀取的方式不一樣,圖像通道也不一樣:
opencv 的 imread 默認順序時 H * W * C
pytorch的Tensor是 C * H * W
Tensorflow是兩者都支持
numpy風格的tensor操作
pytorch對tensor提供的API參照了numpy
變量自動求導
在計算過程形成的計算圖中,參與的變量可快速計算出自己對于目標函數的梯度
神經網絡求導及損失函數優化等高層封裝
網絡層封裝在torch.nn
損失函數封裝在torch.functional
優化函數封裝在torch.optim
tensor數據類型:3浮點(float16,float32,float64)5整數(int16,int32,int64,int8+uint8)
| Data type | dtype | CPU tensor | GPU tensor |
|---|---|---|---|
| 16-bit floating point | torch.float16 or torch.half | torch.HalfTensor | torch.cuda.HalfTensor |
| 32-bit floating point | torch.float32 or torch.float | torch.FloatTensor | torch.cuda.FloatTensor |
| 64-bit floating point | torch.float64 or torch.double | torch.DoubleTensor | torch.cuda.DoubleTensor |
| Data type | dtype | CPU tensor | GPU tensor |
|---|---|---|---|
| 8-bit integer(unsigned) | torch.uint8 | torch.ByteTensor | torch.cuda.ByteTensor |
| 8-bit integer(signed) | torch.int8 | torch.CharTensor | torch.cuda.CharTensor |
| 16-bit integer(signed) | torch.int16 or torch.short | torch.ShortTensor | torch.cuda.ShortTensor |
| 32-bit integer(signed) | torch.int32 or torch.int | torch.IntTensor | torch.cuda.IntTensor |
| 64-bit integer(signed) | torch.int64 or torch.long | torch.LongTensor | torch.cuda.LongTensor |
創建tensor的常見api
| 方法名 | 說明 |
|---|---|
| Tensor() | 直接從參數構造張量,支持list和numpy數組 |
| eye(row,column) | 創建指定行數&列數的單位tensor(單位陣) |
| linspace(start,end,count) | 在[s,e]上創建c個元素的一維tensor |
| logspace(start,end,count) | 在[10s,10e]上創建c個元素的一維tensor |
| ones(size) | 返回指定shape的tensor,元素初始值為1 |
| zeros(size) | 返回指定shape的tensor,元素初始值為0 |
| ones_like(t) | 返回一個tensor,shape與t相同,且元素初始值為1 |
| zeros_like(t) | 返回一個tensor,shape與t相同,且元素初始值為1 |
| arange(s,e,sep) | 在區間[s,e)上以間隔sep生成一個序列張量 |
tensor 對象的方法
| 方法名 | 作用 |
|---|---|
| size() | 返回張量的shape |
| numel() | 計算tensor的元素個數 |
| view(shape) | 修改tensor的shape,與np.reshape相似,view返回的是對象的共享內存 |
| resize | 類似于view,但在size超出時會重新分配內存空間 |
| item | 若為單元素tensor,則返回python的scalar |
| from_numpy | 從numpy數據填充 |
| numpy | 返回ndarray類型 |
tensor對象通過一系列運算組成動態圖,每個tensor對象都有以下幾個控制求導的屬性。
| 變量 | 作用 |
|---|---|
| requird_grad | 默認為False,表示變量是狗需要計算導數 |
| grad_fn | 變量的梯度函數 |
| grad | 變量對應的梯度 |
torch.nn提供了創建神經網絡的基礎構件,這些層都繼承自Module類。下面是自己手動實現一個線性層(linear layer)。適當參考,以后直接調用現成的接口,這里稍微了解一下,無實際意義。
import torch
class Linear(torch.nn.Module):
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
# torch.randn() 返回一個符合均值為0,方差為1的正態分布
self.weight = torch.nn.Parameter(torch.randn(out_features, in_features))
if bias:
self.bias = torch.nn.Parameter(torch.randn(out_features))
def forward(self, x):
# xW+b
x = x.mm(self.weight)
if self.bias:
x = x + self.bias.expand_as(x)
return x
if __name__ == '__main__':
net = Linear(3,2)
x = net.forward
print('11',x)下面表格中列出了比較重要的神經網絡層組件。
對應的在nn.functional模塊中,提供這些層對應的函數實現。
通常對于可訓練參數的層使用module,而對于不需要訓練參數的層如softmax這些,可以使用functional中的函數。
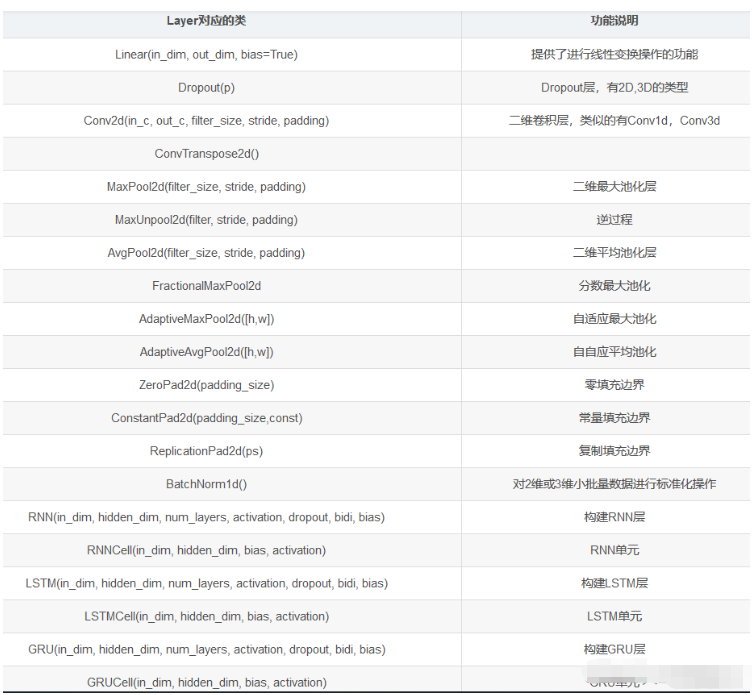
一些容器:
| 容器類型 | 功能 |
|---|---|
| Module | 神經網絡模塊基類 |
| Sequential | 序貫模型,類似keras,用于構建序列型神經網絡 |
| ModuleList | 用于存儲層,不接受輸入 |
| Parameters(t) | 模塊的屬性,用于保存其訓練參數 |
| ParameterList | 參數列表1 |
容器代碼:
# 方法1 像
model1 = nn.Sequential()
model.add_module('fc1', nn.Linear(3,4))
model.add_module('fc2', nn.Linear(4,2))
model.add_module('output', nn.Softmax(2))
# 方法2
model2 = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# 方法3
model3 = nn.ModuleList([nn.Linear(3,4), nn.ReLU(), nn.Linear(4,2)])torch.nn.Module提供了神經網絡的基類,當實現神經網絡時需要繼承自此模塊,并在初始化函數中創建網絡需要包含的層,并實現forward函數完成前向計算,網絡的反向計算會由自動求導機制處理。
通常將需要訓練的層寫在init函數中,將參數不需要訓練的層在forward方法里調用對應的函數來實現相應的層。
編碼三步走:
在pytorch中就只需要分三步:
寫好網絡;
編寫數據的標簽和路徑索引;
把數據送到網絡。
讀到這里,這篇“pytorch常用工具包有哪些”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





