溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“web前端怎么實現圖片選擇題特效”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“web前端怎么實現圖片選擇題特效”文章能幫助大家解決問題。
抽象整體的實現思路如下
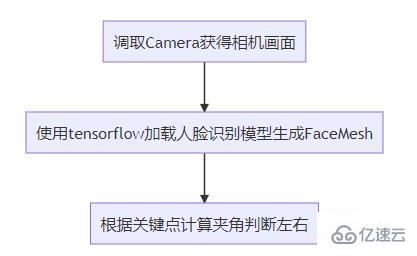
MediaPipe Face Mesh是一個解決方案,即使在移動設備上也能實時估計468個3D面部地標。它使用機器學習(ML)來推斷3D面部表面,只需要一個攝像頭輸入,而無需專用的深度傳感器。該解決方案利用輕量級模型架構以及整個管道中的GPU加速,為實時體驗提供了至關重要的實時性能。
import '@mediapipe/face_mesh';
import '@tensorflow/tfjs-core';
import '@tensorflow/tfjs-backend-webgl';
import * as faceLandmarksDetection from '@tensorflow-models/face-landmarks-detection';
引入tensorflow訓練好的人臉特征點檢測模型,預測 486 個 3D 人臉特征點,推斷出人臉的近似面部幾何圖形。
maxFaces 默認為1。模型將檢測到的最大人臉數量。返回的面孔數量可以小于最大值(例如,當輸入中沒有人臉時)。強烈建議將此值設置為預期的最大人臉數量,否則模型將繼續搜索缺失的面孔,這可能會減慢性能。
refineLandmarks 默認為false。如果設置為真,則細化眼睛和嘴唇周圍的地標坐標,并在虹膜周圍輸出其他地標。(這里我可以設置false,因為我們沒有用到眼部坐標)
solutionPath 通往am二進制文件和模型文件所在位置的路徑。(強烈建議將模型放到國內的對象存儲里面,首次加載可以節省大量時間,大小大概10M)
async createDetector(){
const model = faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;
const detectorConfig = {
maxFaces:1, //檢測到的最大面部數量
refineLandmarks:false, //可以完善眼睛和嘴唇周圍的地標坐標,并在虹膜周圍輸出其他地標
runtime: 'mediapipe',
solutionPath: 'https://cdn.jsdelivr.net/npm/@mediapipe/face_mesh', //WASM二進制文件和模型文件所在的路徑
};
this.detector = await faceLandmarksDetection.createDetector(model, detectorConfig);
}

返回的面孔列表包含圖像中每個面孔的檢測面。如果模型無法檢測到任何面孔,列表將是空的。 對于每個面,它包含一個檢測到的面孔的邊界框,以及一個關鍵點數組。MediaPipeFaceMesh返回468個關鍵點。每個關鍵點都包含x和y,以及一個名稱。
現在,您可以使用探測器來檢測人臉。estimateFaces方法接受多種格式的圖像和視頻,包括:
HTMLVideoElement、HTMLImageElement、HTMLCanvasElement和Tensor3D。
flipHorizontal 可選。默認為false。當圖像數據來自相機時,結果必須水平翻轉。
async renderPrediction() {
var video = this.$refs['video'];
var canvas = this.$refs['canvas'];
var context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const Faces = await this.detector.estimateFaces(video, {
flipHorizontal:false, //鏡像
});
if (Faces.length > 0) {
this.log(`檢測到人臉`);
} else {
this.log(`沒有檢測到人臉`);
}
}

該框表示圖像像素空間中面部的邊界框,xMin、xMax表示x-bounds、yMin、yMax表示y-bounds,寬度、高度表示邊界框的尺寸。 對于關鍵點,x和y表示圖像像素空間中的實際關鍵點位置。z表示頭部中心為原點的深度,值越小,鍵點離相機越近。Z的大小使用與x大致相同的比例。 這個名字為一些關鍵點提供了一個標簽,例如“嘴唇”、“左眼”等。請注意,并非每個關鍵點都有標簽。
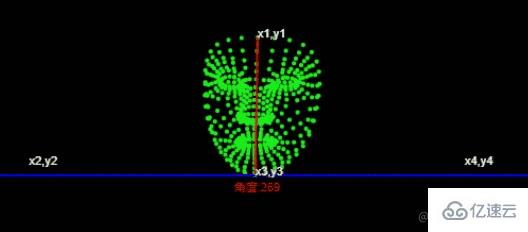
找到人臉上的兩個兩個點
第一個點 額頭中心位置第二個點 下巴中心位置
const place1 = (face.keypoints || []).find((e,i)=>i===10); //額頭位置
const place2 = (face.keypoints || []).find((e,i)=>i===152); //下巴位置
/*
x1,y1
|
|
|
x2,y2 -------|------- x4,y4
x3,y3
*/
const [x1,y1,x2,y2,x3,y3,x4,y4] = [
place1.x,place1.y,
0,place2.y,
place2.x,place2.y,
this.canvas.width, place2.y
];
通過canvas.width 額頭中心位置和下巴中心位置計算出 x1,y1,x2,y2,x3,y3,x4,y4
getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)
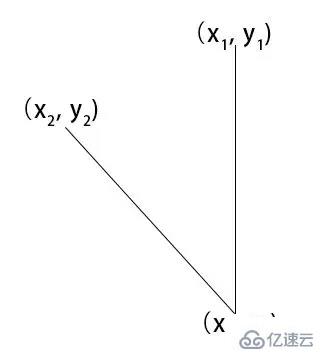
通過獲取角度,通過角度的大小來判斷左右擺頭。
關于“web前端怎么實現圖片選擇題特效”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





