溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
上回書講完了部署,部署完成之后,就開始了無休止的調優,對于Ceph運維人員來說最頭痛的莫過于兩件事:一、Ceph調優;二、Ceph運維。調優是件非常頭疼的事情,下面來看看運維小哥是如何調優的,運維小哥根據網上資料進行了一個調優方法論(調優總結)。
通過對網上公開資料的分析進行總結,對Ceph的優化離不開以下幾點:
硬件層面· 硬件規劃· SSD選擇· BIOS設置操作系統層面· Linux Kernel· 內存· Cgroup網絡層面· 巨型幀· 中斷親和· 硬件加速Ceph層面· Ceph Configurations· PG Number調整ceph-osd進程在運行過程中會消耗CPU資源,所以一般會為每一個ceph-osd進程綁定一個CPU核上。當然如果你使用EC方式,可能需要更多的CPU資源。
ceph-mon進程并不十分消耗CPU資源,所以不必為ceph-mon進程預留過多的CPU資源。
ceph-msd也是非常消耗CPU資源的,所以需要提供更多的CPU資源。
· 內存
ceph-mon和ceph-mds需要2G內存,每個ceph-osd進程需要1G內存,當然2G更好。
· 網絡規劃
萬兆網絡現在基本上是跑Ceph必備的,網絡規劃上,也盡量考慮分離cilent和cluster網絡。
2、SSD選擇硬件的選擇也直接決定了Ceph集群的性能,從成本考慮,一般選擇SATA SSD作為Journal,Intel SSD DC S3500 Series(http://www.intel.com/content/www/us/en/solid-state-drives/solid-state-drives-dc-s3500-series.html)基本是目前看到的方案中的首選。400G的規格4K隨機寫可以達到11000 IOPS。如果在預算足夠的情況下,推薦使用PCIE SSD,性能會得到進一步提升,但是由于Journal在向數據盤寫入數據時Block后續請求,所以Journal的加入并未呈現出想象中的性能提升,但是的確會對Latency有很大的改善。
如何確定你的SSD是否適合作為SSD Journal,可以參考SéBASTIEN HAN的Ceph: How to Test if Your SSD Is Suitable as a Journal Device?(http://www.sebastien-han.fr/blog/2014/10/10/ceph-how-to-test-if-your-ssd-is-suitable-as-a-journal-device/),這里面他也列出了常見的SSD的測試結果,從結果來看SATA SSD中,Intel S3500性能表現最好。
3、BIOS設置(1)Hyper-Threading(HT)
使用超線程(Hyper-Threading)技術,可以實現在一個CPU物理核心上提供兩個邏輯線程并行處理任務,在擁有12個物理核心的E5 2620 v3中,配合超線程,可以達到24個邏輯線程。更多的邏輯線程可以讓操作系統更好地利用CPU,讓CPU盡可能處于工作狀態。基本做云平臺的,VT和HT打開都是必須的,超線程技術(HT)就是利用特殊的硬件指令,把兩個邏輯內核模擬成兩個物理芯片,讓單個處理器都能使用線程級并行計算,進而兼容多線程操作系統和軟件,減少了CPU的閑置時間,提高的CPU的運行效率。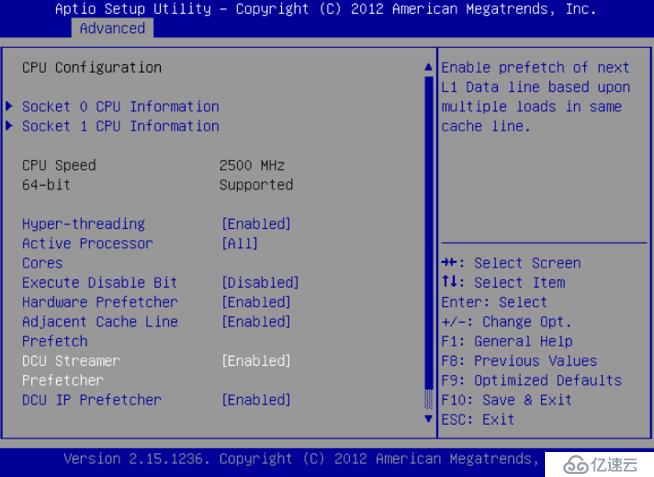
圖1 打開超線程
(2)關閉節能
很多服務器出于能耗考慮,在出場時會在BIOS中打開節能模式,在節能模式下,CPU會根據機器負載動態調整頻率。但是這個動態調頻并不像想象中的那么美好,有時候會因此影響CPU的性能,在像Ceph這種需要高性能的應用場景下,建議關閉節能模式。關閉節能后,對性能還是有所提升的。
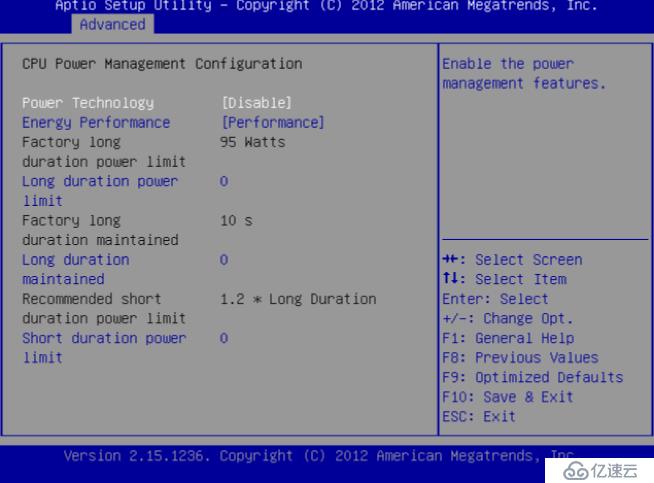
圖2關閉節能
當然也可以在操作系統級別進行調整,詳細的調整過程請參考鏈接(http://www.servernoobs.com/avoiding-cpu-speed-scaling-in-modern-linux-distributions-running-cpu-at-full-speed-tips/),但是不知道是不是由于BIOS已經調整的緣故,所以在CentOS 6.6上并沒有發現相關的設置。
for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done
(3)NUMA
簡單來說,NUMA思路就是將內存和CPU分割為多個區域,每個區域叫做NODE,然后將NODE高速互聯。 node內cpu與內存訪問速度快于訪問其他node的內存,NUMA可能會在某些情況下影響ceph-osd(http://lists.ceph.com/pipermail/ceph-users-ceph.com/2013-December/036211.html)。解決的方案,一種是通過BIOS關閉NUMA,另外一種就是通過cgroup將ceph-osd進程與某一個CPU Core以及同一NODE下的內存進行綁定。但是第二種看起來更麻煩,所以一般部署的時候可以在系統層面關閉NUMA。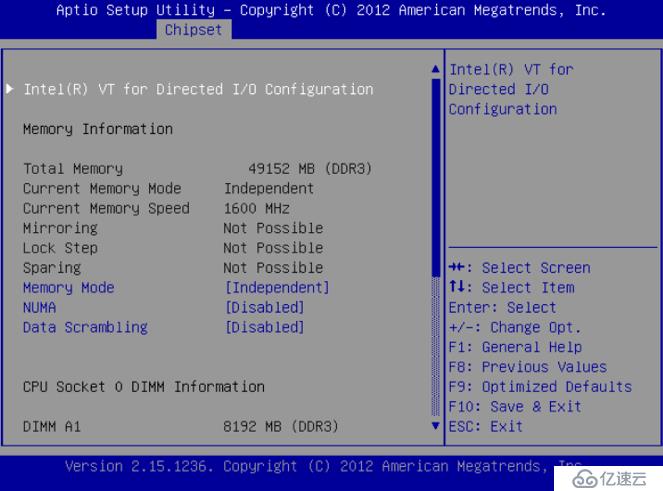
圖3 關閉NUMA
CentOS系統下,通過修改/etc/grub.conf文件,添加numa=off來關閉NUMA。
kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
Linux操作系統在服務器市場中占據了相當大的份額,各種發行版及其衍生版在不同領域中承載著各式各樣的服務。針對不同的應用環境,可以對Linux的性能進行相應的調整,性能調優涵蓋了虛擬內存管理、I/O子系統、進程調度系統、文件系統等眾多內容,這里僅討論對于Ceph性能影響顯著的部分內容。
在Linux的各種發行版中,為了保證對硬件的兼容和可靠性,很多內核參數都采用了較為保守的設置,然而這無法滿足我們對于高性能計算的需求,為了Ceph能更好地利用系統資源,我們需要對部分參數進行調整。
(1)調度
Linux默認的I/O調度一般針對磁盤尋址慢的特性做了專門優化,但對于SSD而言,由于訪問磁盤不同邏輯扇區的時間幾乎是一樣的,這個優化就沒有什么作用了,反而耗費了CPU時間。所以,使用Noop調度器替代內核默認的CFQ。操作如下:
echo noop > /sys/block/sdX/queue/scheduler而機械硬盤設置為:
echo deadline > /sys/block/sdX/queue/scheduler(2)預讀
Linux默認的預讀read_ahead_kb并不適合RADOS對象存儲讀,建議設置更大值:
echo “8192” > /sys/block/sdX/queue/read_ahead_kb(3)進程數量
OSD進程需要消耗大量進程。關于內核PID上限,如果單服務器OSD數量多的情況下,建議設置更大值:
echo 4194303 > /proc/sys/kernel/pid_max調整CPU頻率,使其運行在最高性能下:
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor >/dev/null2、內存(1)SMP和NUMA
SMP(Symmetric Multi Processor)架構中,所有的CPU共享全部資源,如總線、內存和I/O等。多個CPU之間對稱工作,無主從或從屬關系。每個CPU都需要通過總線訪問內存,整個系統中的內存能被每個CPU平等(消耗時間相同)的訪問。然而,在CPU數量不斷增加后,總線的壓力不斷增加,最終導致CPU的處理能力大大降低。
NUMA架構體系中由多個節點組成,每個節點有若干CPU和它們獨立的本地內存組成,各個節點通過互聯模塊(CrossbarSwitch)進行訪問,所以每個CPU可以訪問整個系統的內存。但是,訪問本地內存的速度遠比訪問遠程內存要快,導致在進程發生調度后可能需要訪問遠端內存,這種情況下程序的效率會大大降低。
Ceph目前并未對NUMA架構的內存做過多優化,在日常使用過程中,我們通常使用2~4顆CPU,這種情況下,選擇SMP架構的內存在效率上還是要高一些。如果條件允許,可以通過進程綁定的方法,在保證CPU能盡可能訪問自身內存的前提下,使用NUMA架構。
(2)SWAP
當系統中的物理內存不足時,就需要將一部分內存非活躍(inactive)內存頁置換到交換分區(SWAP)中。有時候我們會發現,在物理內存還有剩余的情況下,交換分區就已經開始被使用了,這就涉及到kernel中關于交換分區的使用策略,由vm.swappiness這個內核參數控制,該參數代表使用交換分區的程度:當值為0時,表示進可能地避免換頁操作;當值為100時,表示kernel會積極的換頁,這會產生大量磁盤IO。因此,在內存充足的情況下,我們一般會將該參數設置為0以保證系統性能。設定Linux操作系統參數:vm.swappiness=0,配置到/etc/sysctl.conf。
(3)內存管理
Ceph默認使用TCmalloc管理內存,在非全閃存環境下,TCmalloc的性能已經足夠。全閃存的環境中,建議增加TCmalloc的Cache大小或者使用jemalloc替換TCmalloc。
增加TCmalloc的Cache大小需要設置環境變量,建議設置為256MB大小:
TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=268435456使用jemalloc需要重新編譯打包Ceph,修改編譯選項:
–with-jemalloc–without-tcmalloc3、CgroupCgroups是control groups的縮寫,是Linux內核提供的一種可以限制、記錄、隔離進程組(process groups)所使用的物理資源(如CPU、Memory、IO等)的機制。最初由Google的工程師提出,后來被整合進Linux內核。Cgroups也是LXC為實現虛擬化所使用的資源管理手段,可以說沒有Cgroups就沒有LXC。Cgroups內容非常豐富,展開討論完全可以單獨寫一篇,這里我們簡單說下Cgroups在Ceph中的應用。
說到Cgroups,就不得不說下CPU的架構,以E5-2620 v3為例(見圖4):整顆CPU共享L3緩存,每個物理核心有獨立的L1和L2緩存,如果開啟超線程后兩個邏輯CPU會共享同一塊L1和L2,所以,在使用Cgroups的時候,我們需要考慮CPU的緩存命中問題。

圖4 E5 2620 v3 CPU拓撲圖
查看CPU的拓撲,可以通過hwloc工具(http://www.open-mpi.org/projects/hwloc/)來辨別CPU號碼與真實物理核心的對應關系。例如在配置2個Intel(R) Xeon(R) CPU E5-2680 v2的服務器,CPU拓撲:
Machine (64GB) NUMANode L#0 (P#0 32GB) Socket L#0 + L3 L#0 (25MB) L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 PU L#0 (P#0) PU L#1 (P#20) L2 L#1 (256KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1 PU L#2 (P#1) PU L#3 (P#21)L2 L#2 (256KB) + L1d L#2 (32KB) + L1i L#2 (32KB) + Core L#2
PU L#4 (P#2)
PU L#5 (P#22)
L2 L#3 (256KB) + L1d L#3 (32KB) + L1i L#3 (32KB) + Core L#3
PU L#6 (P#3)
PU L#7 (P#23)
L2 L#4 (256KB) + L1d L#4 (32KB) + L1i L#4 (32KB) + Core L#4
PU L#8 (P#4)
PU L#9 (P#24)
L2 L#5 (256KB) + L1d L#5 (32KB) + L1i L#5 (32KB) + Core L#5
PU L#10 (P#5)
PU L#11 (P#25)
L2 L#6 (256KB) + L1d L#6 (32KB) + L1i L#6 (32KB) + Core L#6
PU L#12 (P#6)
PU L#13 (P#26)
L2 L#7 (256KB) + L1d L#7 (32KB) + L1i L#7 (32KB) + Core L#7
PU L#14 (P#7)
PU L#15 (P#27)
L2 L#8 (256KB) + L1d L#8 (32KB) + L1i L#8 (32KB) + Core L#8
PU L#16 (P#8)
PU L#17 (P#28)
L2 L#9 (256KB) + L1d L#9 (32KB) + L1i L#9 (32KB) + Core L#9
PU L#18 (P#9)
PU L#19 (P#29)
HostBridge L#0
PCIBridge
PCIBridge
PCIBridge
PCI 8086:1d6a
PCIBridge
PCI 8086:1521
Net L#0 “eno1”
PCI 8086:1521
Net L#1 “eno2”
PCI 8086:1521
Net L#2 “eno3”
PCI 8086:1521
Net L#3 “eno4”
PCIBridge
PCI 1000:0079
Block L#4 “sda”
Block L#5 “sdb”
Block L#6 “sdc”
Block L#7 “sdd”
Block L#8 “sde”
PCIBridge
PCI 102b:0522
GPU L#9 “card0”
GPU L#10 “controlD64”
PCI 8086:1d02
Block L#11 “sr0”
NUMANode L#1 (P#1 32GB)
Socket L#1 + L3 L#1 (25MB)
L2 L#10 (256KB) + L1d L#10 (32KB) + L1i L#10 (32KB) + Core L#10
PU L#20 (P#10)
PU L#21 (P#30)
L2 L#11 (256KB) + L1d L#11 (32KB) + L1i L#11 (32KB) + Core L#11
PU L#22 (P#11)
PU L#23 (P#31)
L2 L#12 (256KB) + L1d L#12 (32KB) + L1i L#12 (32KB) + Core L#12
PU L#24 (P#12)
PU L#25 (P#32)
L2 L#13 (256KB) + L1d L#13 (32KB) + L1i L#13 (32KB) + Core L#13
PU L#26 (P#13)
PU L#27 (P#33)
L2 L#14 (256KB) + L1d L#14 (32KB) + L1i L#14 (32KB) + Core L#14
PU L#28 (P#14)
PU L#29 (P#34)
L2 L#15 (256KB) + L1d L#15 (32KB) + L1i L#15 (32KB) + Core L#15
PU L#30 (P#15)
PU L#31 (P#35)
L2 L#16 (256KB) + L1d L#16 (32KB) + L1i L#16 (32KB) + Core L#16
PU L#32 (P#16)
PU L#33 (P#36)
L2 L#17 (256KB) + L1d L#17 (32KB) + L1i L#17 (32KB) + Core L#17
PU L#34 (P#17)
PU L#35 (P#37)
L2 L#18 (256KB) + L1d L#18 (32KB) + L1i L#18 (32KB) + Core L#18
PU L#36 (P#18)
PU L#37 (P#38)
L2 L#19 (256KB) + L1d L#19 (32KB) + L1i L#19 (32KB) + Core L#19
PU L#38 (P#19)
PU L#39 (P#39)
HostBridge L#7
PCIBridge
PCI 8086:10fb
Net L#12 “enp129s0f0”
PCI 8086:10fb
Net L#13 “enp129s0f1”
由此可見,操作系統識別的CPU號和物理核心是一一對應的關系,在對程序做CPU綁定或者使用Cgroups進行隔離時,注意不要跨CPU,以便更好地命中內存和緩存。另外也看到,不同HostBridge的對應PCI插槽位置不一樣,管理著不同的資源,CPU中斷設置時候也需要考慮這個因素。
總結一下,使用Cgroups的過程中,我們應當注意以下問題:
· 防止進程跨CPU核心遷移,以更好的利用緩存;
· 防止進程跨物理CPU遷移,以更好的利用內存和緩存;
· Ceph進程和其他進程會互相搶占資源,使用Cgroups做好隔離措施;
· 為Ceph進程預留足夠多的CPU和內存資源,防止影響性能或產生OOM。尤其是高性能環境中并不能完全滿足Ceph進程的開銷,在高性能場景(全SSD)下,每個OSD進程可能需要高達6GHz的CPU和4GB以上的內存。
因為優化部分涉及內容較多,所以分為兩篇文章來講述,希望本文能夠給予Ceph新手參考,請讀者見仁見智,預知后事如何,請期待《部署調優關卡之調優二》。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





