溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“MySQL中order by排序語句的原理是什么”,內容詳細,步驟清晰,細節處理妥當,希望這篇“MySQL中order by排序語句的原理是什么”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
order by 是怎么工作的?
表定義
CREATE TABLE `t1` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB;
SQL語句可以這樣寫:
select city,name,age from t1 where city='杭州' order by name limit 1000
全字段排序
用 explain 命令來看看這個語句的執行情況。

其中Using index condition是索引下推優化(索引下推簡介),Using filesort 表示的就是需要排序,MySQL 會給每個線程分配一塊內存用于排序,稱為 sort_buffer。
city索引的示意圖。
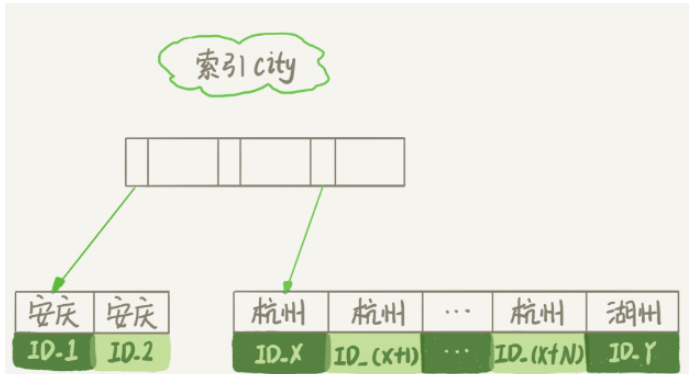
從圖中可以看到,滿足 city='杭州’條件的行,是從 ID_X 到 ID_(X+N) 的這些記錄。
通常情況下,這個語句執行流程如下所示 :
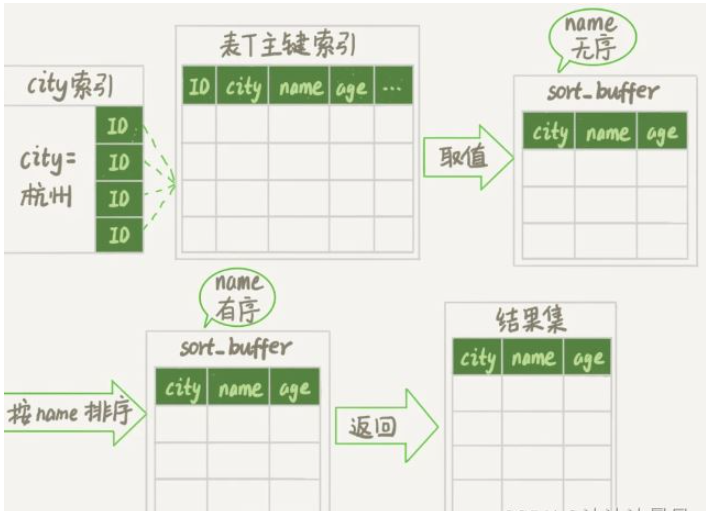
初始化 sort_buffer,確定放入 name、city、age 這三個字段;
從索引 city 找到第一個滿足 city='杭州’條件的主鍵 id,也就是圖中的 ID_X;
到主鍵 id 索引取出整行,取 name、city、age 三個字段的值,存入 sort_buffer 中;
從索引 city 取下一個記錄的主鍵 id;
重復步驟 3、4 直到 city 的值不滿足查詢條件為止,對應的主鍵 id 也就是圖中的 ID_Y;
對 sort_buffer 中的數據按照字段 name 做快速排序;
按照排序結果取前 1000 行返回給客戶端。
這個是它的排序過程,叫做全字段排序,執行流程示意圖如下所示。
按 name 排序”這個動作,可能在內存中完成,也可能需要使用外部排序,這取決于排序所需的內存和參數 sort_buffer_size。
sort_buffer_size,就是 MySQL 為排序開辟的內存(sort_buffer)的大小。
要排序的數據量小于 sort_buffer_size,排序就在內存中完成。
要排序數據量太大,內存放不下,利用磁盤臨時文件輔助排序。
可以用下面介紹的方法,來確定一個排序語句是否使用了臨時文件。
/* 打開optimizer_trace,只對本線程有效 */ SET optimizer_trace='enabled=on'; /* @a保存Innodb_rows_read的初始值 */ select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 執行語句 */ select city, name,age from t where city='杭州' order by name limit 1000; /* 查看 OPTIMIZER_TRACE 輸出 */ SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G /* @b保存Innodb_rows_read的當前值 */ select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 計算Innodb_rows_read差值 */ select @b-@a;
這個方法是通過查看 OPTIMIZER_TRACE 的結果來確認的,你可以從 number_of_tmp_files 中看到是否使用了臨時文件。
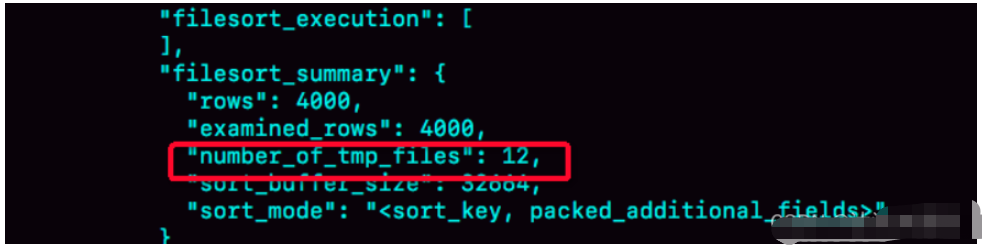
number_of_tmp_files 表示的是,排序過程中使用的臨時文件數。
為什么需要12個文件呢?
外部排序一般使用歸并排序算法。可以這么簡單理解,MySQL 將需要排序的數據分成 12 份,每一份單獨排序(快速排序)后存在這些臨時文件中。然后把這 12 個有序文件再合并成一個有序的大文件。
小結:
如果 sort_buffer_size 超過了需要排序的數據量的大小,number_of_tmp_files 就是 0,表示排序可以直接在內存中完成。sort_buffer_size 越小,需要分成的份數越多,number_of_tmp_files 的值就越大。
rowid排序
在上面這個算法過程里面,只對原表的數據讀了一遍,剩下的操作都是在 sort_buffer 和臨時文件中執行的。但這個算法有一個問題,就是如果查詢要返回的字段很多的話,那么 sort_buffer 里面要放的字段數太多,這樣內存里能夠同時放下的行數很少,要分成很多個臨時文件,排序的性能會很差。
如果當行很大,這個全字段排序并不是很好。
SET max_length_for_sort_data = 16;
這個語句的意思是:如果單行太大,超過所設定的數值的時候,比如現在是超過16,MySQL就認為單行太大,換一種算法。
city、name、age 這三個字段的定義總長度是 36,我把 max_length_for_sort_data 設置為 16。
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主鍵 id。
但這時,排序的結果就因為少了 city 和 age 字段的值,不能直接返回了(最后收集結果之前要回表),整個執行流程就變成如下所示的樣子:
初始化 sort_buffer,確定放入兩個字段,即 name 和 id;
從索引 city 找到第一個滿足 city='杭州’條件的主鍵 id,也就是圖中的 ID_X;
到主鍵 id 索引取出整行,取 name、id 這兩個字段,存入 sort_buffer 中;
從索引 city 取下一個記錄的主鍵 id;
重復步驟 3、4 直到不滿足 city='杭州’條件為止,也就是圖中的 ID_Y;
對 sort_buffer 中的數據按照字段 name 進行排序;
遍歷排序結果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三個字段返回給客戶端。
這個執行流程的示意圖如下,叫做 rowid 排序。
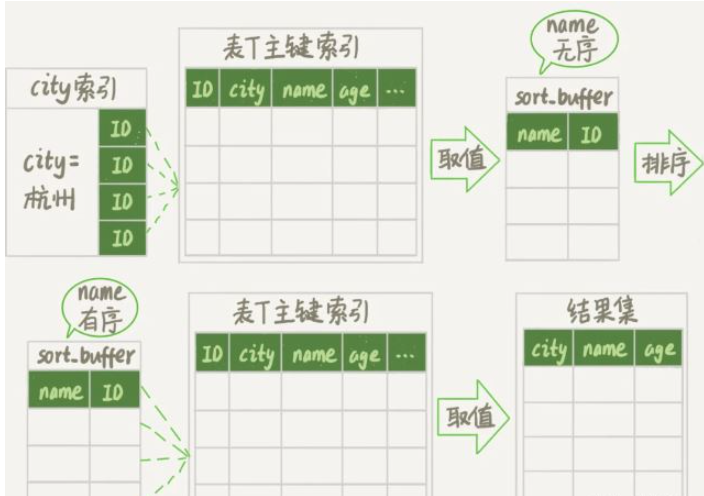
對比全字段排序流程圖發現,rowid 排序多訪問了一次表 t 的主鍵索引,就是步驟 7。
注意:最后的**“結果集”是一個邏輯概念,實際上 MySQL 服務端從排序后的 sort_buffer 中依次取出 id,然后到原表查到 city、name 和 age 這三個字段的結果,不需要在服務端再耗費內存存儲結果,是直接返回給客戶端的**。
全字段排序和rowid排序應該如何去選擇呢?
如果 MySQL 實在是擔心排序內存太小,會影響排序效率,才會采用 rowid 排序算法,這樣排序過程中一次可以排序更多行,但是需要再回到原表去取數據。
如果 MySQL 認為內存足夠大,會優先選擇全字段排序,把需要的字段都放到 sort_buffer 中,這樣排序后就會直接從內存里面返回查詢結果了,不用再回到原表去取數據。
這也就體現了 MySQL 的一個設計思想:如果內存夠,就要多利用內存,盡量減少磁盤訪問。對于 InnoDB 表來說,rowid 排序會要求回表多造成磁盤讀,因此不會被優先選擇。
其實以上說的都是無序的時候,如果在條件有索引,索引中數據是有序的,省掉了上述步驟,直接在索引上找到主鍵id,然后回表找到要查找的數據直接返回給客戶端。
讀到這里,這篇“MySQL中order by排序語句的原理是什么”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





