溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
之前有不少同學看過我的個人博客(http://python-online.cn),也根據我寫的教程完成了自己個人站點的搭建。
點此:使用 Python 30分鐘 教你快速搭建一個博客
為防有的同學不清楚 Sphinx ,這里還是做下簡單的介紹。
它是一個能夠把一組 reStructuredText 或者 Markdown 格式的文件轉換成各種輸出格式,而且自動地生成交叉引用,生成目錄等的一個文檔編排工具。
不得不說,它的排版功能強大、非常清晰,顔值非常高。
但是使用這個方法搭建的博客,一直有一個痛點,就是無法自定義頁面,自由度非常的低(和 WordPress 真的沒法比)。
這就導致我一直不知道到底有沒有人訪問我的網站?
他們都是從哪來訪問的,Google 還是 百度?
每篇文章都有多少人訪問,哪篇文章最受歡迎?
我一直在我的博客上×××底因×××少呢?
因此我一直希望能找到一個能夠收集網站訪問數據、并且能將博客上的訪×××
終于在昨天,我找到了,并花了兩天的時間成功上線。
方法就是引入兩個 JavaSript 插件實現(這個在早期的 Sphinx 版本中是不支持的)。
第一個插件:導流工具
作用:這個主要用來將自己博客上流量引×××是思路是:
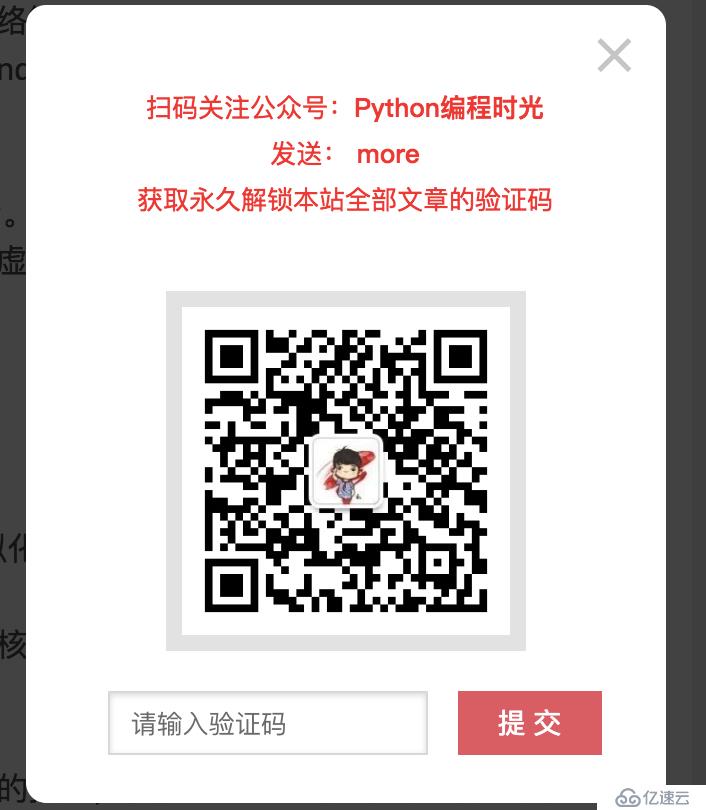
游客無法閱讀博客的全部內容,因為會有一半的內容會被隱藏。就像這樣。

如想要閱讀全文,可以點擊全文進行解鎖:用微信掃描二維×××ore` ,將獲取到的驗證碼填入如下文本框提交即可永久解鎖本博客的所有干貨文章。
思路有了,那么如何實現呢?
以上功能其實已經有人已經做出來并可以提供免費使用。
你可以在 https://openwrite.cn/ 注冊一個帳號,然后在里面你可以看到一個導流工具,×××信息后,就初始化成功,獲得一串js代碼。
接下來,你要做的就是將這串js接入你的博客頁面中。
由于我去年搭建這個博客時使用的 Sphinx 的版本是 1.7 ,這個版本是不支持自定義css/js 文件的。
因此,你要使用引入這段js代碼,需要將你的 Sphinx 升級到 1.8+,我使用的是最新版本的 2.1 ,這個版本只支持 Python 3.5+。
因此在使用之前,我得先將環境的切換至 Python 3.5+。
virtualenv -p /usr/bin/python3.6 myblog然后安裝 Sphinx 及相關包
pip install Sphinx sphinx-rtd-theme -i https://pypi.douban.com/simple問題一
雖然現在我們的 Sphinx 已經支持自定義js了(方法是將一個js文件以引用的方式放在 header 標簽里)
但是 OpenWrite 要實現 閱讀全文 的效果,這個readmore.js必須放在 HTML 的尾部,意思是要等頁面加載完成后才能起作用。
這下就尷尬了。Sphinx 會將 readmore.js 放在 HTML 頂部,而要實現 閱讀全文 的效果,readmore.js 需要放在底部。由于框架是固定的,我們無法對其進行定制修改。那還有什么方法可以補救呢?
我的方案是:在 readmore.js 中加入邏輯,當頁面加載完成后再運行。
問題二
若想 readmore.js 起作用,前提是你的文章的正文div中需要有一個id=‘container’屬性, 而這個 Sphinx 是不會生成的。
這樣的話,這個動態添加 id 屬性的工作也只能交由 readmore.js 來做了。
問題三
由 Sphinx 生成的的所有頁面都會加引入這個 readmore.js 插件,這就導致所有的頁面(包括首頁,索引頁)都會有 閱讀全文 的限制。這明顯是不合理的。
為了解決這個問題,我想的是在 readmore.js 中,根據 url 進行判斷,只有文章頁面才有限制,而其他的頁面則不受限制。
總結一下,這個 readmore.js 會做三件事:
如果你不想自己寫,可×××流”,直接用我寫好的js文件。
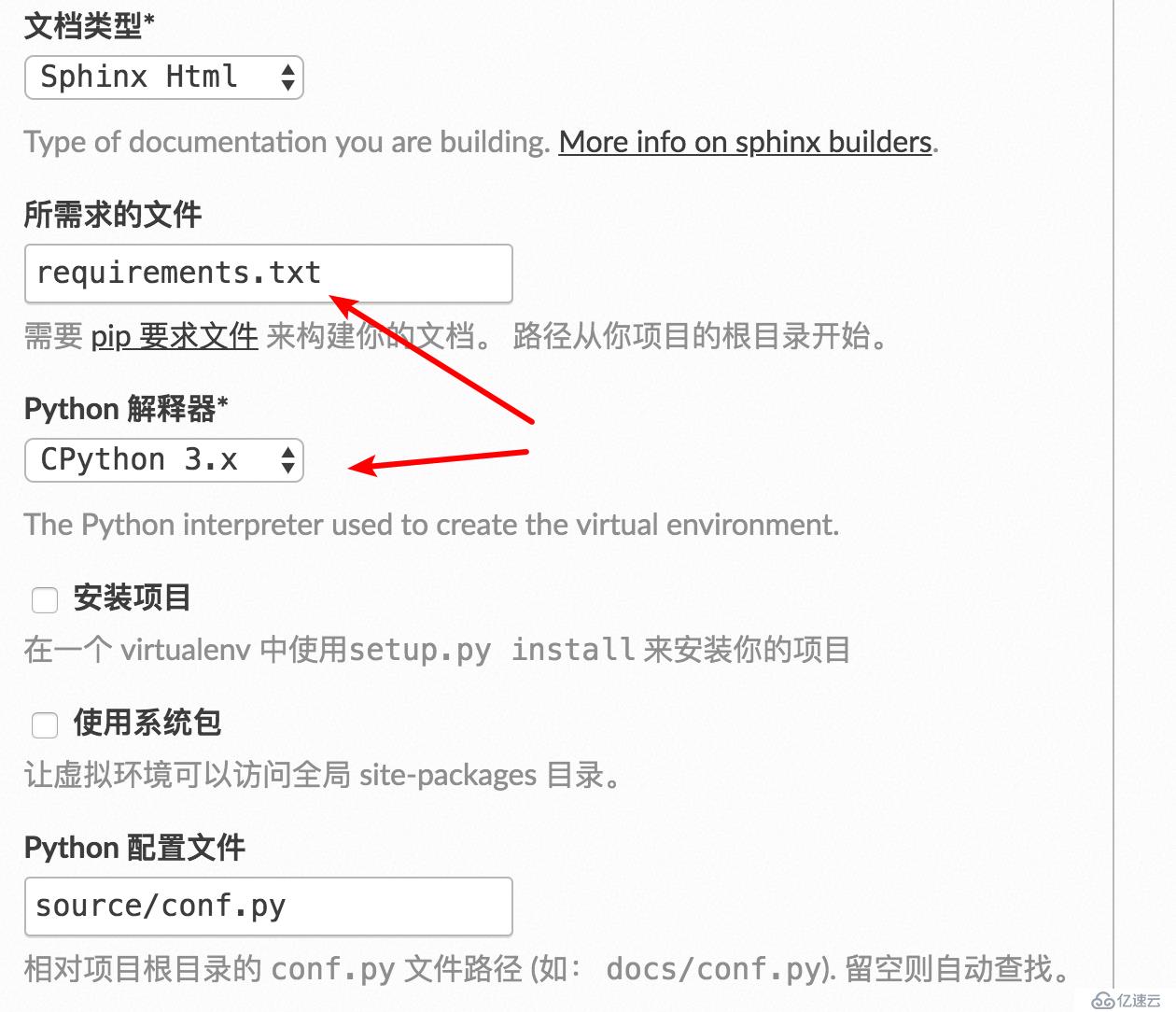
獲取到的js文件需要放在固定的路徑下: source/_static/js/ (如果沒有此路徑就手動創建),然后修改 conf.py
html_static_path = ['_static']
html_js_files = [
'js/readmore.js',
]按理說,這樣就已經大功告成了。
但是別忘了,我們是用 readthedocs 生成我們的博客頁面的。
為此,我們同樣也要在 readthedocs 進行相關的配置。
(注:使用 pip freeze >requirements.txt 生成)
同時你如果之前是看過我寫的教程,使用過我的中文檢索插件,那你要注意了。
此前這個插件是基于 Python 2.x 寫的,現在我們切換成 Sphinx 項目切換成 Python 3.x ,所以這里的代碼也要對應修改。
改動也不大,只要把 exts/smallseg.py 這個文件里的 decode 相關的代碼全部去掉即可。
一切按照上面的步驟全部設置完成后,提交Github后,再次從 readthedocs 構建就可以看到效果了。
對于這個功能,我幾點要說明:
第二個插件:百度統計
作用:用于收集個人網站的訪問數據。
有了上面的經驗,現在我們知道如何在頁面中插件自定義 js 代碼。
那我就想有沒有那種可以通過引入 js 插件來收集網站的訪問數據呢?
這種工具應該不少,而我使用的是百度家的產品 - 百度統計 。
它可以幫我們收集網站訪問數據,提供流量趨勢、來源分析、轉化跟蹤、頁面熱力圖、訪問流等多種統計分析服務。
那怎么使用呢?
首先使用你的百度帳號登陸 百度統計。
然后在網站列表新增一個你的網站,我的信息如下:
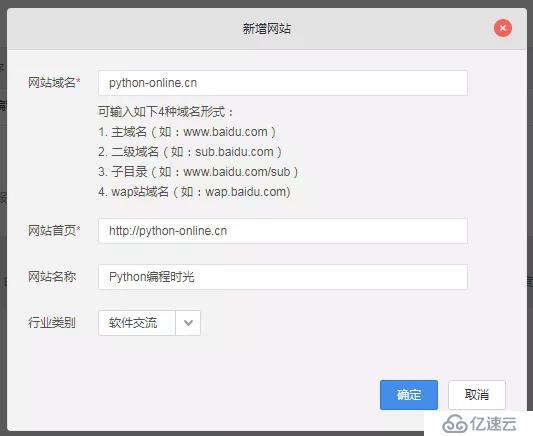
填寫完成,就可以獲取一段屬于你的網站的專屬 js 代碼(下面第一步)。
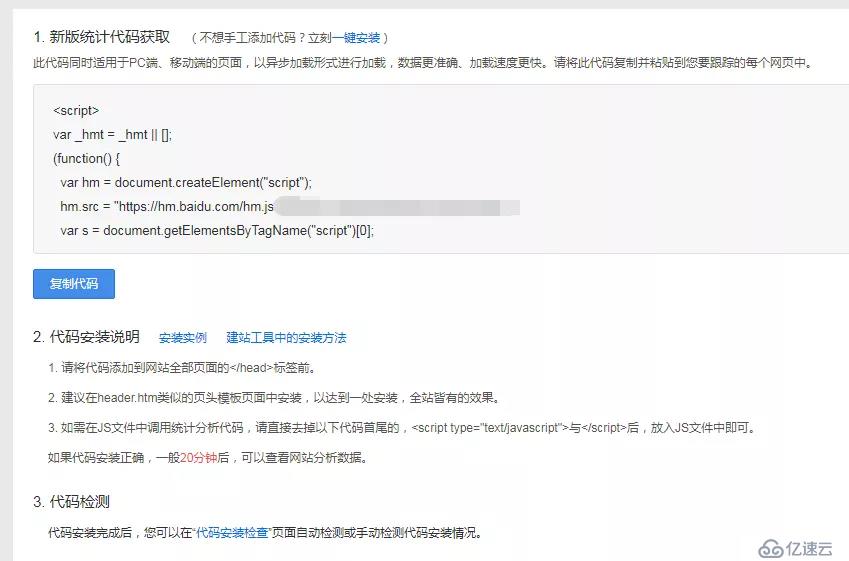
第二步內容,是教你如何安裝這段 js 代碼。
將這段代碼內容寫入一個單獨的 js 文件:baidu#js
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://#/hm.js?xxxxxxxx";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();并修改 conf.py 后,提交至你的 Github。
html_js_files = [
'js/readmore.js',
'js/baidu#js'
]一切完成后,就可以去 readthedocs 重建構建。
構建完成后,去執行第三步,代碼安裝檢查。像我下面這樣,就是安裝完成了。
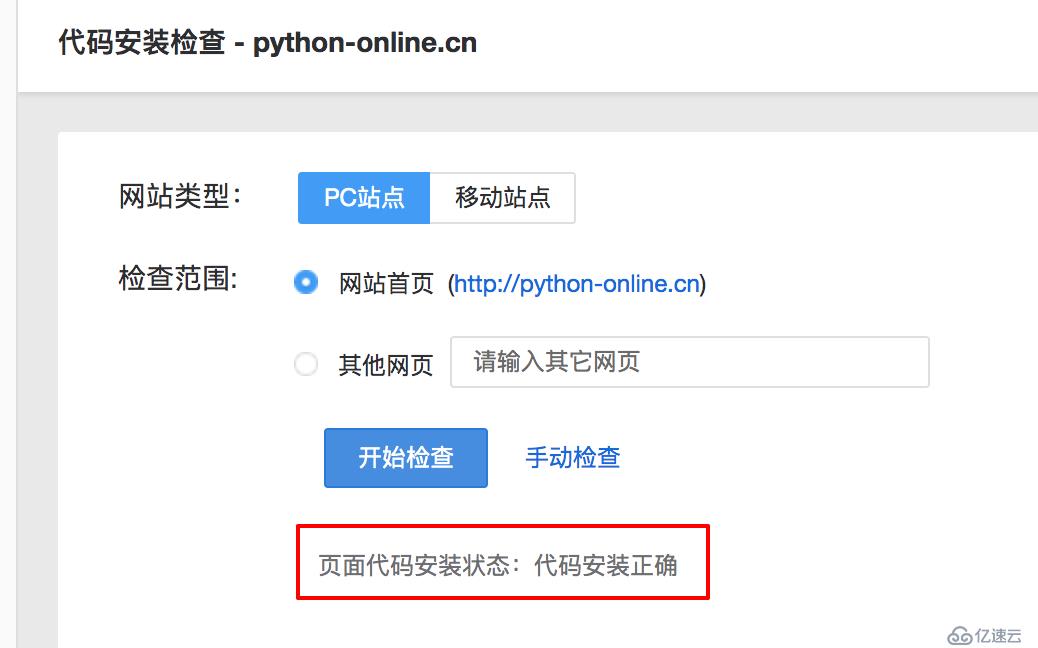
這個插件安裝完成后,如果你的網站有流量,可以過個一個小時,點擊一下查看報告查看你網站的詳細訪問數據。
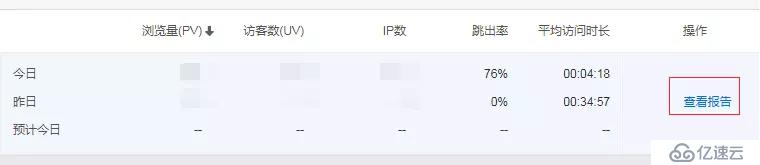
數據真的非常全面,你可以知道,訪客都是從哪里訪問(直接訪問,Google等),每篇文章的點擊量(你就知道哪篇是爆款?),每天有多少老訪問客,多少新訪客等等,更多維度的數據你可以自己去體驗一下。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





