溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下MyBatis動態SQL與緩存原理是什么的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
為什么叫做動態SQL:因為在程序執行中,mybatis提供的sql可以根據用戶提供的字段數量、類型,合理的選擇對應的執行sql。正是這一動態的選擇特性,極大的優化了使用JDBC的代碼冗余。
根據不同條件生成不同的sql語句執行
以博客表為例:
create table `blog`( `id` varchar(50) primary key comment '博客ID', `title` varchar(100) not null comment '博客標題', `author` varchar(50) not null comment '博客作者', `create_time` datetime not null comment '創建時間', `view` int not null comment '瀏覽量' );
Blog實體:
@Data
@AllArgsConstructor
public class Blog {
private String id;
private String title;
private String author;
private Date creatTime;
private int views;
}IDutils,用于隨機生成的ID名稱
public static String getId(){
return UUID.randomUUID().toString().replaceAll("-","");
}以上述搭建的環境為例,當我們需要查詢博客時,如果用戶指定了搜索搜索字段那就根據該字段查找,如果沒有指定那就查詢全部。如果用普通的sql語句實現,需要我們在Java程序中進行判斷,但是MyBatis提供了動態SQL,我們就可以利用內置的IF標簽來實現:
BlogMapper.xml配置
<select id="getBlogListIF" parameterType="map" resultType="Blog">
select * from blog where 1 = 1
<if test="title != null">
and title like "%"#{title}"%"
</if>
<if test="author != null">
and author like "%"#{author}"%"
</if>
</select>測試:
@Test
public void testGetBlogList(){
SqlSession sqlSession = MyBatisUtils.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("title","Java");
map.put("author",null);
List<Blog> blogListIF = mapper.getBlogListIF(map);
for (Blog blog : blogListIF) {
System.out.println(blog);
}
sqlSession.commit();
sqlSession.close();
}此處采用模糊查詢,在xml中直接對title和author字段進行判斷,如果非空則執行拼接sql,反之查詢全部
看下列代碼:
<select id="getBlogListIF" parameterType="map" resultType="Blog">
select * from blog where
<if test="title != null">
and title like "%"#{title}"%"
</if>
<if test="author != null">
and author = #{author}
</if>
</select>此時當上述兩個if滿足任一時,sql拼接后變成:
select * from blog where and author = #{author}這是不符合sql語法規則的。對此MyBatis提供了where標簽來處理這種情況。
<select id="getBlogListIF" parameterType="map" resultType="Blog">
select * from blog
<where>
<if test="title != null">
and title like "%"#{title}"%"
</if>
<if test="author != null">
and author = #{author}
</if>
</where>
</select>where元素只會在它的任一子元素返回內容時,才會在sql中插入where子句。如果返回的sql開頭為and 或on,where標簽會自動將其抹去
sql中更新語句update在mybatis常用set標簽來判定都需要更新哪些字段,如果用戶設置了新的該字段屬性,則會在set檢測到,從而執行更新語句
并且set子句會動態的在行首添加上set關鍵字,包括刪除額外的逗號
<update id="updateBlogInfo" parameterType="map">
update blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author},
</if>
</set>
where id = #{id}
</update>trim包含四個屬性:
prefix前綴、prefixOverrides前綴覆蓋、suffix后綴、suffixOverrides后綴覆蓋
當where和set不能得到預期的結果時,可以使用trim進行配置。也可以直接使用trim實現和where、set相同的效果:
<!-- trim實現set -->
<trim prefix="set" suffixOverrides=",">
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author},
</if>
</trim>
<!-- trim實現where -->
<trim prefix="where" prefixOverrides="and | or">
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
and view != 0
</otherwise>
</choose>
</trim>choose標簽,類似于Java中的switch語句。當我們不想要執行全部的sql,而只是選擇性的去執行對應的sql。
三者的關系類似于switch–>choose、case–>when、default–>otherwise
BlogMapper.xml編譯sql
<select id="queryBlogChoose" parameterType="map" resultType="blog">
select * from blog
<where>
<choose>
<!--title不為null執行-->
<when test="title != null">
title = #{title}
</when>
<!--author不為null執行-->
<when test="author != null">
and author = #{author}
</when>
<!--默認執行-->
<otherwise>
and view != 0
</otherwise>
</choose>
</where>
</select>利用sql標簽,抽離重復代碼。在需要使用的地方使用include標簽直接引入即可
<!-- 抽離sql -->
<sql id="checkTitleAuthor">
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author},
</if>
</sql>
<select id="getBlogListIF" parameterType="map" resultType="Blog">
select * from blog
<where>
<!-- 引入sql片段 -->
<include refid="checkTitleAuthor"/>
</where>
</select>利用Foreach可以在動態sql中對集合進行遍歷
BlogMapper.xml
<select id="getBlogForeach" parameterType="map" resultType="blog">
select * from blog
<where>
<foreach collection="ids" item="id" open="(" separator="or" close=")">
id=#{id}
</foreach>
</where>
</select>上述代碼,利用map集合存儲list集合交給foreach,此處collection通過鍵“ids”獲取list,item為值,open為拼接sql的開始,close為拼接sql的結束,separator表示分隔符
什么是緩存?
緩存是存在于內存中的臨時數據
使用緩存可以減少和數據庫的交互次數,提高數據庫性能和執行效率
官網給出:
映射語句文件中的所有 select 語句的結果將會被緩存。
映射語句文件中的所有 insert、update 和 delete 語句會刷新緩存。
緩存會使用最近最少使用算法(LRU, Least Recently Used)算法來清除不需要的緩存。
緩存不會定時進行刷新(也就是說,沒有刷新間隔)。
緩存會保存列表或對象(無論查詢方法返回哪種)的 1024 個引用。
緩存會被視為讀/寫緩存,這意味著獲取到的對象并不是共享的,可以安全地被調用者修改,而不干擾其他調用者或線程所做的潛在修改。
也叫做本地緩存,對應MyBatis中的sqlSession。
一級緩存是默認開啟的,作用域僅在sqlSession中有效
用戶user表id查詢兩次相同數據示例:
@Select("select * from user where id = #{id}")
Users getUserById(@Param("id") int id);
// 測試
public void testGetUsersList() {
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Users user1 = mapper.getUserById(2);
System.out.println(user1);
Users user2 = mapper.getUserById(2);
System.out.println(user2);
System.out.println(user1==user2);
sqlSession.close();
}打印效果分析:
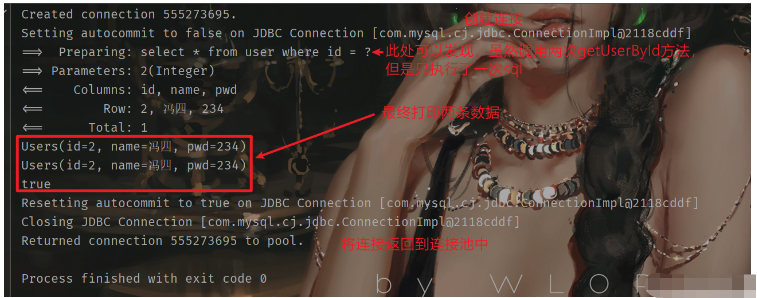
上述程序分別調用兩次getUserById方法,如果沒有緩存機制那么最終應該會執行兩次查詢sql來返回數據,但是根據日志可以看到最終只執行了一次sql。 這說明,第一次查詢到的數據就已經存放在了緩存當中,而第二次執行查詢時將會直接從緩存中獲取,不再進入sql層面查詢。
看下面的示例:
<update id="updateUserInfo" parameterType="map" >
update user
<set>
<if test="name != null">
name = #{name},
</if>
<if test="pwd != null">
pwd = #{pwd},
</if>
</set>
where id = #{id}
</update>@Test
public void testGetUsersList() {
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// 第一次查詢id=2數據
Users user1 = mapper.getUserById(2);
System.out.println(user1);
System.out.println("-----------------------------------------------");
// 修改id=2數據
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("name","馮七七");
map.put("id",2);
int i = mapper.updateUserInfo(map);
sqlSession.commit();
// 第二次查詢id=2數據
Users user2 = mapper.getUserById(2);
System.out.println(user2);
System.out.println(user1==user2);
sqlSession.close();
}首先第一次查詢數據,查詢完之后調用修改方法將name修改為“ 馮七七 ” 然后再次執行查詢語句
日志分析:
Created connection 594427726.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@236e3f4e]
-- 第一次執行查詢sql 數據保存在sqlSession中
==> Preparing: select * from user where id = ?
==> Parameters: 2(Integer)
<== Columns: id, name, pwd
<== Row: 2, 馮子, 234
<== Total: 1
Users(id=2, name=馮子, pwd=234)
-----------------------------------------------
-- 修改剛剛查詢的數據
==> Preparing: update user SET name = ? where id = ?
==> Parameters: 馮七七(String), 2(Integer)
<== Updates: 1
Committing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@236e3f4e]
-- 再次執行查詢語句 查詢剛剛修改過的數據
==> Preparing: select * from user where id = ?
==> Parameters: 2(Integer)
<== Columns: id, name, pwd
<== Row: 2, 馮七七, 234
<== Total: 1
Users(id=2, name=馮七七, pwd=234)
false-- 數據發生改變
得出結論,數據在執行select之后會將查詢到的數據保存在緩存中,以便下次直接使用
對于增刪改則會在完成之后刷新緩存,刷新之后如果需要獲取數據智能再次查詢數據庫
查詢不同數據時,自然無法從緩存中直接拿到。
增刪改操作可能會改變原數據,所以一定會刷新緩存
手動清理緩存:sqlSession.clearCache();
創建不同的sqlSession對象查詢
一級緩存是默認開啟的,但是由于一級緩存作用域太低,所以誕生二級緩存
二級緩存就是全局緩存,它對應于一個namespace命名空間級別。只要開啟了二級緩存,在用一個Mapper下就始終有效
工作機制:
一個會話查詢一條數據,查詢成功后該數據會存放在一級緩存中
如果當前會話關閉了,則其對應的一級緩存消失。
如果開啟了二級緩存,那么一級緩存消失后,其中的數據就會被保存到二級緩存中
當新開的會話去查詢同一數據時,就會從二級緩存中拿到
cacheEnabled 全局性地開啟或關閉所有映射器配置文件中已配置的任何緩存。
有效值true | false 默認值 true
但通常我們會在settings中顯式的開啟
<setting name=" cacheEnabled " value="true"/>
然后需要在想要使用二級緩存的Mapper.xml文件中配置cache
<!-- 開啟 使用默認參數 --> <cache/> <!-- 自定義參數 --> <cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
上述eviction是指驅逐策略,FIFO先進先出,按照對象進入緩存的順序移出
flushInterval為刷新緩存的間隔時間,size為最大緩存容量,readOnly是否設置為只讀
要注意的一點是,只有在一級緩存銷毀之后。sqlSession才會將它緩存的東西交給二級緩存
// 測試二級緩存
@Test
public void testGetUserById(){
// 創建兩個sqlSession會話
SqlSession sqlSession1 = MyBatisUtils.getSqlSession();
SqlSession sqlSession2 = MyBatisUtils.getSqlSession();
// selSession1查詢一次
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
Users user = mapper1.getUserById(2);
System.out.println(user);
sqlSession1.close();// 關閉sqlSession1
System.out.println("---------------------------------------------");
// selSession2查詢與sqlSession相同的數據
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
Users user1 = mapper2.getUserById(2);
System.out.println(user1);
System.out.println(user==user1);
sqlSession2.close();
}打印日志如下:
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@55536d9e]
-- sqlSession1執行sql查詢數據
==> Preparing: select * from user where id = ?
==> Parameters: 2(Integer)
<== Columns: id, name, pwd
<== Row: 2, 馮七七, 234
<== Total: 1
Users(id=2, name=馮七七, pwd=234)
-- 回收sqlSession1到鏈接池
Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@55536d9e]
Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@55536d9e]
Returned connection 1431530910 to pool.
---------------------------------------------
Cache Hit Ratio [com.yuqu.dao.UserMapper]: 0.5
-- sqlSession查詢數據結果
Users(id=2, name=馮七七, pwd=234)
true
很明顯,sqlSession1查詢到的數據首先保存在了自己的緩存中,也就是一級緩存。那么關閉sqlSession1之后,數據被交給到二級緩存。此時sqlSession再次查詢相同數據,則會直接在二級緩存中拿到
一個問題:
上文提到了妖使用二級緩存則必須在對應的Mapper.xml文件中配置cache標簽。一種是隱式參數第一種,采用這種方式,就必須讓實體類pojo實現serializable接口,否則會報出異常
java.io.NotSerializableException: com.yuqu.pojo.Users
如果采用自定義參數形式,就不需要實現Serializable接口。因為cache中有一個參數為eviction驅逐策略直接就規定了緩存中的數據讀/寫的規則。
但是通常無論是否采用自定義參數,都會將實體類實現序列化接口
以上就是“MyBatis動態SQL與緩存原理是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





