溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“mysql如何實現合并結果集并去除重復值”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
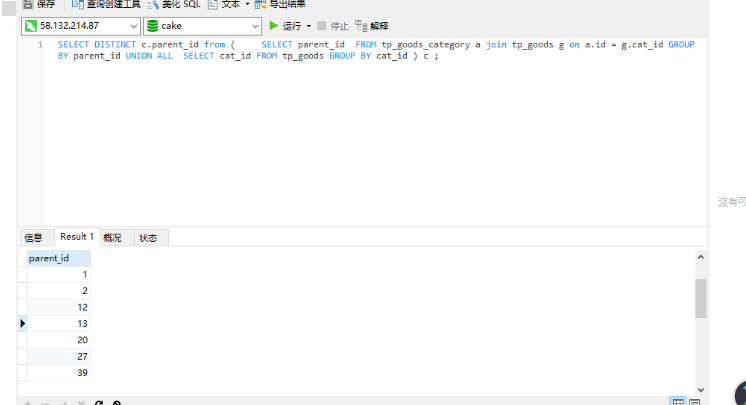
SELECT DISTINCT c.parent_id from ( SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id UNION ALL SELECT cat_id FROM tp_goods GROUP BY cat_id ) c;
先去除每個結果集中的重復值 以 group by 方式除去
SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id SELECT cat_id FROM tp_goods GROUP BY cat_id
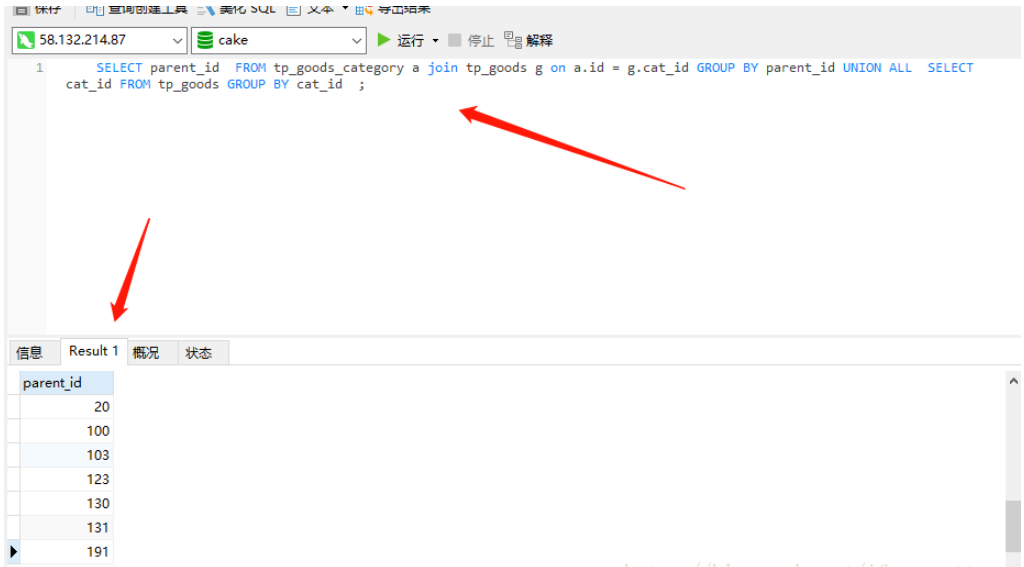
然后合并兩個結果集 生成一個新的結果集 (或者可以成為新表) 在 使用DISTINCT 去除合并結果集中的重復值 注意 必須給 新結果集取一個別名 比如例子中的 c

新的查詢結果
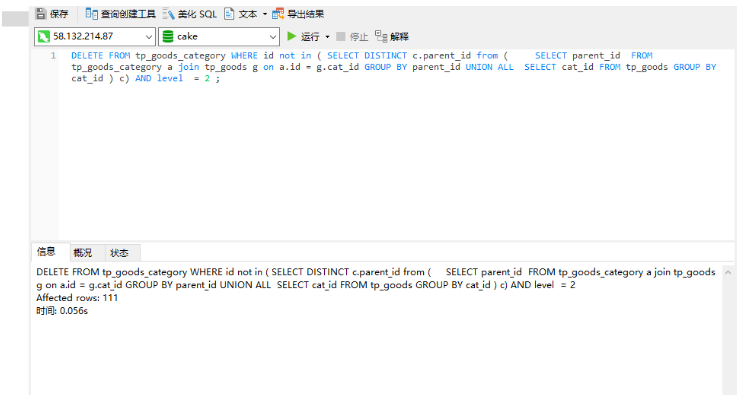
此語句為了刪除分類表中 在goods表中不存在的 分類id 且 級別為第二級別
我需要在一個sql的執行結果中,顯示兩個或兩個以上的where條件的結果(select 列的結構相同)。
考慮使用union,或union all 。
UNION 刪除重復的記錄再返回結果,即對整個結果集合使用了DISTINCT。結果中無重復數據。
UNION ALL 將各個結果合并后就返回,不刪除重復記錄。如果結果中有重復數據,則包含重復數據。
例如,
mysql> SELECT * FROM world.city where ID=2020 UNION SELECT * FROM world.city where ID=2020; +------+-------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+--------------+------------+ | 2020 | Tieli | CHN | Heilongjiang | 265683 | +------+-------+-------------+--------------+------------+ 1 row in set (0.00 sec) mysql> SELECT * FROM world.city where ID=2020 UNION ALL SELECT * FROM world.city where ID=2020; +------+-------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+--------------+------------+ | 2020 | Tieli | CHN | Heilongjiang | 265683 | | 2020 | Tieli | CHN | Heilongjiang | 265683 | +------+-------+-------------+--------------+------------+ 2 rows in set (0.00 sec)
比如要對合并后的結果集進行ORDER BY,LIMIT等操作需要對合并對象單個的SELECT語句加上括號。
并且把整體結果的條件ORDER BY,LIMIT等放到最后一個SELECT的括號后面。
例如,
(SELECT * FROM world.city WHERE CountryCode = 'JPN' AND Name LIKE 'nishi%') UNION ALL (SELECT * FROM world.city WHERE CountryCode = 'CHN' AND Population >= 5000000) LIMIT 5;
從效率上說,UNION ALL 要比UNION快很多。
所以,如果可以確認合并的結果集中不包含重復的數據的話,或者需要的結果中即使包含重復也無所謂,那么就使用UNION ALL。
UNION
UNION在進行表鏈接后會篩選掉重復的記錄,所以在表鏈接后會對所產生的結果集進行排序運算。
UNION在運行時先取出各個表/各個select的結果,再用排序空間進行排序刪除重復的記錄,最后返回結果集,如果表數據量大的話可能會導致用磁盤進行排序。
UNION ALL
UNION ALL只是簡單的將結果合并后就返回。不涉及排序運算。
“mysql如何實現合并結果集并去除重復值”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





