溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了MySQL中實用的知識點有哪些的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇MySQL中實用的知識點有哪些文章都會有所收獲,下面我們一起來看看吧。
在我們平常的工作中,使用group by進行分組的場景,是非常多的。
比如想統計出用戶表中,名稱不同的用戶的具體名稱有哪些?
具體sql如下:
SELECT name FROM `user` GROUP BY name;
但如果想把name相同的code拼接在一起,放到另外一列中該怎么辦呢?
答:使用group_concat函數。
例如:
SELECT name,group_concat(code) FROM `user` GROUP BY name;
執行結果:
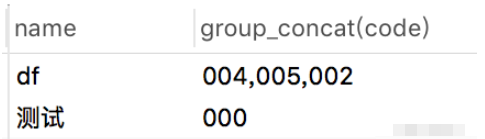
使用group_concat函數,可以輕松的把分組后,name相同的數據拼接到一起,組成一個字符串,用逗號分隔。
有時候我們需要獲取字符的長度,然后根據字符的長度進行排序。
MYSQL給我們提供了一些有用的函數,比如:char_length。
通過該函數就能獲取字符長度。
獲取字符長度并且排序的sql如下:
SELECT user_id,user_name FROM `sys_user` WHERE user_name LIKE '%JM%' ORDER BY CHAR_LENGTH(user_name) ASC LIMIT 5;
執行效果如圖所示:
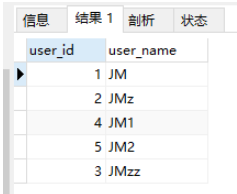
name字段使用關鍵字模糊查詢之后,再使用char_length函數獲取name字段的字符長度,然后按長度升序。
有時候我們在查找某個關鍵字,比如:JM,需要明確知道它在某個字符串中的位置時,該怎么辦呢?
答:使用locate函數。
使用locate函數改造之后sql如下:
SELECT user_id,user_name FROM `sys_user` WHERE user_name LIKE '%JM%'
ORDER BY CHAR_LENGTH(user_name) ASC, LOCATE('JM',user_name) LIMIT 2,2;執行結果:
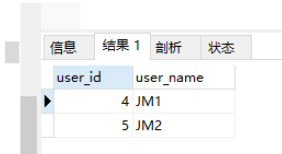
先按長度排序,小的排在前面。如果長度相同,則按關鍵字從左到右進行排序,越靠左的越排在前面。
除此之外,我們還可以使用:instr和position函數,它們的功能跟locate函數類似,在這里我就不一一介紹了。
我們經常會有替換字符串中部分內容的需求,比如:將字符串中的字符A替換成B。
這種情況就能使用replace函數。
例如:
UPDATE sys_user set user_name=REPLACE(user_name,'A','B') WHERE user_id=1;
這樣就能輕松實現字符替換功能。
也能用該函數去掉前后空格:
UPDATE sys_user set user_name=REPLACE(user_name,' ','') WHERE user_name LIKE ' %'; UPDATE sys_user set user_name=REPLACE(user_name,' ','') WHERE user_name LIKE '% ';
使用該函數還能替換json格式的數據內容,真的非常有用。
時間是個好東西,用它可以快速縮小數據范圍,我們經常有獲取當前時間的需求。
在MYSQL中獲取當前時間,可以使用now()函數,例如:
SELECT now() FROM sys_user LIMIT 1;
返回結果為下面這樣的:
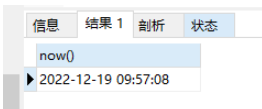
它會包含年月日時分秒。
如果你還想返回毫秒,可以使用now(3),例如:
SELECT now(3) FROM sys_user LIMIT 1;
返回結果為下面這樣的:
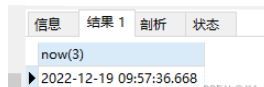
使用起來非常方便好記。
在工作中很多時候需要插入數據。
傳統的插入數據的sql是這樣的:
INSERT INTO `sys_user`(`user_id`, `dept_id`, `user_name`, `create_time`) VALUES (6, '103', 'JM', now());
它主要是用于插入少量并且已經確定的數據。但如果有大批量的數據需要插入,特別是是需要插入的數據來源于,另外一張表或者多張表的結果集中。
這種情況下,使用傳統的插入數據的方式,就有點束手無策了。
這時候就能使用MYSQL提供的:insert into ... select語法。
例如:
INSERT INTO `sys_user`(`user_id`, `dept_id`, `user_name`, `create_time`)
SELECT null,dept_id,user_name,now(3) FROM `sys_user_backup` WHERE dept_id in ('103','105');這樣就能將用戶備份表中的部分數據,非常輕松插入到用戶表中。
不知道你有沒有遇到過這樣的場景:在插入1000個用戶之前,需要先根據user_name,判斷一下是否存在。如果存在,則不插入數據。如果不存在,才需要插入數據。
如果直接這樣插入數據:
INSERT INTO `sys_user`(`id`, `dept_id`, `user_name`, `create_time`) VALUES (6, '103', 'JM', now());
肯定不行,因為sys_user表的user_name字段創建了唯一索引,同時該表中已經有一條user_name等于JM的數據了。
執行之后直接報錯了:
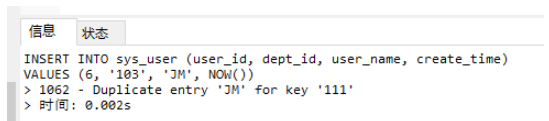
這就需要在插入之前加一下判斷。
當然很多人通過在sql語句后面拼接not exists語句,也能達到防止出現重復數據的目的,比如:
INSERT INTO `sys_user`(`user_id`, `dept_id`, `user_name`, `create_time`) SELECT null,dept_id,user_name,now(3) FROM sys_user_backup WHERE not exists (SELECT * FROM `sys_user` WHERE user_name = 'JM')
這條sql確實能夠滿足要求,但是總覺得有些麻煩。那么,有沒有更簡單的做法呢?
答:可以使用insert into ... ignore語法。
例如:
INSERT ignore INTO `sys_user`(`user_id`, `dept_id`, `user_name`, `create_time`) VALUES (123, '105', 'JM', now(3));
這樣改造之后,如果sys_user表中沒有user_name為JM的數據,則可以直接插入成功。
但如果sys_user表中已經存在user_name為JM的數據了,則該sql語句也能正常執行,并不會報錯。因為它會忽略異常,返回的執行結果影響行數為0,它不會重復插入數據。
MYSQL數據庫自帶了悲觀鎖,它是一種排它鎖,根據鎖的粒度從大到小分為:表鎖、間隙鎖和行鎖。
在我們的實際業務場景中,有些情況并發量不太高,為了保證數據的正確性,使用悲觀鎖也可以。
比如:用戶扣減積分,用戶的操作并不集中。但也要考慮系統自動贈送積分的并發情況,所以有必要加悲觀鎖限制一下,防止出現積分加錯的情況發生。
這時候就可以使用MYSQL中的select ... for update語法了。
例如:
BEGIN; SELECT * FROM `sys_user` where user_id=1 FOR UPDATE; //業務邏輯處理 UPDATE `sys_user` SET score = score -1 WHERE user_id=1; COMMIT;
這樣在一個事務中使用for update鎖住一行記錄,其他事務就不能在該事務提交之前,去更新那一行的數據。
需要注意的是for update前的id條件,必須是表的主鍵或者唯一索引,不然行鎖可能會失效,有可能變成表鎖。
通常情況下,我們在插入數據之前,一般會先查詢一下,該數據是否存在。如果不存在,則插入數據。如果已存在,則不插入數據,而直接返回結果。
在沒啥并發量的場景中,這種做法是沒有什么問題的。但如果插入數據的請求,有一定的并發量,這種做法就可能會產生重復的數據。
當然防止重復數據的做法很多,比如:加唯一索引、加分布式鎖等。
但這些方案,都沒法做到讓第二次請求也更新數據,它們一般會判斷已經存在就直接返回了。
這種情況可以使用on duplicate key update語法。
該語法會在插入數據之前判斷,如果主鍵或唯一索引不存在,則插入數據。如果主鍵或唯一索引存在,則執行更新操作。
具體需要更新的字段可以指定,例如:
INSERT INTO `sys_user`(`user_id`, `dept_id`, `user_name`, `create_time`) VALUES (null, '103', 'JM', now()) OM DUPLICATE KEY UPDATE user_name='JM',create_time=now();
這樣一條語句就能輕松搞定需求,既不會產生重復數據,也能更新最新的數據。
但需要注意的是,在高并發的場景下使用on duplicate key update語法,可能會存在死鎖的問題,所以要根據實際情況酌情使用。
有時候,我們想快速查看某張表的字段情況,通常會使用desc命令,比如:
DESC `sys_dept`;
結果如圖所示:
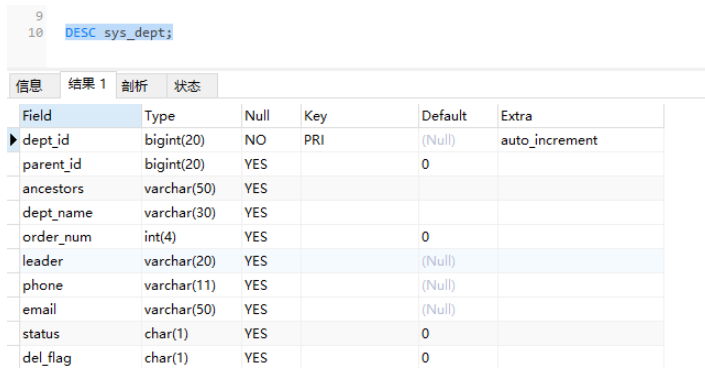
確實能夠看到sys_dept表中的字段名稱、字段類型、字段長度、是否允許為空,是否主鍵、默認值等信息。
但看不到該表的索引信息,如果想看創建了哪些索引,該怎么辦呢?
答:使用show index命令。
比如:
SHOW INDEX FROM sys_dept;
也能查出該表所有的索引:

但查看字段和索引數據呈現方式,總覺得有點怪怪的,有沒有一種更直觀的方式?
答:這就需要使用show create table命令了。
例如:
show create table `order`;
執行結果如圖所示:
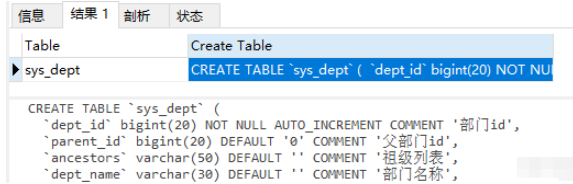
其中Table表示表名,Create Table就是我們需要看的建表信息,將數據展開:我們能夠看到非常完整的建表語句,表名、字段名、字段類型、字段長度、字符集、主鍵、索引、執行引擎等都能看到。
非常直接明了。
有時候,我們需要快速備份表。
通常情況下,可以分兩步走:
創建一張臨時表
將數據插入臨時表
創建臨時表可以使用命令:
CREATE TABLE user_20221219 LIKE `sys_user`;
創建成功之后,就會生成一張名稱叫:user_20221219,表結構跟sys_user一模一樣的新表,只是該表的數據為空而已。
接下來使用命令:
INSERT INTO user_20221219 SELECT * FROM `sys_user`;
執行之后就會將order表的數據插入到user_20221219表中,也就是實現數據備份的功能。
但有沒有命令,一個命令就能實現上面這兩步的功能呢?
答:用create table ... select命令。
例如:
CREATE TABLE user_20221219SELECT * FROM `sys_user`;
執行完之后,就會將user_20221219表創建好,并且將sys_user表中的數據自動插入到新創建的user_20221219中。
一個命令就能輕松搞定表備份。
很多時候,我們優化一條sql語句的性能,需要查看索引執行情況。
答:可以使用explain命令,查看mysql的執行計劃,它會顯示索引的使用情況。
例如:
EXPLAIN SELECT * FROM `sys_user` WHERE dept_id=103;
結果:

通過這幾列可以判斷索引使用情況,執行計劃包含列的含義如下圖所示:
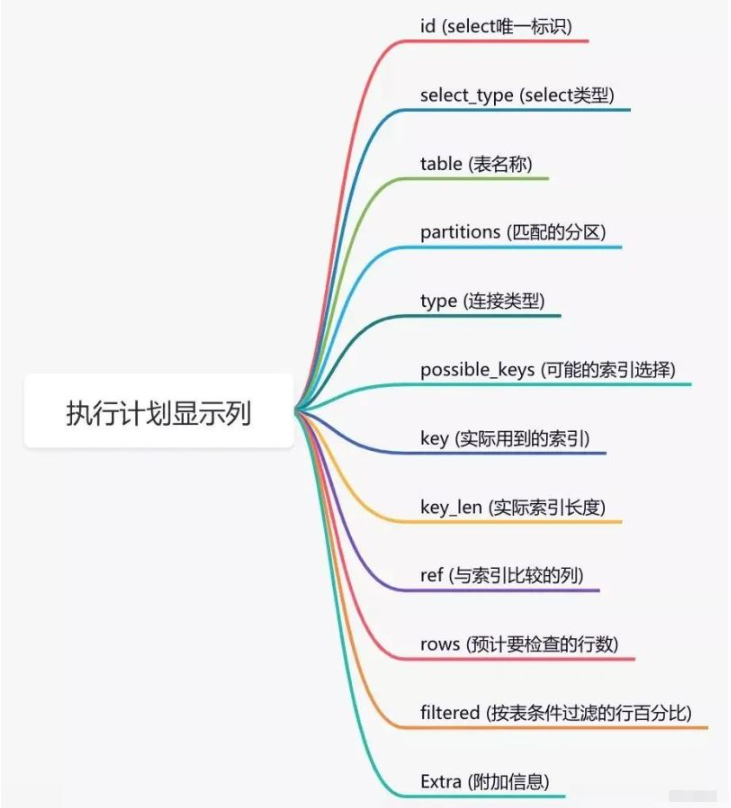
說實話,sql語句沒有走索引,排除沒有建索引之外,最大的可能性是索引失效了。
下面說說索引失效的常見原因:
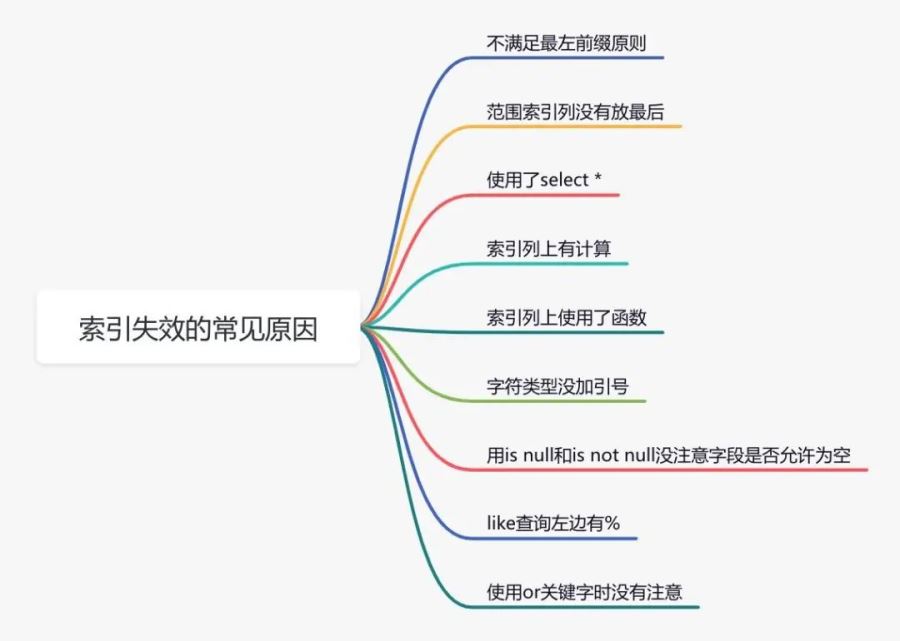
如果不是上面的這些原因,則需要再進一步排查一下其他原因。
有些時候我們線上sql或者數據庫出現了問題。比如出現了數據庫連接過多問題,或者發現有一條sql語句的執行時間特別長。
這時候該怎么辦呢?
答:我們可以使用show processlist命令查看當前線程執行情況。
如圖所示:
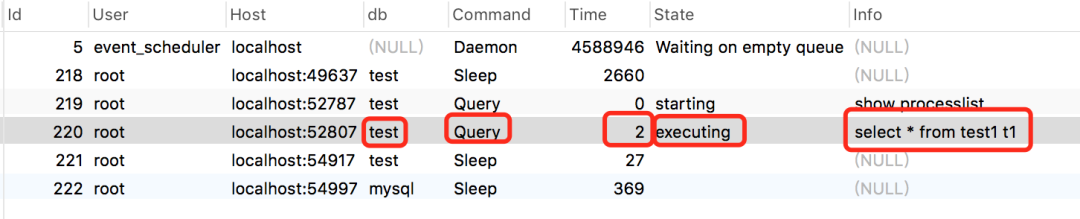
從執行結果中,我們可以查看當前的連接狀態,幫助識別出有問題的查詢語句。
id 線程id
User 執行sql的賬號
Host 執行sql的數據庫的ip和端號
db 數據庫名稱
Command 執行命令,包括:Daemon、Query、Sleep等。
Time 執行sql所消耗的時間
State 執行狀態
info 執行信息,里面可能包含sql信息。
如果發現了異常的sql語句,可以直接kill掉,確保數據庫不會出現嚴重的問題。
有時候我們需要導出MYSQL表中的數據。
這種情況就可以使用mysqldump工具,該工具會將數據查出來,轉換成insert語句,寫入到某個文件中,相當于數據備份。
我們獲取到該文件,然后執行相應的insert語句,就能創建相關的表,并且寫入數據了,這就相當于數據還原。
mysqldump命令的語法為:mysqldump -h主機名 -P端口 -u用戶名 -p密碼 參數1,參數2.... > 文件名稱.sql
備份遠程數據庫中的數據庫:
mysqldump -h 192.22.25.226 -u root -p123456 dbname > backup.sql
關于“MySQL中實用的知識點有哪些”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“MySQL中實用的知識點有哪些”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





