溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“go語言需要編譯嗎”,在日常操作中,相信很多人在go語言需要編譯嗎問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”go語言需要編譯嗎”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
go語言需要編譯。Go語言是編譯型的靜態語言,是一門需要編譯才能運行的編程語言,也就說Go語言程序在運行之前需要通過編譯器生成二進制機器碼(二進制的可執行文件),隨后二進制文件才能在目標機器上運行。
Go語言是一門需要編譯才能運行的編程語言,也就說代碼在運行之前需要通過編譯器生成二進制機器碼,隨后二進制文件才能在目標機器上運行。
簡單來說,Go語言是編譯型的靜態語言(和C語言一樣),所以在運行Go語言程序之前,先要將其編譯成二進制的可執行文件。
如果我們想要了解Go語言的實現原理,理解它的編譯過程就是一個沒有辦法繞過的事情。下面就來看看Go語言是怎么完成編譯的。
想要深入了解Go語言的編譯過程,需要提前了解一下編譯過程中涉及的一些術語和專業知識。這些知識其實在我們的日常工作和學習中比較難用到,但是對于理解編譯的過程和原理還是非常重要的。
在計算機科學中,抽象語法樹(Abstract Syntax Tree,AST),或簡稱語法樹(Syntax tree),是源代碼語法結構的一種抽象表示。它以樹狀的形式表現編程語言的語法結構,樹上的每個節點都表示源代碼中的一種結構。
之所以說語法是“抽象”的,是因為這里的語法并不會表示出真實語法中出現的每個細節。比如,嵌套括號被隱含在樹的結構中,并沒有以節點的形式呈現。而類似于 if else 這樣的條件判斷語句,可以使用帶有兩個分支的節點來表示。
以算術表達式 1+3*(4-1)+2 為例,可以解析出的抽象語法樹如下圖所示:
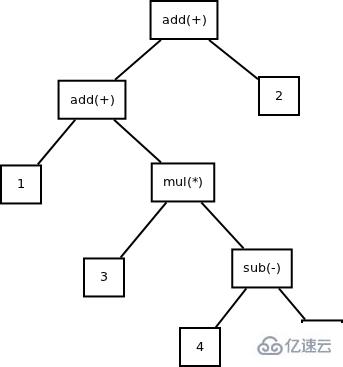
圖:抽象語法樹
抽象語法樹可以應用在很多領域,比如瀏覽器,智能編輯器,編譯器。
在編譯器設計中,靜態單賦值形式(static single assignment form,通常簡寫為 SSA form 或是 SSA)是中介碼(IR,intermediate representation)的屬性,它要求每個變量只分配一次,并且變量需要在使用之前定義。在實踐中我們通常會用添加下標的方式實現每個變量只能被賦值一次的特性,這里以下面的代碼舉一個簡單的例子:
x := 1
x := 2
y := x
從上面的描述所知,第一行賦值行為是不需要的,因為 x 在第二行被二度賦值并在第三行被使用,在 SSA 下,將會變成下列的形式:
x1 := 1
x2 := 2
y1 := x2
從使用 SSA 的中間代碼我們就可以非常清晰地看出變量 y1 的值和 x1 是完全沒有任何關系的,所以在機器碼生成時其實就可以省略第一步,這樣就能減少需要執行的指令來優化這一段代碼。
根據 Wikipedia(維基百科)對 SSA 的介紹來看,在中間代碼中使用 SSA 的特性能夠為整個程序實現以下的優化:
常數傳播(constant propagation)
值域傳播(value range propagation)
稀疏有條件的常數傳播(sparse conditional constant propagation)
消除無用的程式碼(dead code elimination)
全域數值編號(global value numbering)
消除部分的冗余(partial redundancy elimination)
強度折減(strength reduction)
寄存器分配(register allocation)
因為 SSA 的作用的主要作用就是代碼的優化,所以是編譯器后端(主要負責目標代碼的優化和生成)的一部分。當然,除了 SSA 之外代碼編譯領域還有非常多的中間代碼優化方法,優化編譯器生成的代碼是一個非常古老并且復雜的領域,這里就不展開介紹了。
最后要介紹的一個預備知識就是指令集架構了,指令集架構(Instruction Set Architecture,簡稱 ISA),又稱指令集或指令集體系,是計算機體系結構中與程序設計有關的部分,包含了基本數據類型,指令集,寄存器,尋址模式,存儲體系,中斷,異常處理以及外部 I/O。指令集架構包含一系列的 opcode 即操作碼(機器語言),以及由特定處理器執行的基本命令。
指令集架構常見種類如下:
復雜指令集運算(Complex Instruction Set Computing,簡稱 CISC);
精簡指令集運算(Reduced Instruction Set Computing,簡稱 RISC);
顯式并行指令集運算(Explicitly Parallel Instruction Computing,簡稱 EPIC);
超長指令字指令集運算(VLIW)。
不同的處理器(CPU)使用了大不相同的機器語言,所以我們的程序想要在不同的機器上運行,就需要將源代碼根據架構編譯成不同的機器語言。
Go語言編譯器的源代碼在 cmd/compile 目錄中,目錄下的文件共同構成了Go語言的編譯器,學過編譯原理的人可能聽說過編譯器的前端和后端,編譯器的前端一般承擔著詞法分析、語法分析、類型檢查和中間代碼生成幾部分工作,而編譯器后端主要負責目標代碼的生成和優化,也就是將中間代碼翻譯成目標機器能夠運行的機器碼。

Go的編譯器在邏輯上可以被分成四個階段:詞法與語法分析、類型檢查和 AST 轉換、通用 SSA 生成和最后的機器代碼生成,下面我們來分別介紹一下這四個階段做的工作。
所有的編譯過程其實都是從解析代碼的源文件開始的,詞法分析的作用就是解析源代碼文件,它將文件中的字符串序列轉換成 Token 序列,方便后面的處理和解析,我們一般會把執行詞法分析的程序稱為詞法解析器(lexer)。
而語法分析的輸入就是詞法分析器輸出的 Token 序列,這些序列會按照順序被語法分析器進行解析,語法的解析過程就是將詞法分析生成的 Token 按照語言定義好的文法(Grammar)自下而上或者自上而下的進行規約,每一個 Go 的源代碼文件最終會被歸納成一個 SourceFile 結構:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" }
標準的 Golang 語法解析器使用的就是 LALR(1) 的文法,語法解析的結果其實就是上面介紹過的抽象語法樹(AST),每一個 AST 都對應著一個單獨的Go語言文件,這個抽象語法樹中包括當前文件屬于的包名、定義的常量、結構體和函數等。
如果在語法解析的過程中發生了任何語法錯誤,都會被語法解析器發現并將消息打印到標準輸出上,整個編譯過程也會隨著錯誤的出現而被中止。
當拿到一組文件的抽象語法樹 AST 之后,Go語言的編譯器會對語法樹中定義和使用的類型進行檢查,類型檢查分別會按照順序對不同類型的節點進行驗證,按照以下的順序進行處理:
常量、類型和函數名及類型;
變量的賦值和初始化;
函數和閉包的主體;
哈希鍵值對的類型;
導入函數體;
外部的聲明;
通過對每一棵抽象節點樹的遍歷,我們在每一個節點上都會對當前子樹的類型進行驗證保證當前節點上不會出現類型錯誤的問題,所有的類型錯誤和不匹配都會在這一個階段被發現和暴露出來。
類型檢查的階段不止會對樹狀結構的節點進行驗證,同時也會對一些內建的函數進行展開和改寫,例如 make 關鍵字在這個階段會根據子樹的結構被替換成 makeslice 或者 makechan 等函數。
其實類型檢查不止對類型進行了驗證工作,還對 AST 進行了改寫以及處理Go語言內置的關鍵字,所以,這一過程在整個編譯流程中是非常重要的,沒有這個步驟很多關鍵字其實就沒有辦法工作。【相關推薦:Go視頻教程】
當我們將源文件轉換成了抽象語法樹,對整個語法樹的語法進行解析并進行類型檢查之后,就可以認為當前文件中的代碼基本上不存在無法編譯或者語法錯誤的問題了,Go語言的編譯器就會將輸入的 AST 轉換成中間代碼。
Go語言編譯器的中間代碼使用了 SSA(Static Single Assignment Form) 的特性,如果我們在中間代碼生成的過程中使用這種特性,就能夠比較容易的分析出代碼中的無用變量和片段并對代碼進行優化。
在類型檢查之后,就會通過一個名為 compileFunctions 的函數開始對整個Go語言項目中的全部函數進行編譯,這些函數會在一個編譯隊列中等待幾個后端工作協程的消費,這些 Goroutine 會將所有函數對應的 AST 轉換成使用 SSA 特性的中間代碼。
Go語言源代碼的 cmd/compile/internal 目錄中包含了非常多機器碼生成相關的包,不同類型的 CPU 分別使用了不同的包進行生成 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm,也就是說Go語言能夠在幾乎全部常見的 CPU 指令集類型上運行。
Go語言的編譯器入口是 src/cmd/compile/internal/gc 包中的 main.go 文件,這個 600 多行的 Main 函數就是Go語言編譯器的主程序,這個函數會先獲取命令行傳入的參數并更新編譯的選項和配置,隨后就會開始運行 parseFiles 函數對輸入的所有文件進行詞法與語法分析得到文件對應的抽象語法樹:
func Main(archInit func(*Arch)) {
// ...
lines := parseFiles(flag.Args())
接下來就會分九個階段對抽象語法樹進行更新和編譯,就像我們在上面介紹的,整個過程會經歷類型檢查、SSA 中間代碼生成以及機器碼生成三個部分:
檢查常量、類型和函數的類型;
處理變量的賦值;
對函數的主體進行類型檢查;
決定如何捕獲變量;
檢查內聯函數的類型;
進行逃逸分析;
將閉包的主體轉換成引用的捕獲變量;
編譯頂層函數;
檢查外部依賴的聲明;
了解了剩下的編譯過程之后,我們重新回到詞法和語法分析后的具體流程,在這里編譯器會對生成語法樹中的節點執行類型檢查,除了常量、類型和函數這些頂層聲明之外,它還會對變量的賦值語句、函數主體等結構進行檢查:
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCLFUNC || op == OCLOSURE {
typecheckslice(Curfn.Nbody.Slice(), ctxStmt)
}
}
checkMapKeys()
for _, n := range xtop {
if n.Op == ODCLFUNC && n.Func.Closure != nil {
capturevars(n)
}
}
escapes(xtop)
for _, n := range xtop {
if n.Op == ODCLFUNC && n.Func.Closure != nil {
transformclosure(n)
}
}
類型檢查會對傳入節點的子節點進行遍歷,這個過程會對 make 等關鍵字進行展開和重寫,類型檢查結束之后并沒有輸出新的數據結構,只是改變了語法樹中的一些節點,同時這個過程的結束也意味著源代碼中已經不存在語法錯誤和類型錯誤,中間代碼和機器碼也都可以正常的生成了。
initssaconfig()
peekitabs()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
for i, n := range externdcl {
if n.Op == ONAME {
externdcl[i] = typecheck(externdcl[i], ctxExpr)
}
}
checkMapKeys()
}
在主程序運行的最后,會將頂層的函數編譯成中間代碼并根據目標的 CPU 架構生成機器碼,不過這里其實也可能會再次對外部依賴進行類型檢查以驗證正確性。
到此,關于“go語言需要編譯嗎”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





