溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“SQL基本語句有哪些及怎么使用”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“SQL基本語句有哪些及怎么使用”吧!
數據定義語言,用來定義數據庫對象(數據庫,表,字段)
查詢
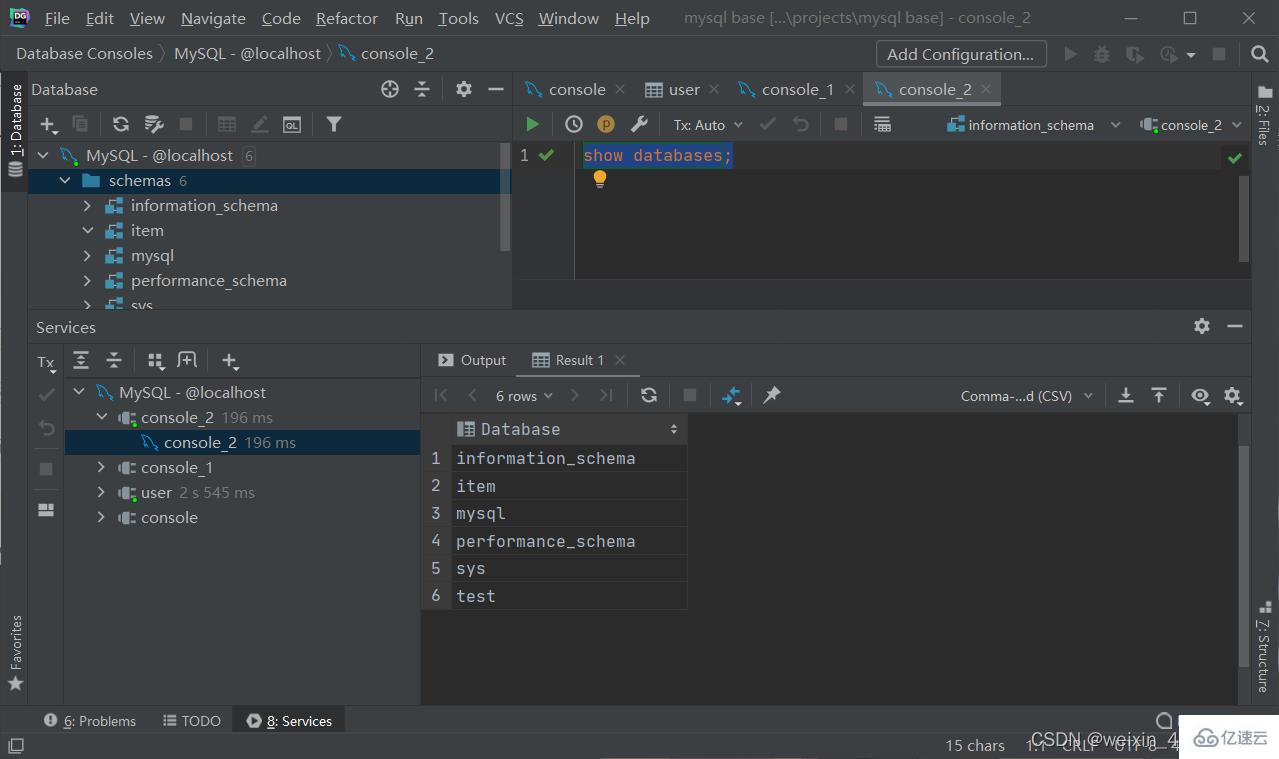
查詢所有數據庫
show databases;
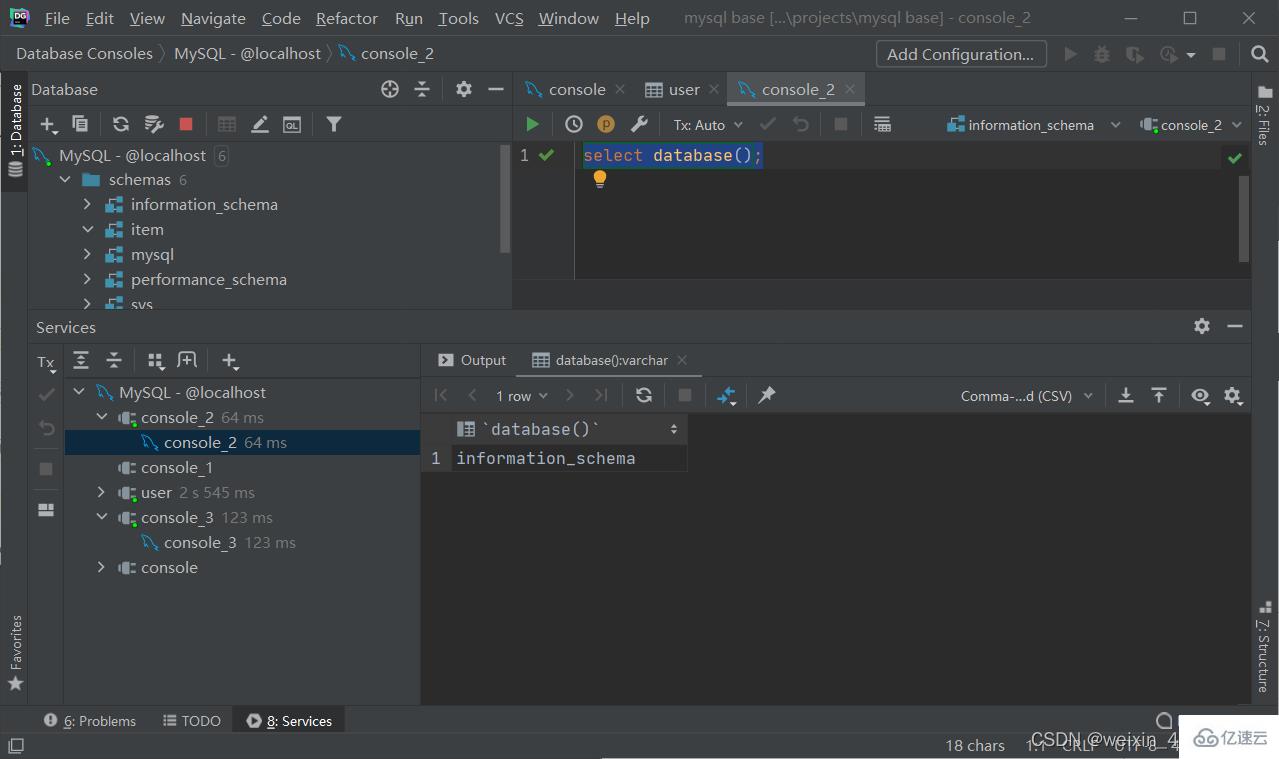
查詢當前數據庫
select database();
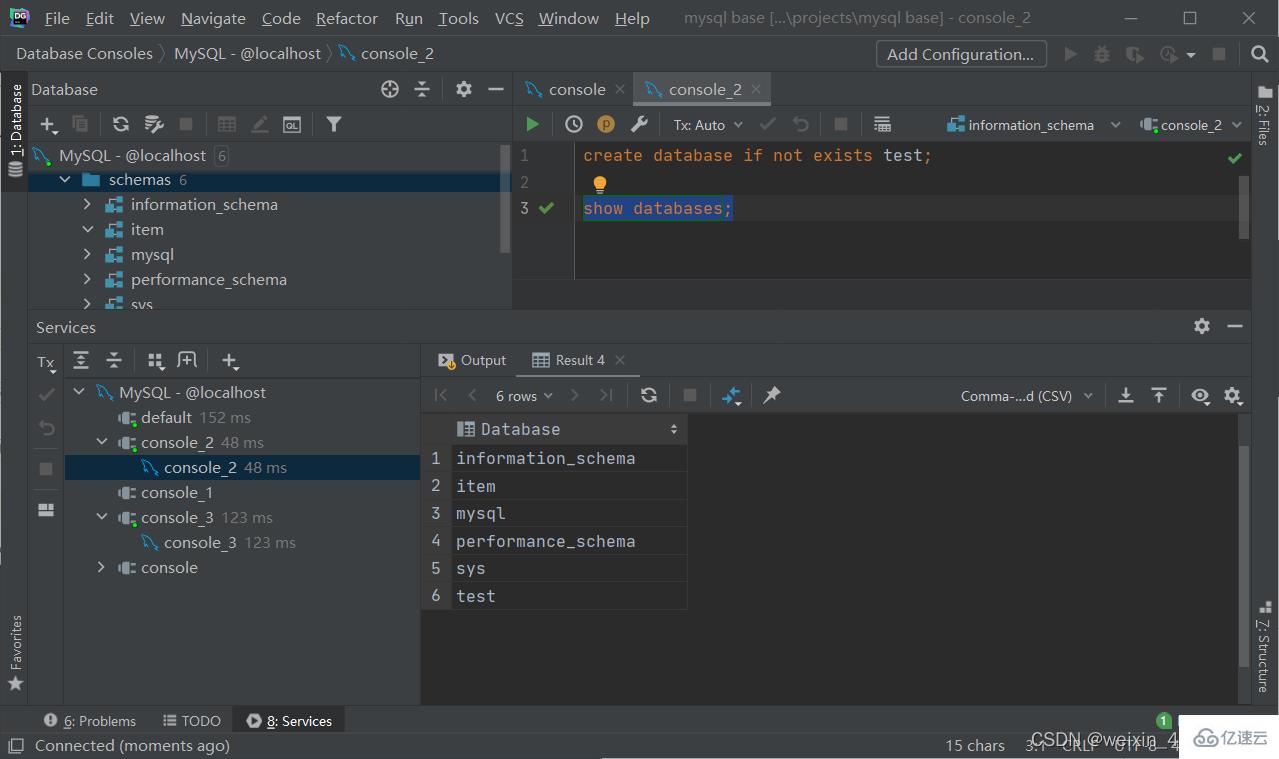
創建
create database [if not exists] 數據庫名 [default charset 字符集][collate 排序規則];
#中括號里的可加可不加,具體情況而定
#第一個是如果不存在相同名稱的數據庫則創建
#第二個是設置字符的字符集和排序規則
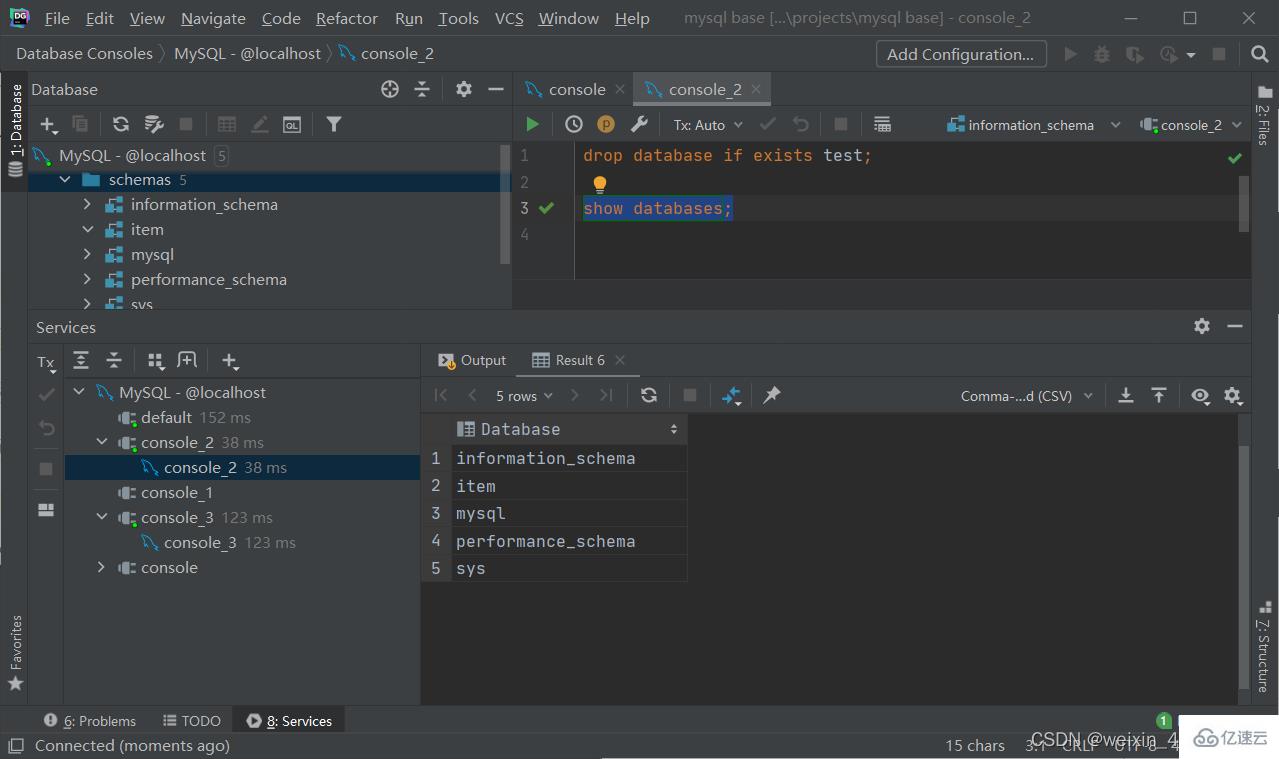
刪除
drop database [if exists] 數據庫名;
#中括號是如果存在相同名稱的數據庫就刪除
使用
use 數據庫名;
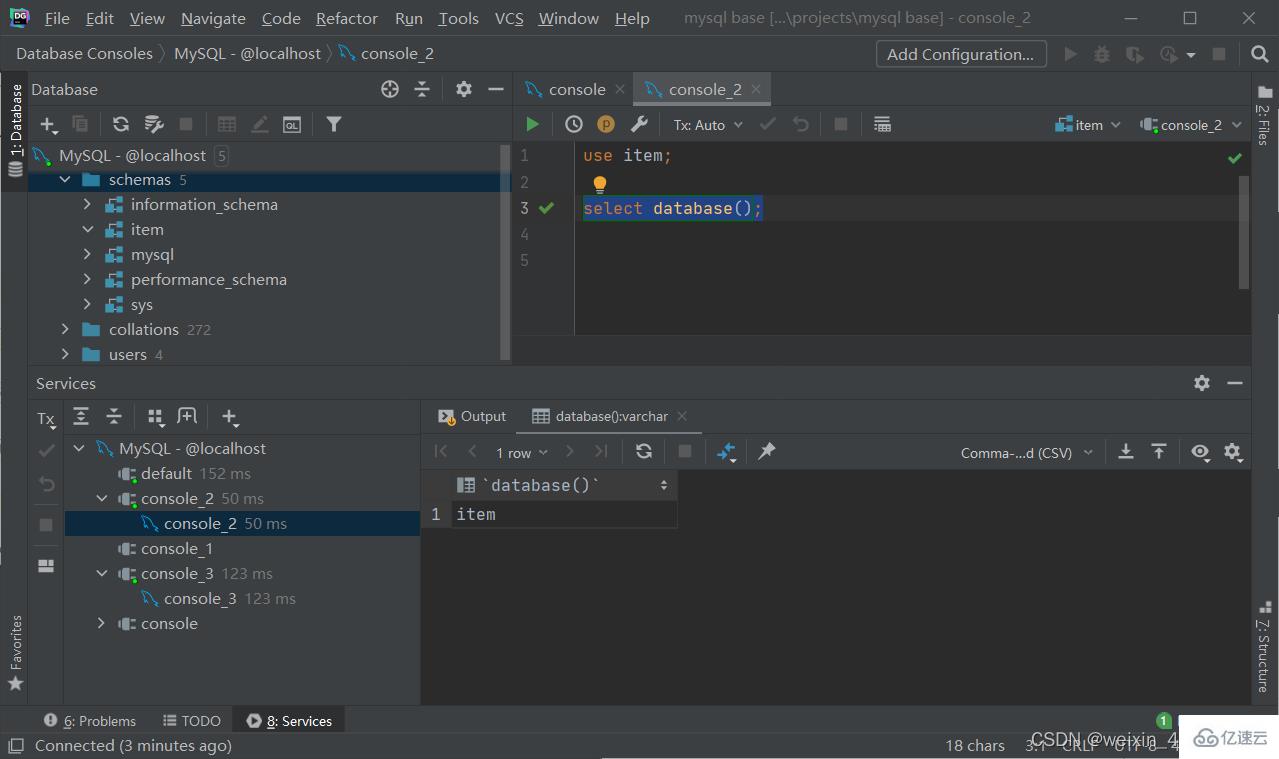
表操作-創建
create table 表名 (
字段1 字段1類型[comment 字段1注釋],
字段2 字段2類型[comment 字段2注釋],
字段3 字段3類型[comment 字段3注釋],
......
字段n 字段n類型[comment 字段n注釋]
)[comment 表注釋];
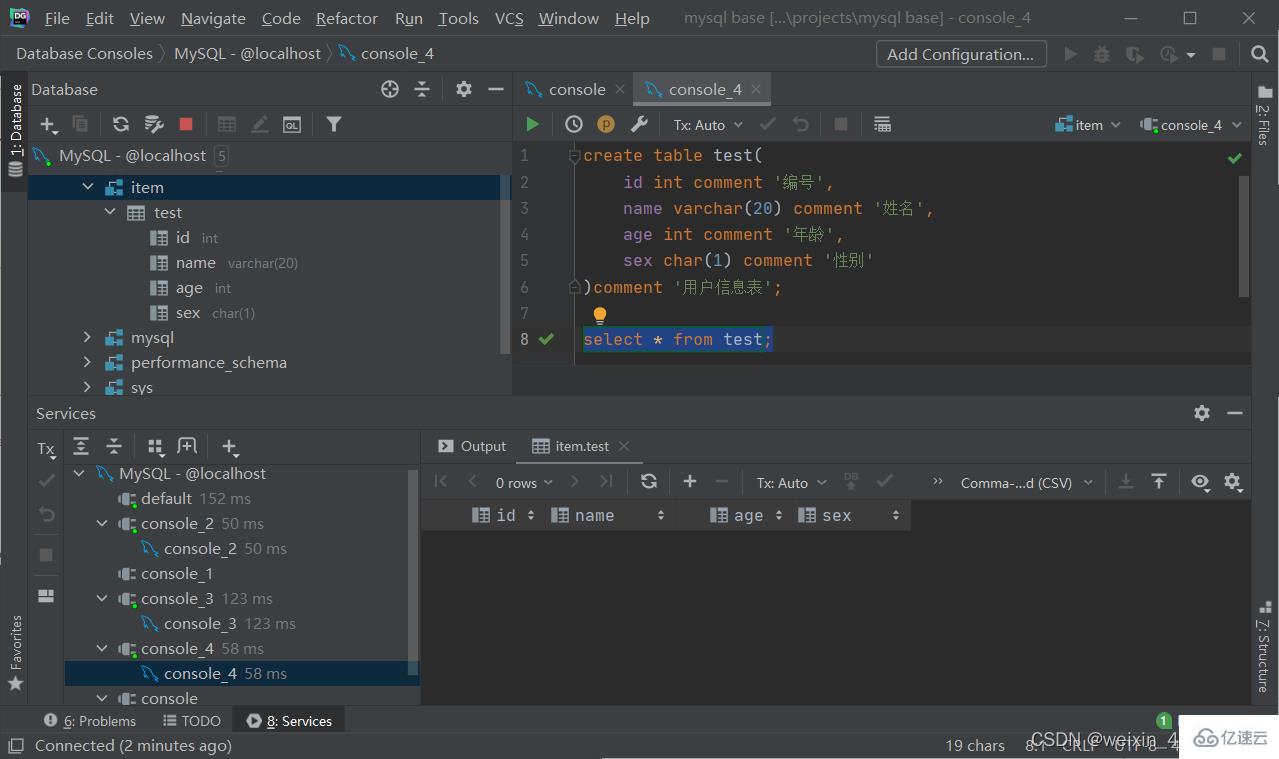
注:[....]為可選參數,最后一個字段后面沒有逗號
表操作-修改
添加字段
alter table 表名 add 字段名 類型(長度) [comment 注釋][約束];
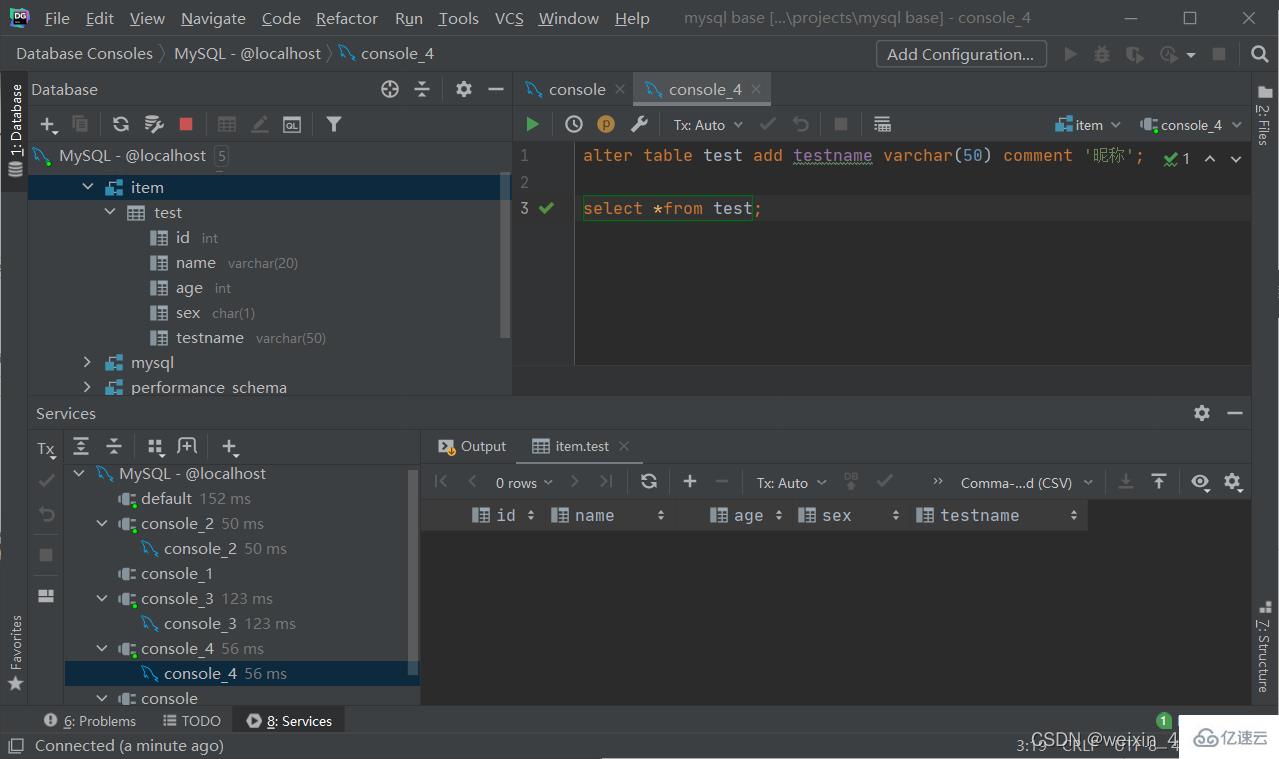
修改數據類型
alter table 表名 modify 字段名 新數據類型(長度);
修改字段名和字段類型
alter table 表名 change 舊字段名 新字段名 類型(長度)[comment 注釋][約束];
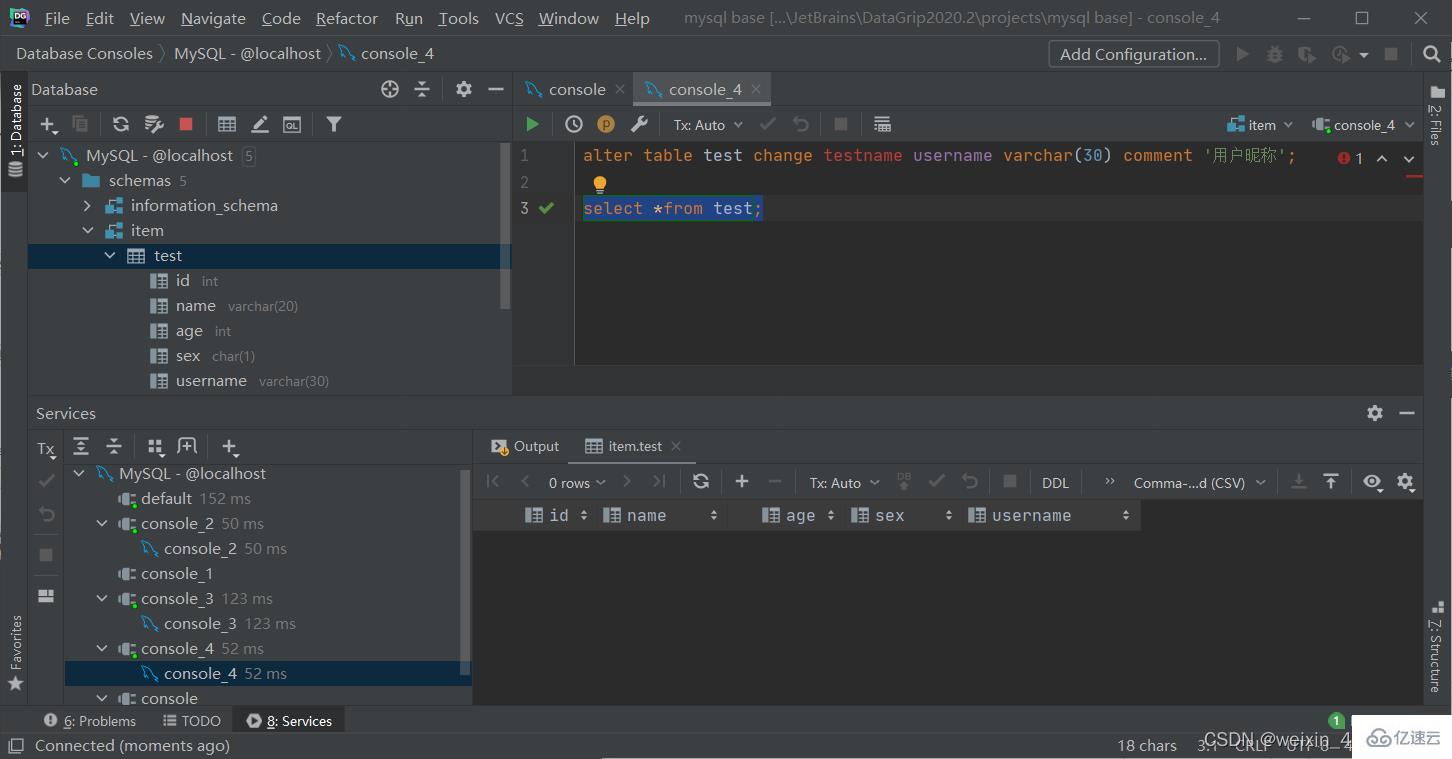
刪除字段
alter table 表名 drop 字段名;
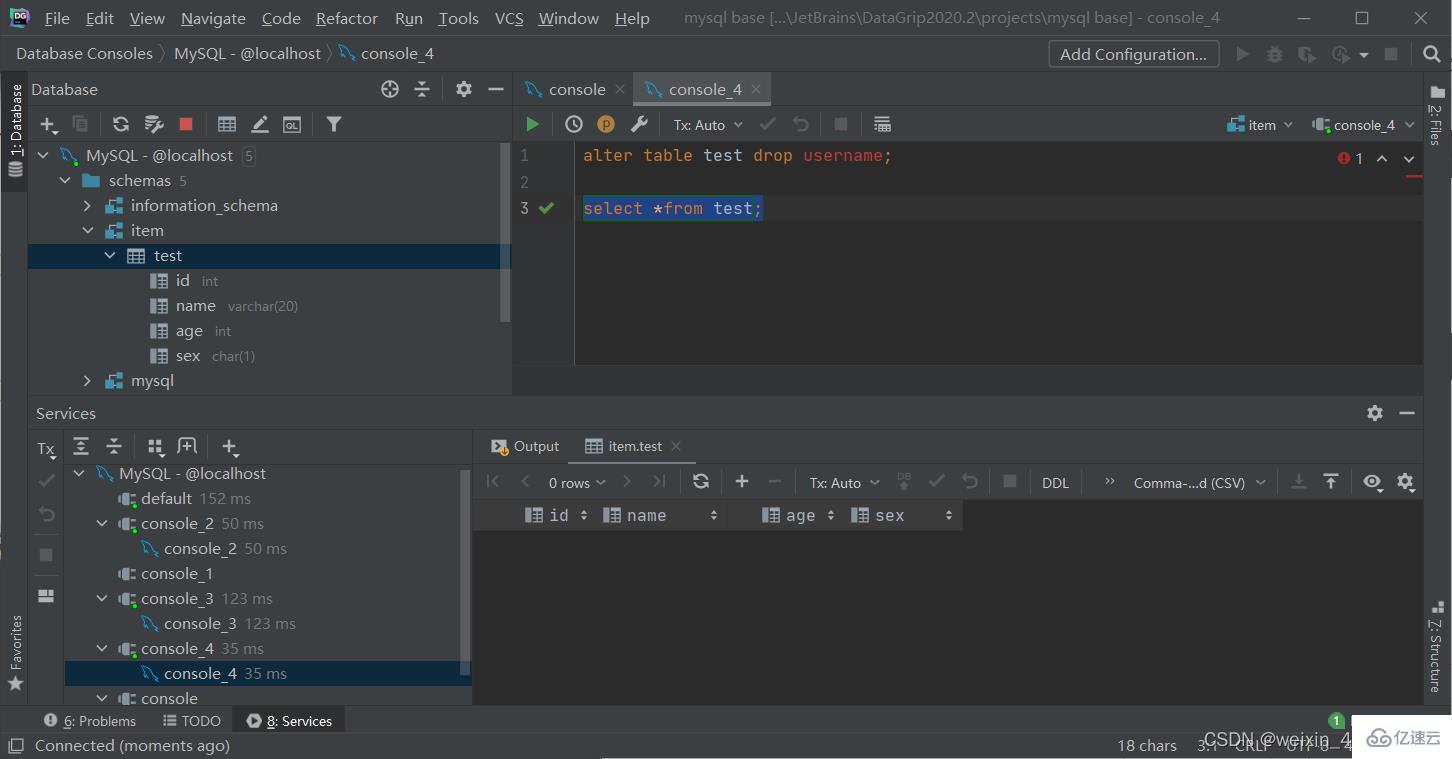
修改表名
alter table 表名 rename to 新表名;
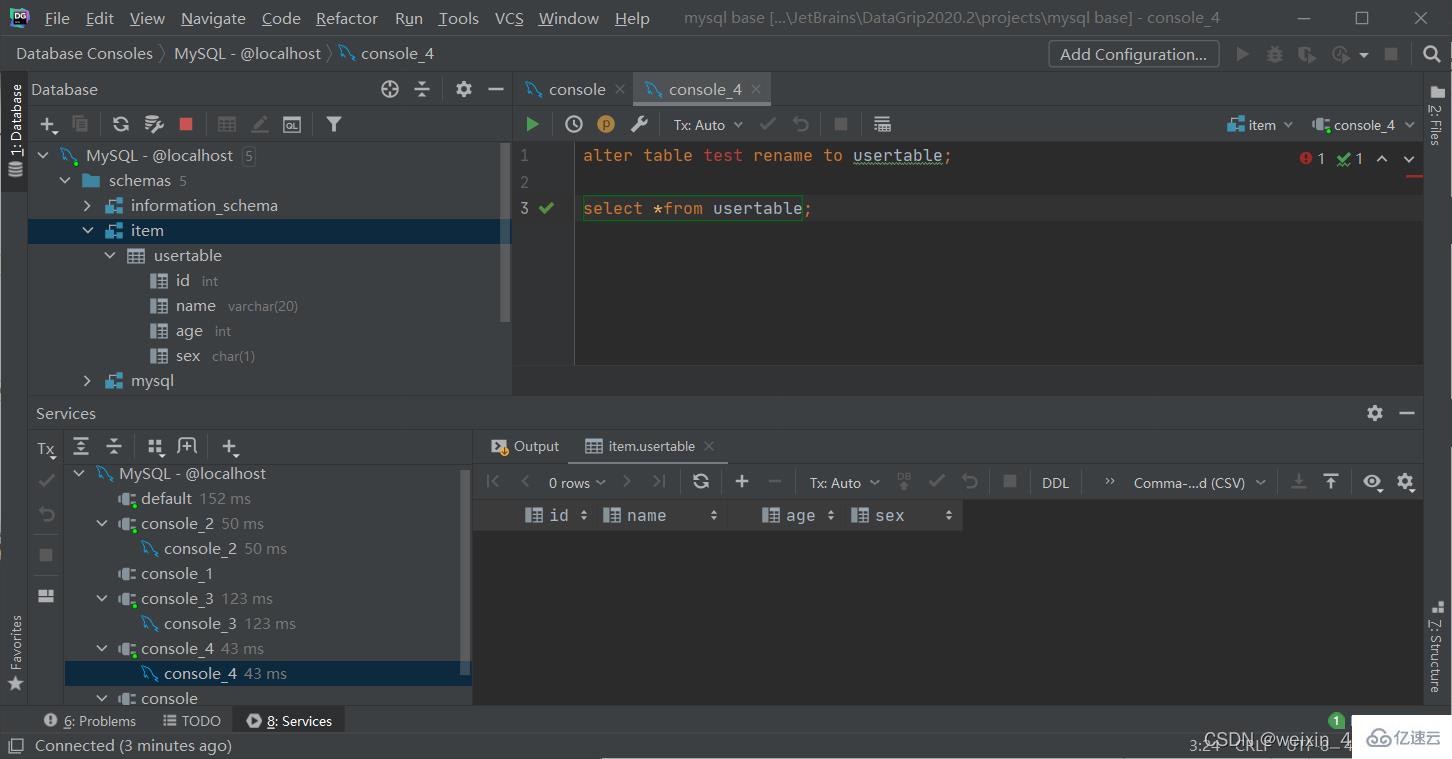
表操作-刪除
刪除表(讓指定表從數據庫消失)
drop table [if exists] 表名;
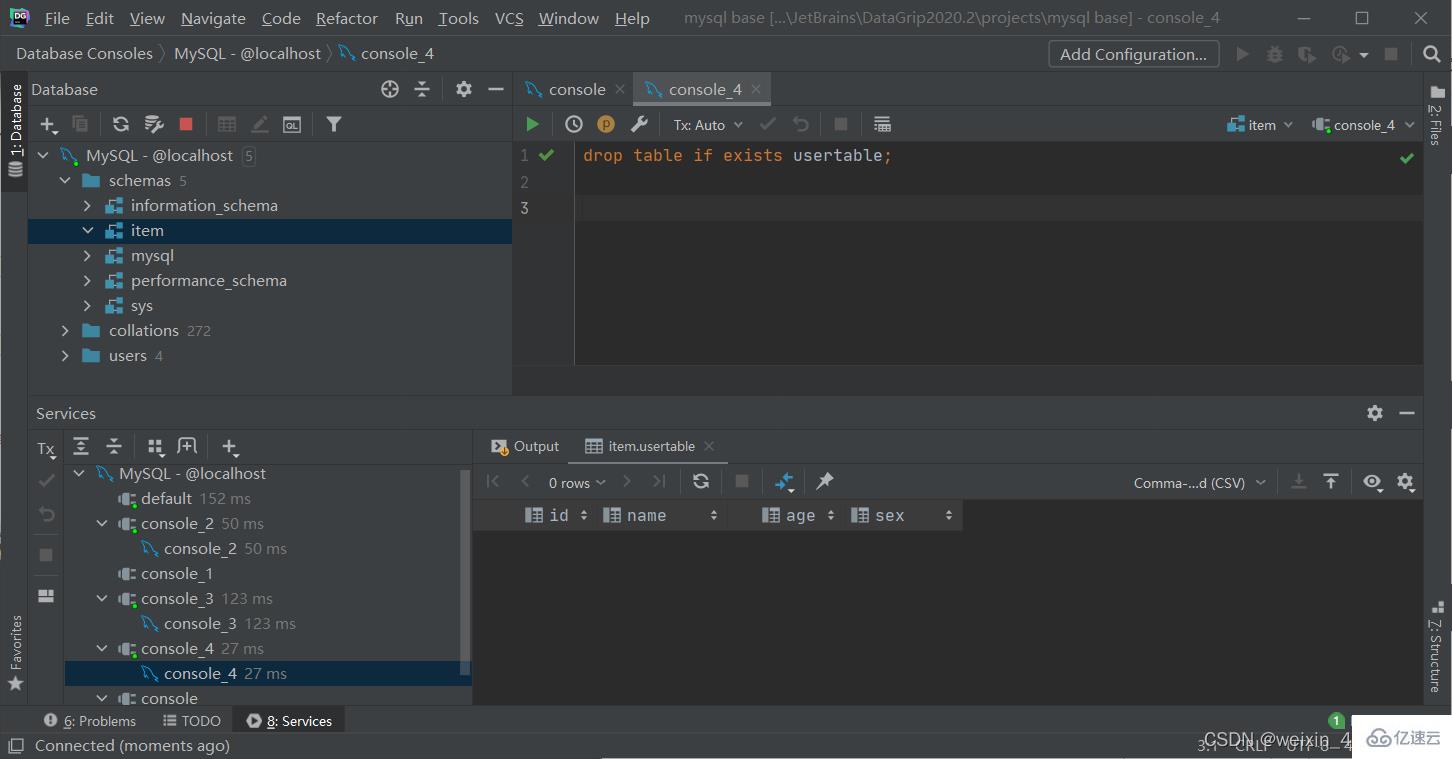
刪除指定表,并重新創建該表(俗稱格式化)
truncate table 表名;
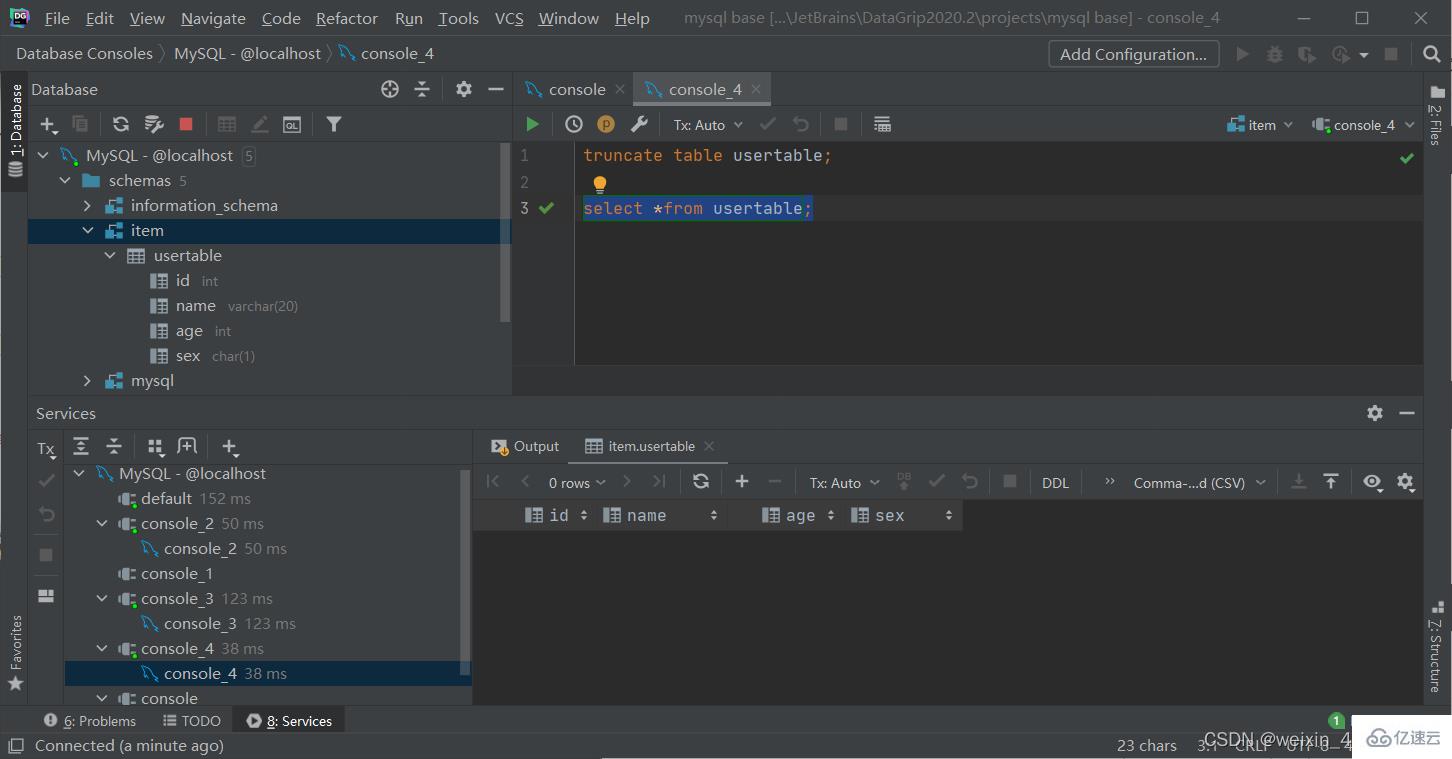
數據操作語言,用來對數據庫表中的數據進行增刪改
輔助用建表格式
create table worktable(
id int comment '編號',
worknum int comment '工號',
name varchar(20) comment '姓名',
sex char(1) comment '性別',
age int comment '年齡',
idcard int comment '身份證號',
entrydate date comment '入職日期'
)comment '員工信息表';
添加數據
給指定字段添加數據
insert into 表名(字段名1,字段名2,.....) values(值1,值2,......);
給全部字段添加數據
insert into 表名 values (值1,值2,.....);
批量添加數據
insert into 表名(字段名1,字段名2,.....)
values(值1,值2,......),(值1,值2,......),(值1,值2,......);
insert into 表名
values (值1,值2,.....),(值1,值2,......),(值1,值2,......);
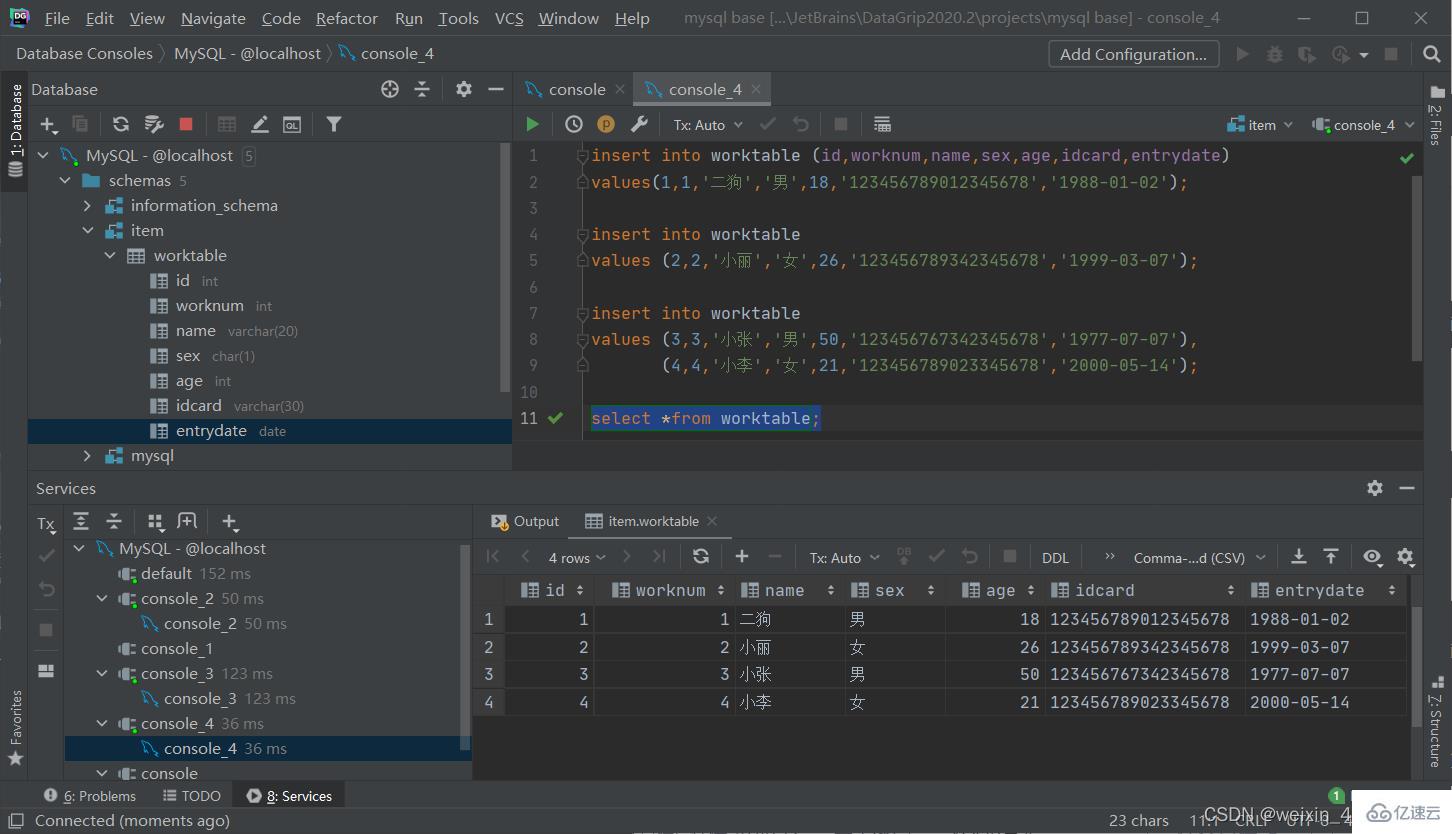
[注]:
· 插入數據時,指定的字段順序需要與值的順序是一一對應的
·字符串和日期型數據應該包含在引號中
·插入的數據大小,應該在字段的規定范圍內
修改數據
update 表名 set 字段名1=值1,字段名2=值2,....[where 條件];
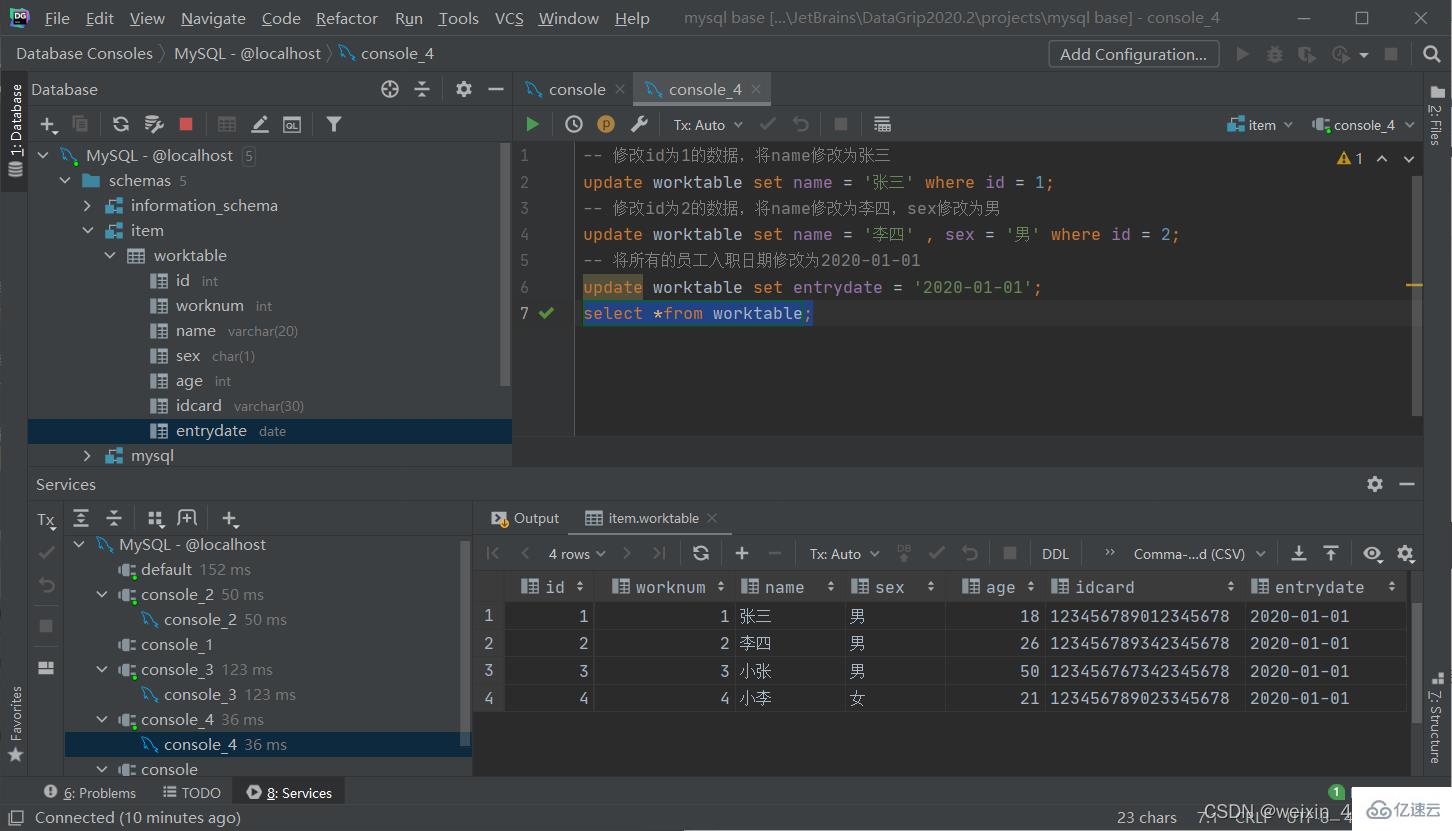
[注]:修改語句的條件可以有,也可以沒有,如果沒有條件,則會修改整張表的所有數據
刪除數據
delete from 表名 [where 條件];
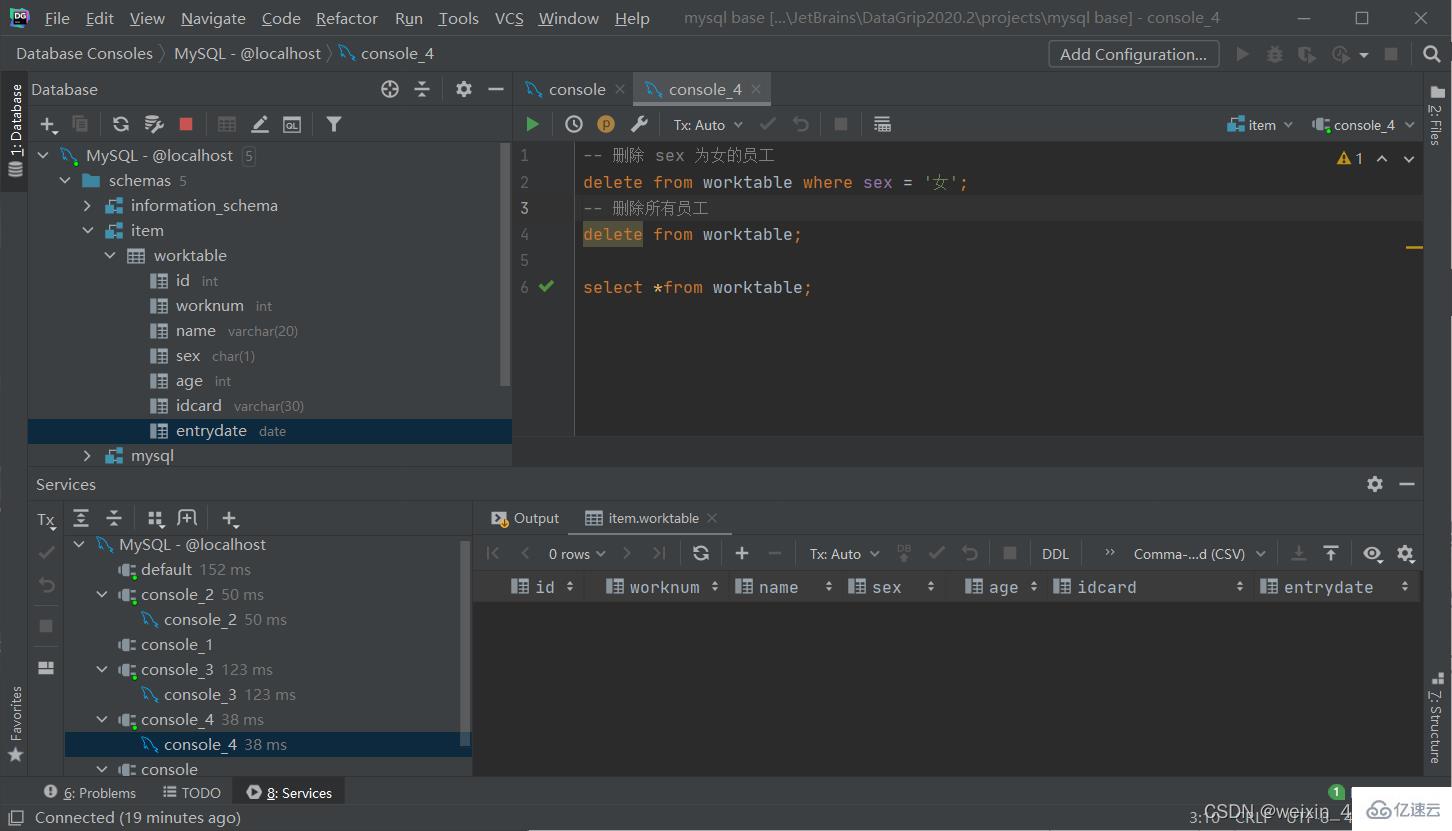
[注]:
·delete語句的條件可以有,也可以沒有,如果沒有條件,則會刪除整張表的所有數據
·delete語句不能刪除某一個字段的值(可以使用update)
數據查詢語言,用來查詢數據庫中表的記錄
整體語法概覽
| select | 字段列表 |
| from | 表名列表 |
| where | 條件列表 |
| group by | 分組字段列表 |
| having | 分組后條件列表 |
| order by | 排序字段列表 |
| limit | 分頁參數 |
基本查詢
條件查詢(where)
聚合函數(count,max,min,avg,sum)
分組查詢(group by)
排序查詢(order by)
分頁查詢(limit)
輔助建表內容
create table emp(
id int comment '編號',
worknum varchar(10) comment '工號',
name varchar(10) comment '姓名',
gender char(1) comment '性別',
age tinyint unsigned comment '年齡',
idcard char(18) comment '身份證號',
workaddress varchar(50) comment '工作地址',
entrydate date comment '入職時間'
)comment '員工表';
insert into emp (id,worknum,name,gender,age,idcard,workaddress,entrydate)
values (1,'1','柳巖','女',20,'123456789012345678','北京','2000-01-01'),
(2,'2','張無忌','男',18,'123456789012345670','北京','2005-09-01'),
(3,'3','韋一笑','男',38,'123456789712345670','上海','2005-08-01'),
(4,'4','趙敏','女',18,'123456757123845670','北京','2009-12-01'),
(5,'5','小昭','女',16,'123456769012345678','上海','2007-07-01'),
(6,'6','楊逍','男',28,'12345678931234567X','北京','2006-01-01'),
(7,'7','范瑤','男',40,'123456789212345670','北京','2005-05-01'),
(8,'8','黛綺絲','女',38,'123456157123645670','天津','2015-05-01'),
(9,'9','范涼涼','女',45,'123156789012345678','北京','2010-04-01'),
(10,'10','陳友諒','男',53,'123456789012345670','上海','2011-01-01'),
(11,'11','張士誠','男',55,'123567897123465670','江蘇','2015-05-01'),
(12,'12','常遇春','男',32,'123446757152345670','北京','2004-02-01'),
(13,'13','張三豐','男',88,'123656789012345678','江蘇','2020-11-01'),
(14,'14','滅絕','女',65,'123456719012345670','西安','2019-05-01'),
(15,'15','胡青牛','男',70,'12345674971234567X','西安','2018-04-01'),
(16,'16','周芷若','女',18,null,'北京','2012-06-01');
基本查詢
查詢多個字段
select 字段1,字段2,字段3.....from 表名;
select *from 表名;
設置別名
select 字段1 [as 別名1],字段2 [as 別名2] .... from 表名;
#as可省略
去除重復記錄
select distinct 字段列表 from 表名;

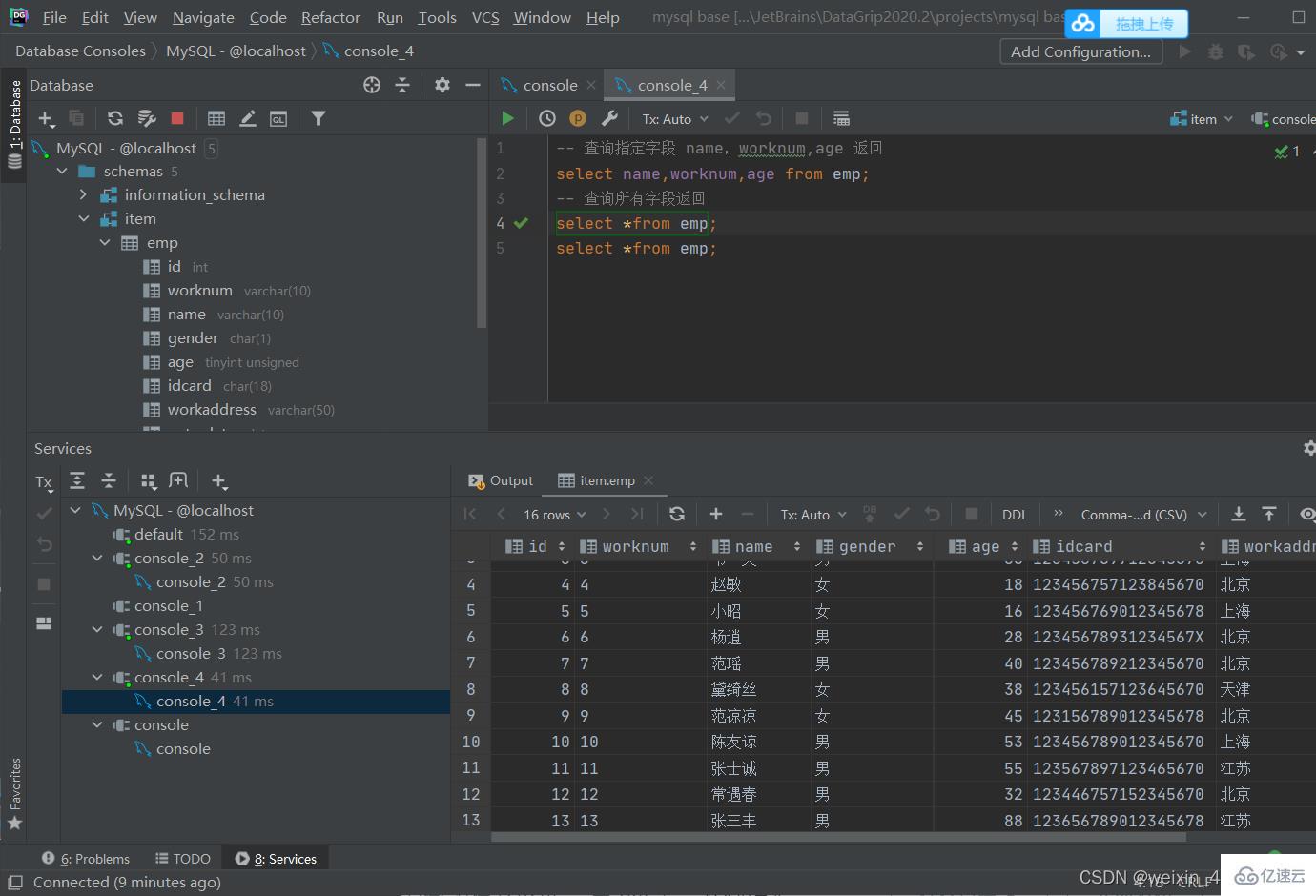
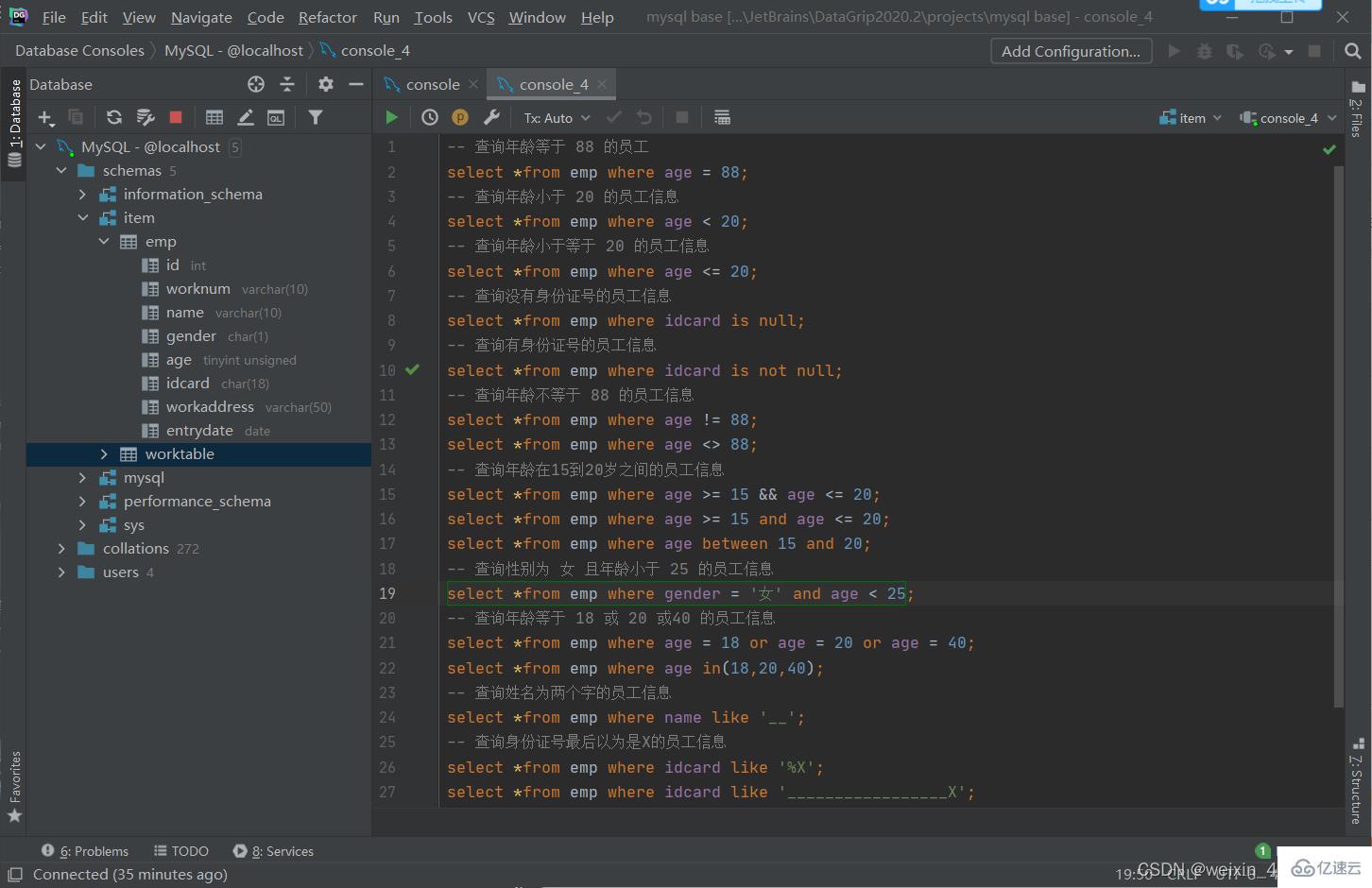
條件查詢
語法
登錄后復制select 字段列表 from 表名 where 條件列表;
條件
| 比較運算符 | 功能 | 邏輯運算符 | 功能 |
| > | 大于 | and 或 && | 并且(多個條件同時成立) |
| >= | 大于等于 | or 或 || | 或者(多個條件任意一個成立) |
| < | 小于 | not 或 ! | 非,不是 |
| <= | 小于等于 | ||
| = | 等于 | ||
| <> 或 != | 不等于 | ||
| between...and... | 在某個范圍內(含最小,最大值) | ||
| in(.....) | 在in之后的列表中的值,多選一 | ||
| like 占位符 | 模糊匹配(_匹配單個字符,%匹配任意個字符) | ||
| is null | 是null |
聚散函數
常見聚合函數
| 函數 | 功能 |
| count | 統計數量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
語法
select 聚合函數(字段列表) from 表名;
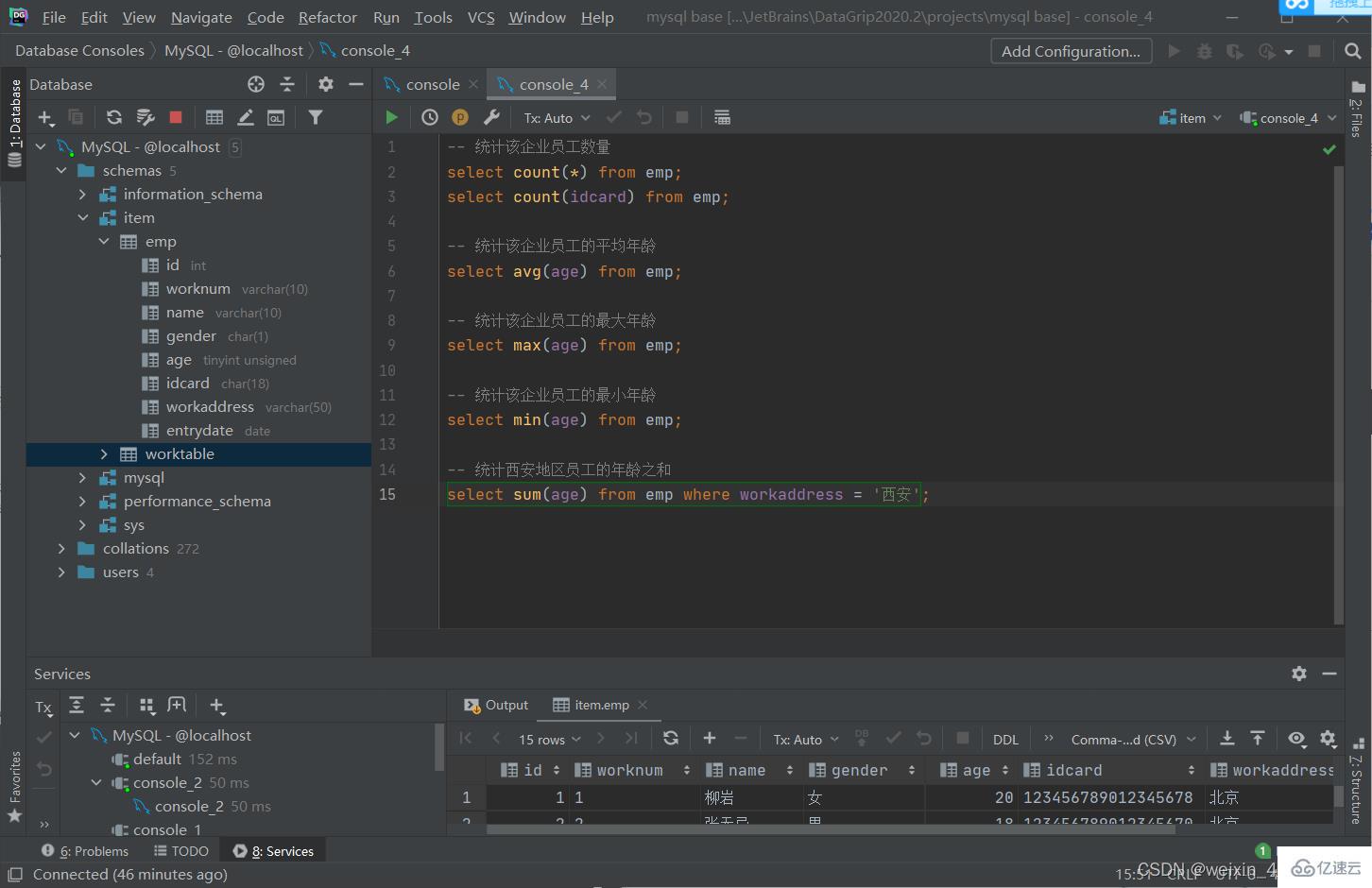
[注]:null值不參與所有聚合函數運算
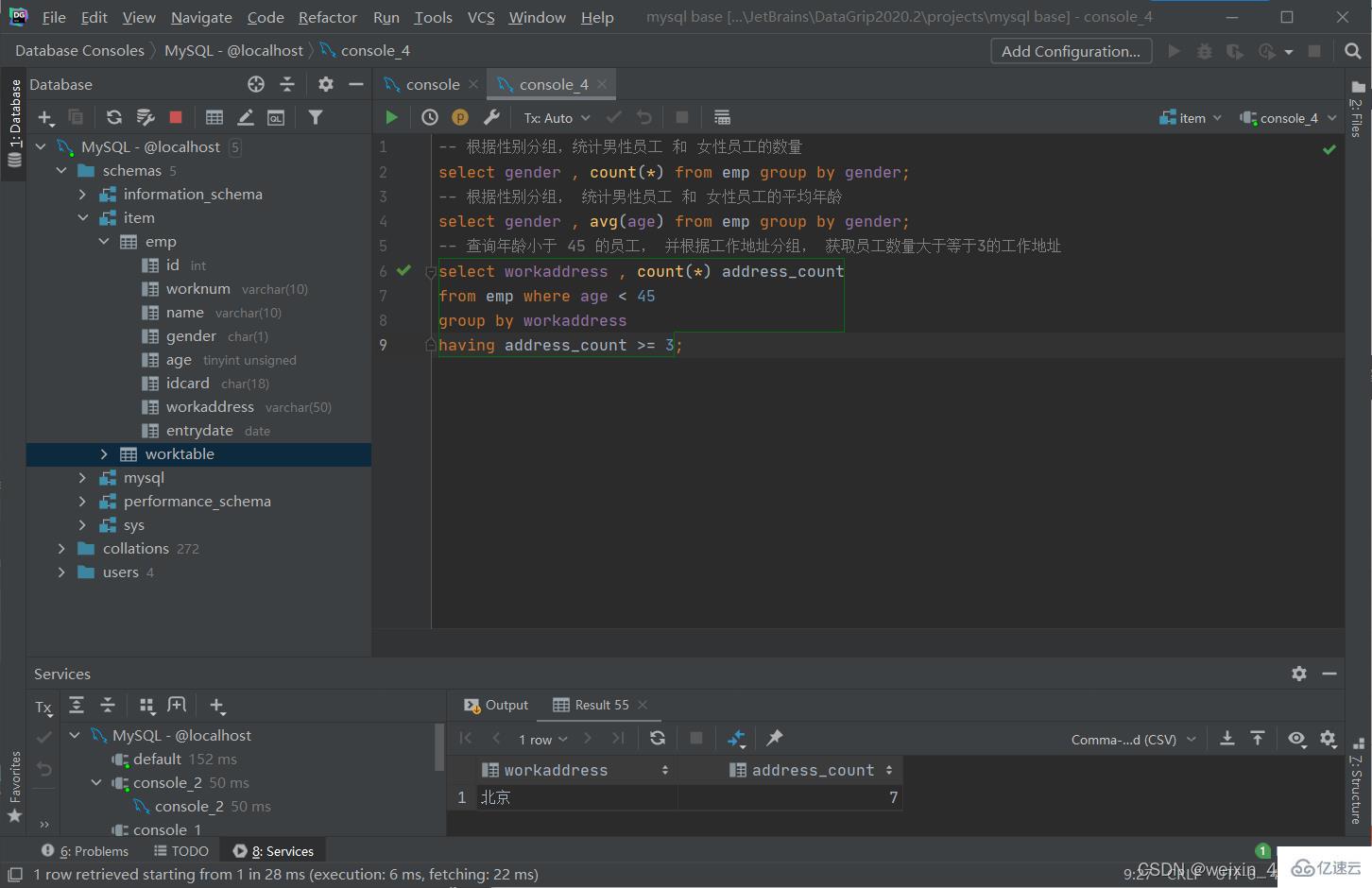
分組查詢
語法
select 字段列表 from 表名 [where 條件] group by 分組字段名 [having 分組過濾條件];
where 與 having 區別
1.執行時機不同:where是分組之前進行過濾,不滿足where條件,不參與分組;
having是分組之后對結果進行過濾。
2.判斷條件不同:where不能對聚合函數進行判斷,而having可以。
排序查詢
語法
select 字段列表 from 表名 order by 字段1 排序方式1 , 字段2 排序方式2;
#排序方式
#asc:升序(默認值)
#desc:降序
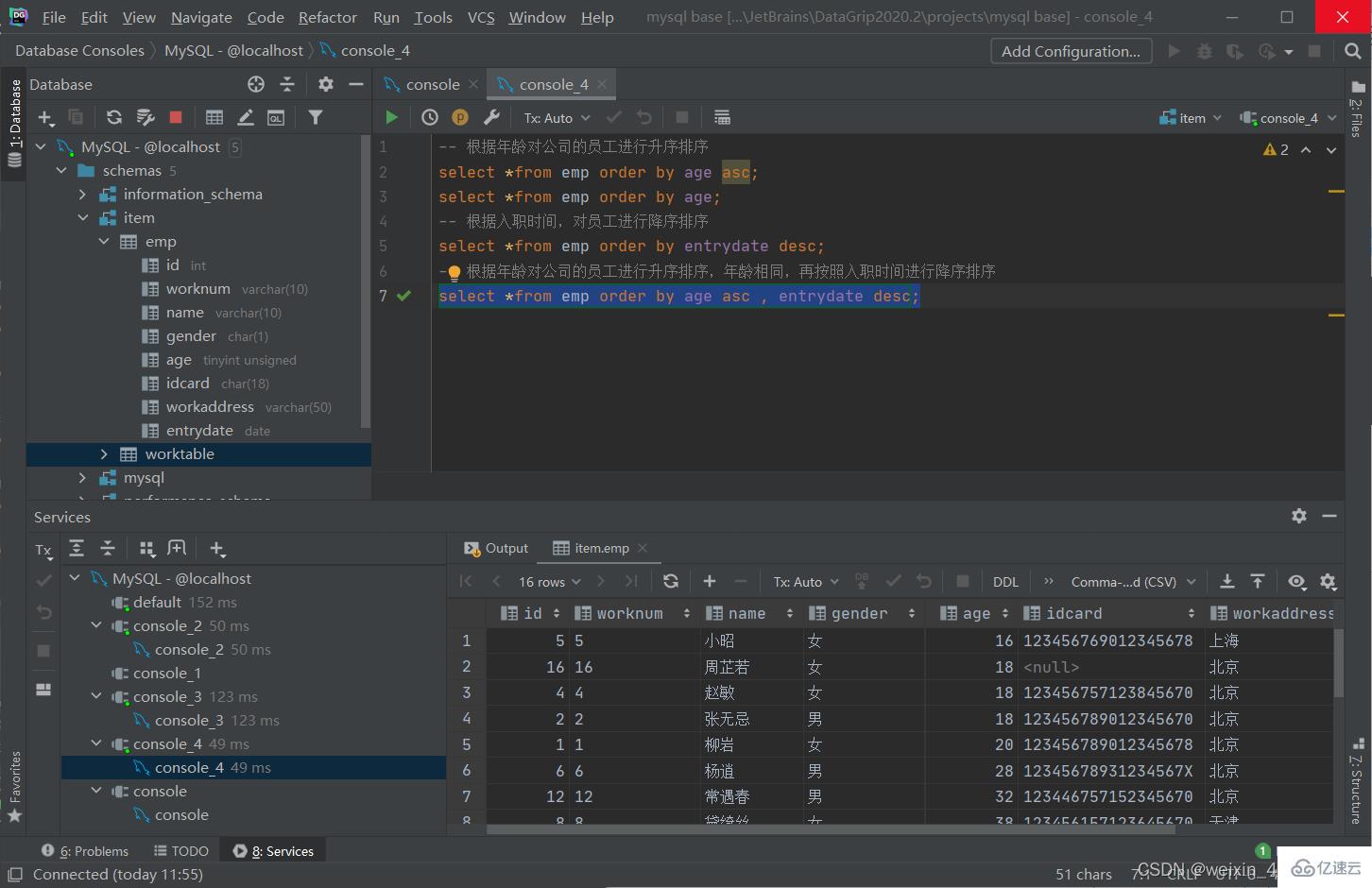
[注]:如果是多字段排序,當第一個字段值相同時,才會根據第二個字段進行排序。
分頁查詢
語法
select 字段列表 from 表名 limit 起始索引,查詢記錄數;
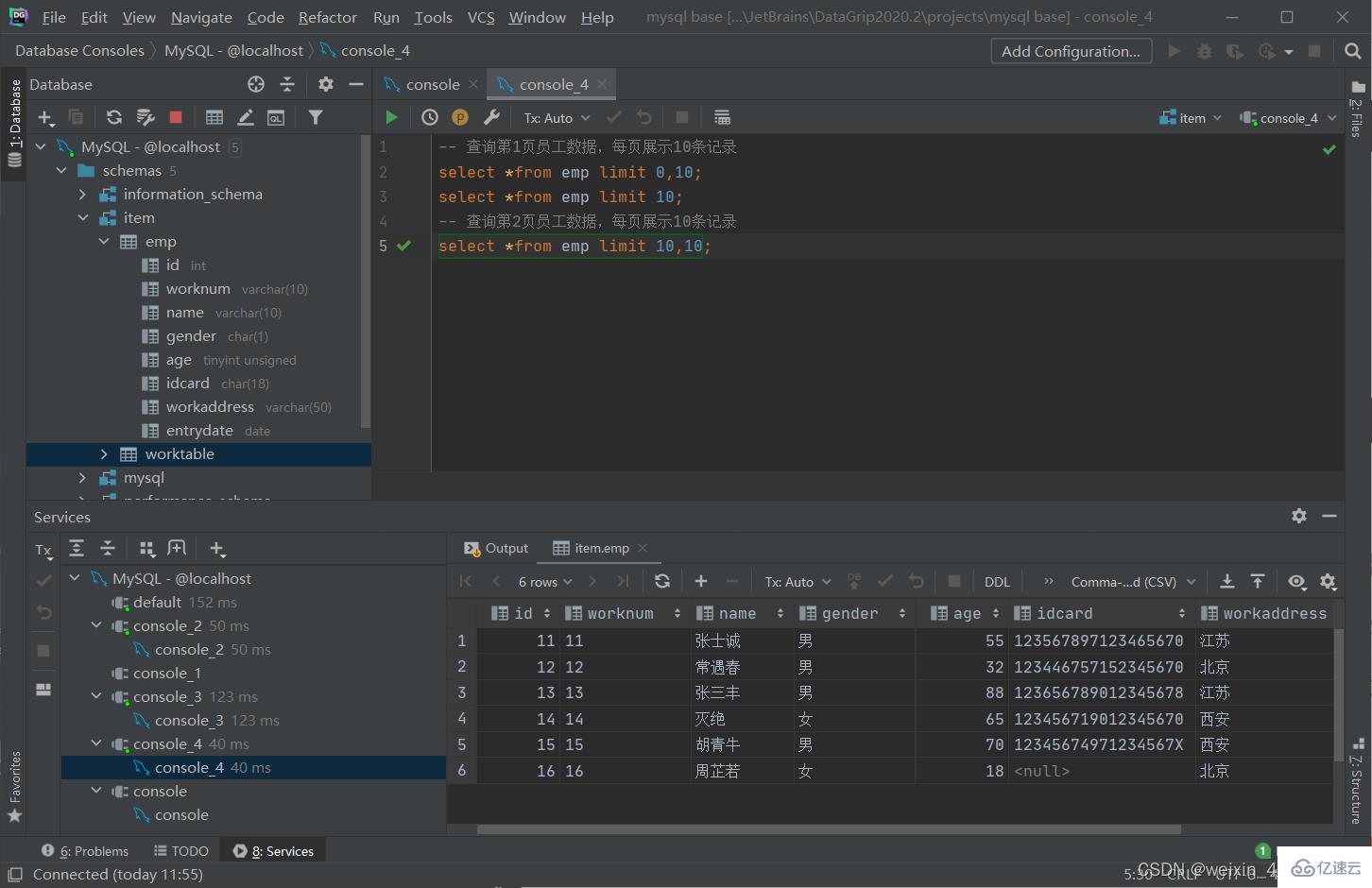
[注]:
起始索引從0開始,起始索引 = (查詢頁碼 - 1) * 每頁顯示記錄數
分頁查詢是數據庫的方言,不同的數據庫有不同的實現,MySQL中是limit
如果查詢的是第一頁數據,起始索引可以省略,直接簡寫為limit 10
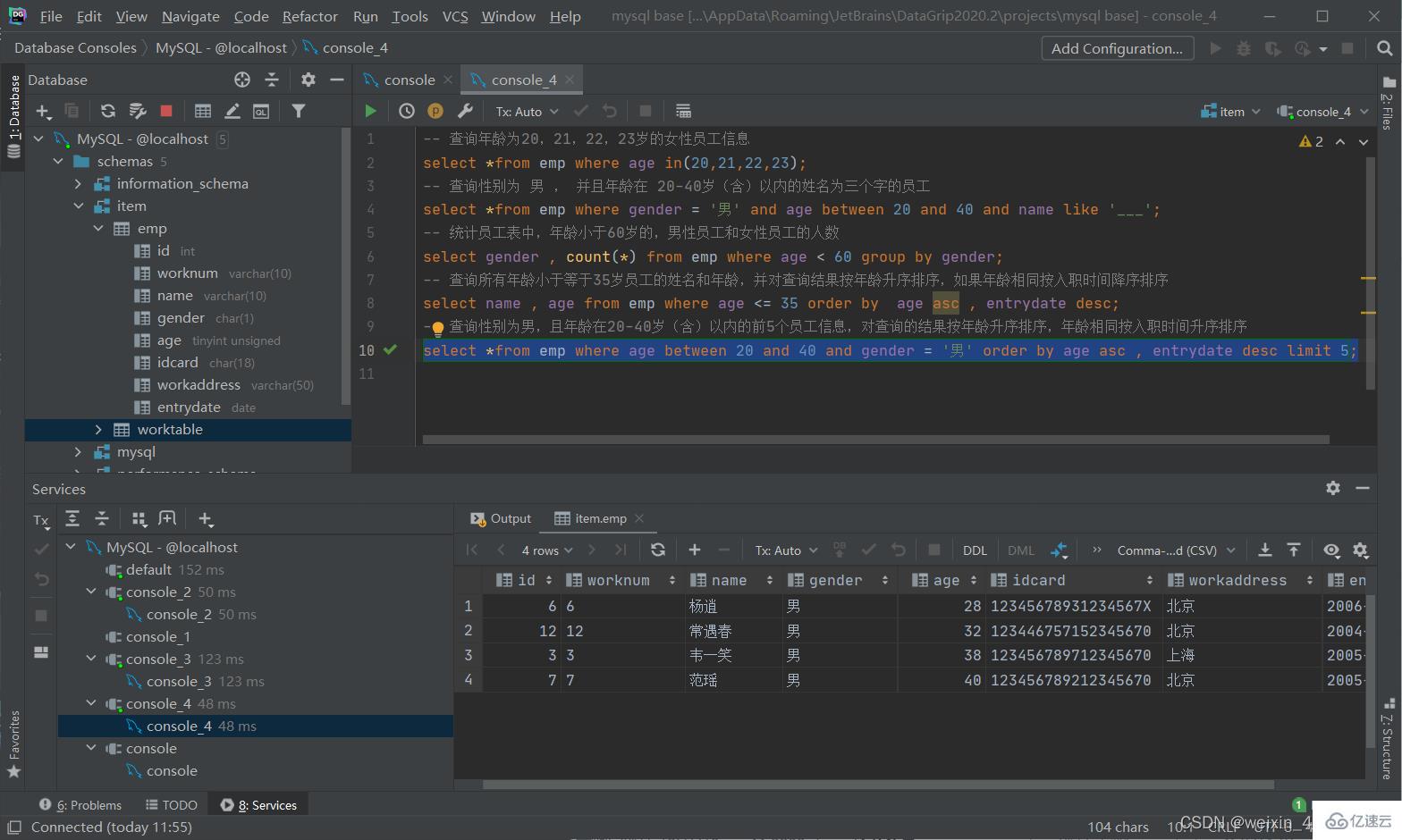
案例練習
整體語法順序

數據控制語言,用來創建數據庫用戶,控制數據庫的訪問權限
管理用戶
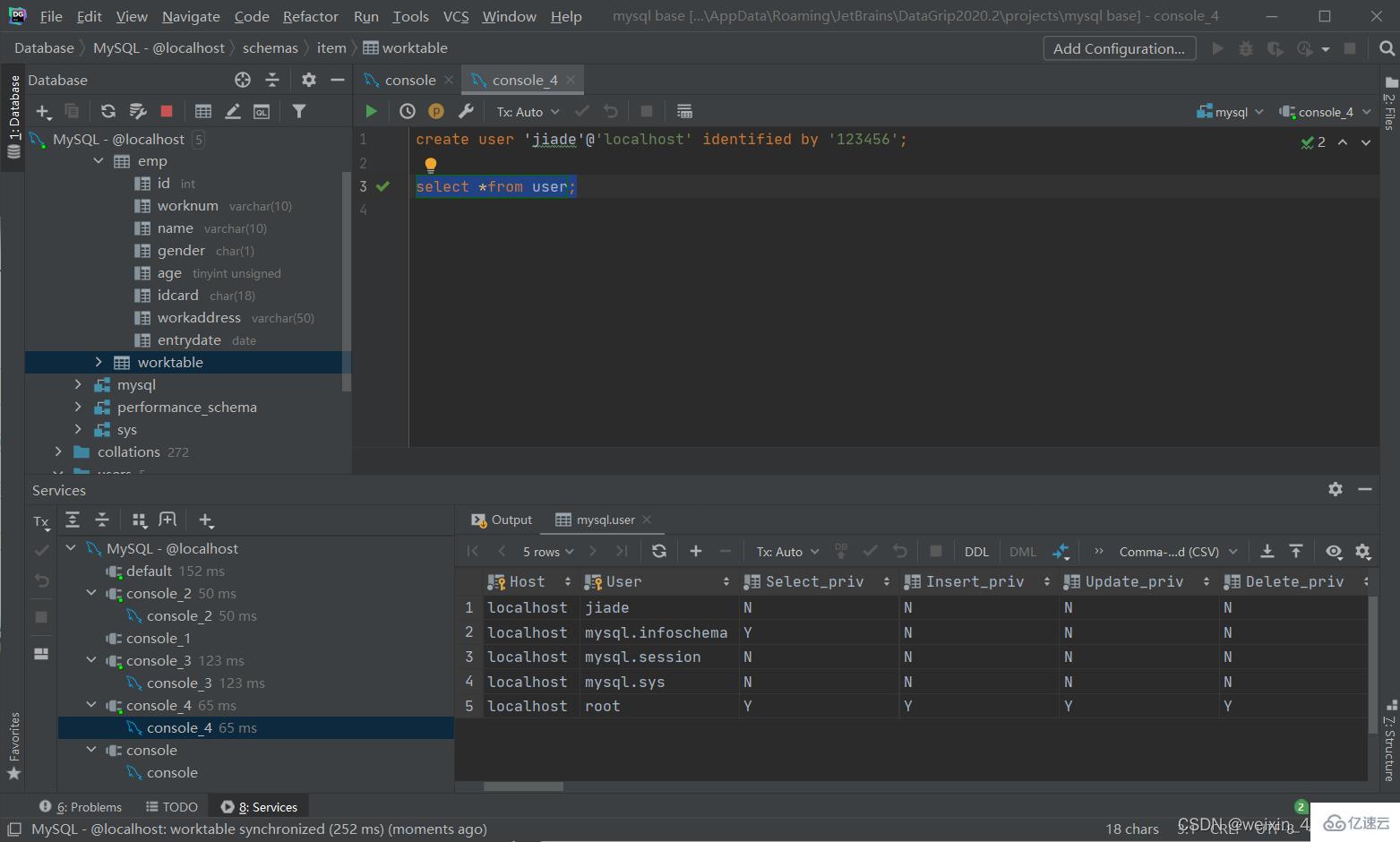
查詢用戶
use mysql;
select *from user;

創建用戶
create user '用戶名'@'主機名' identified '密碼';
修改用戶密碼
alter user '用戶名'@'主機名' identified with mysql_native_password by '新密碼';
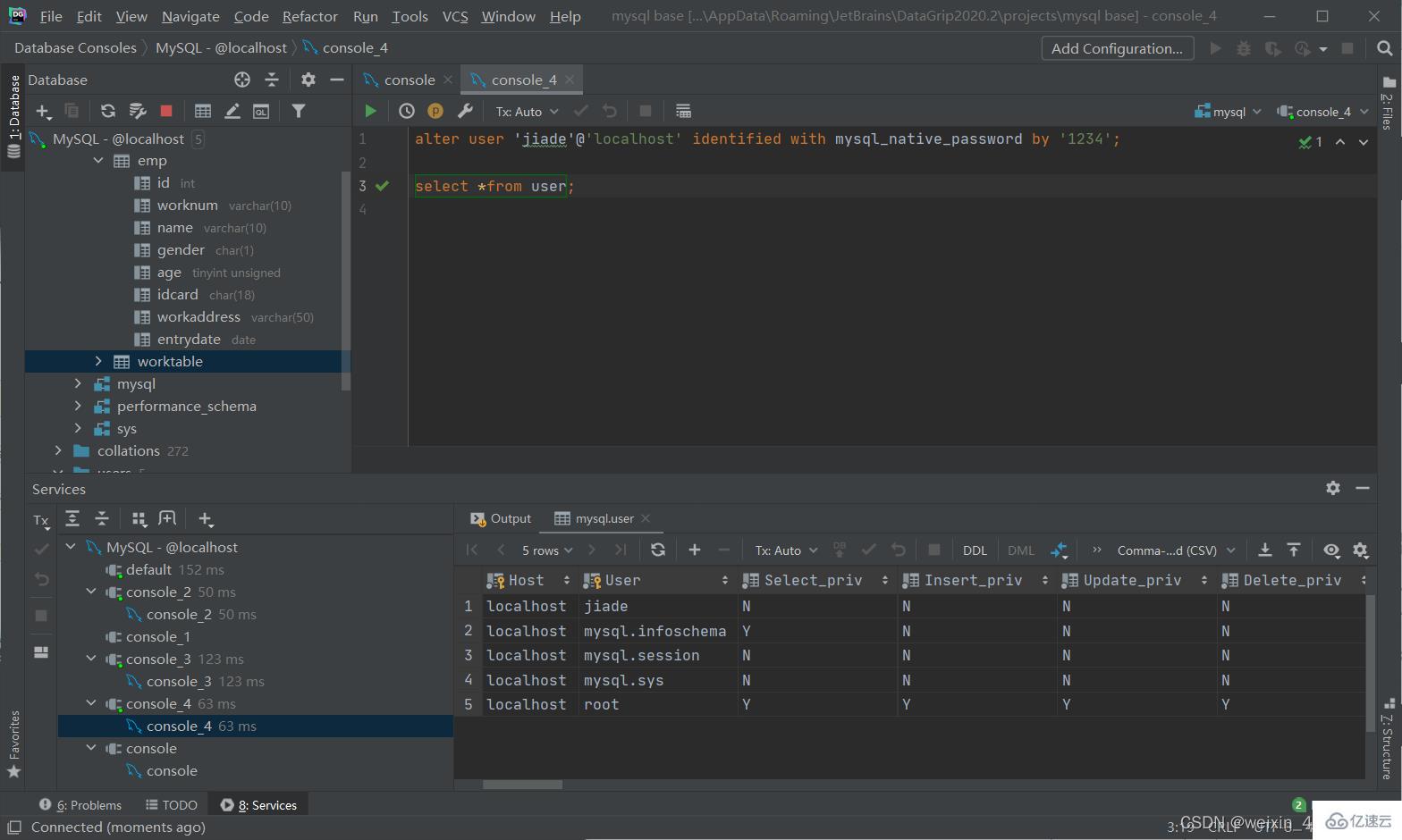
刪除用戶
drop user '用戶名'@'主機名';
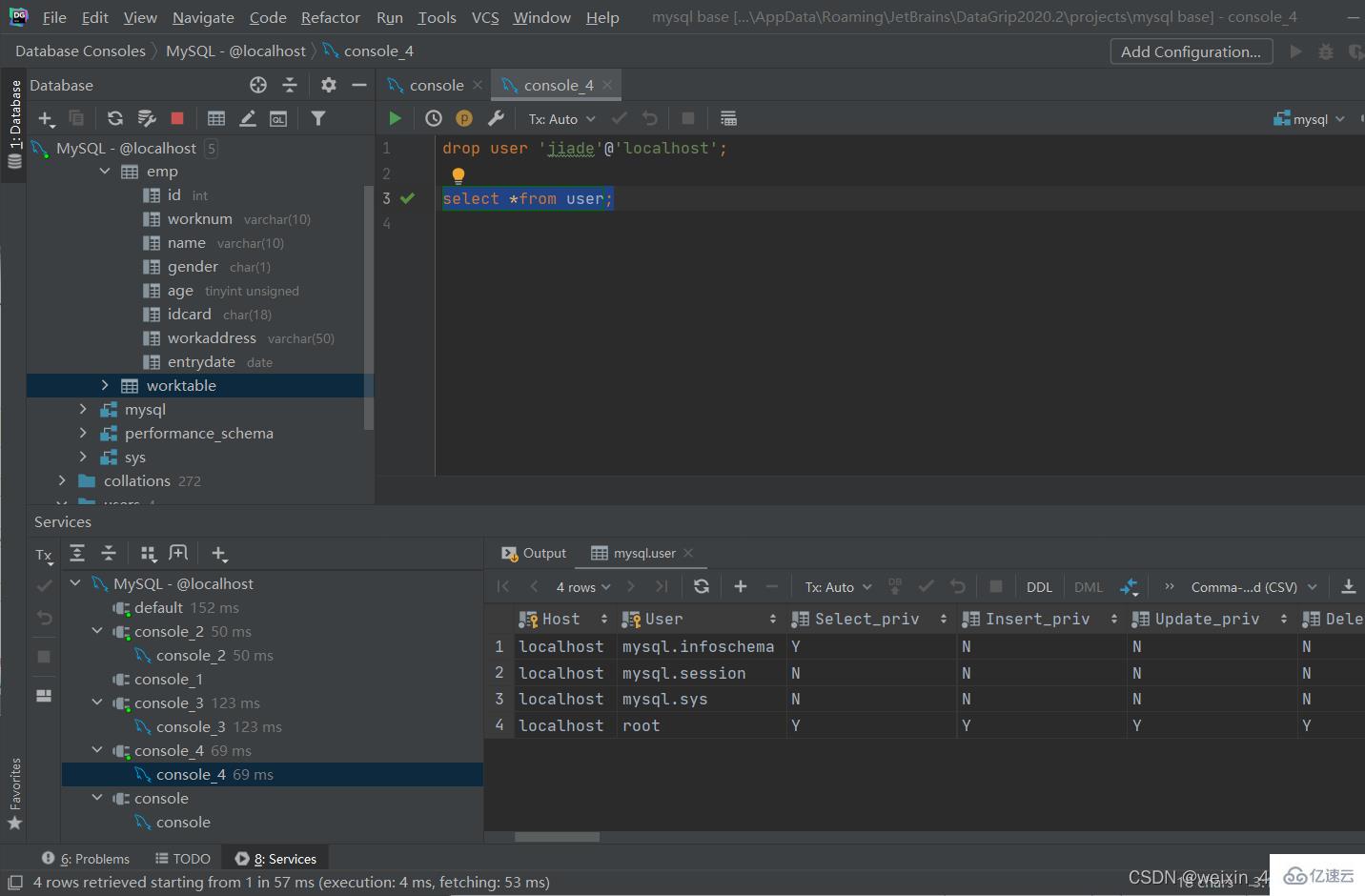
[注]:
主機名可以使用%通配
這類SQL開發人員操作的比較少,主要是DBA(Database Administrator)使用
權限控制
常用的權限
| 權限 | 說明 |
| all,all privileges | 所有權限 |
| select | 查詢數據 |
| insert | 插入數據 |
| update | 修改數據 |
| delete | 刪除數據 |
| alter | 修改表 |
| drop | 刪除數據庫/表/視圖 |
| create | 創建數據庫/表 |
查詢權限
show grants for '用戶名'@'主機名';
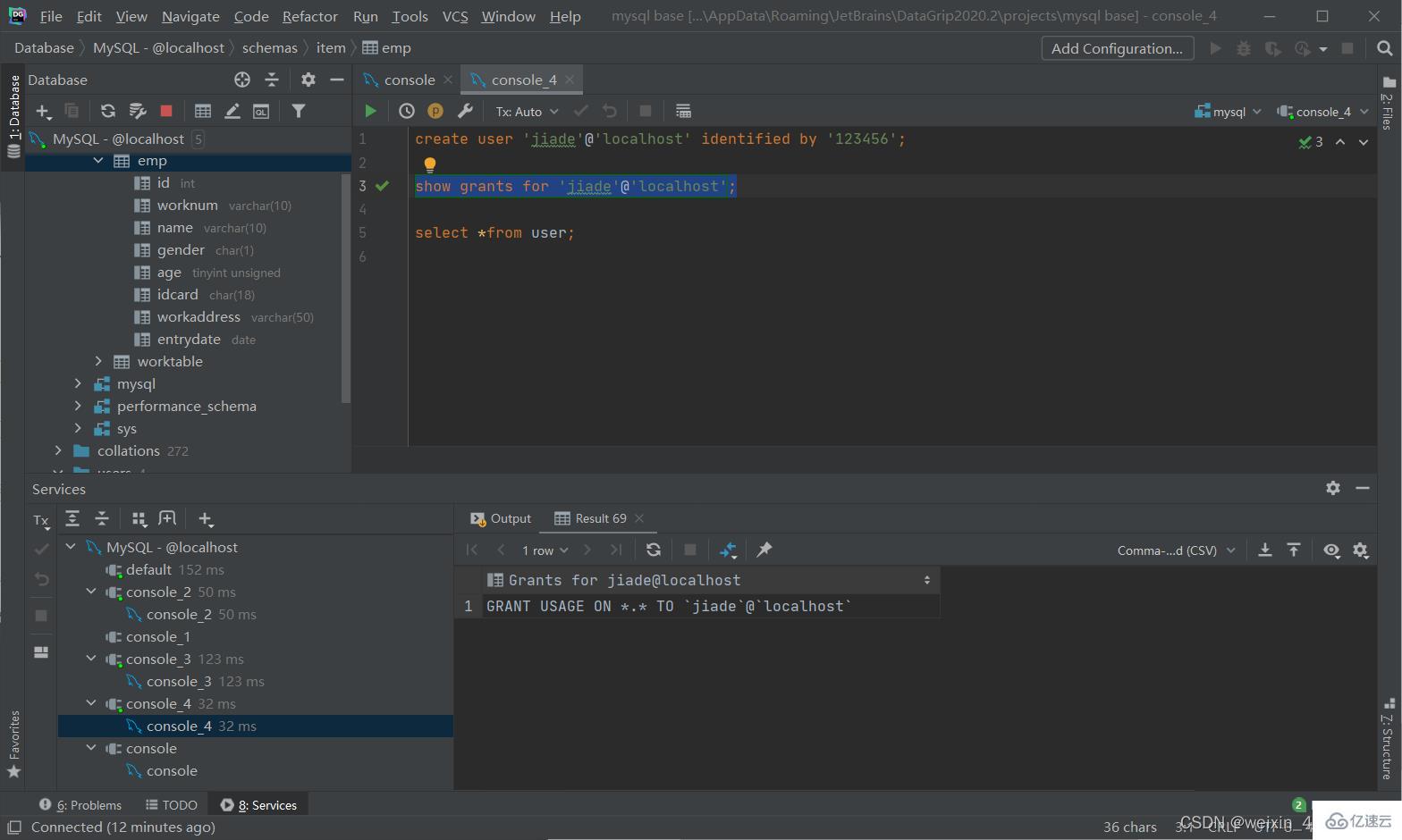
授予權限
grant 權限列表 on 數據庫名.表名 to '用戶名'@'主機名';
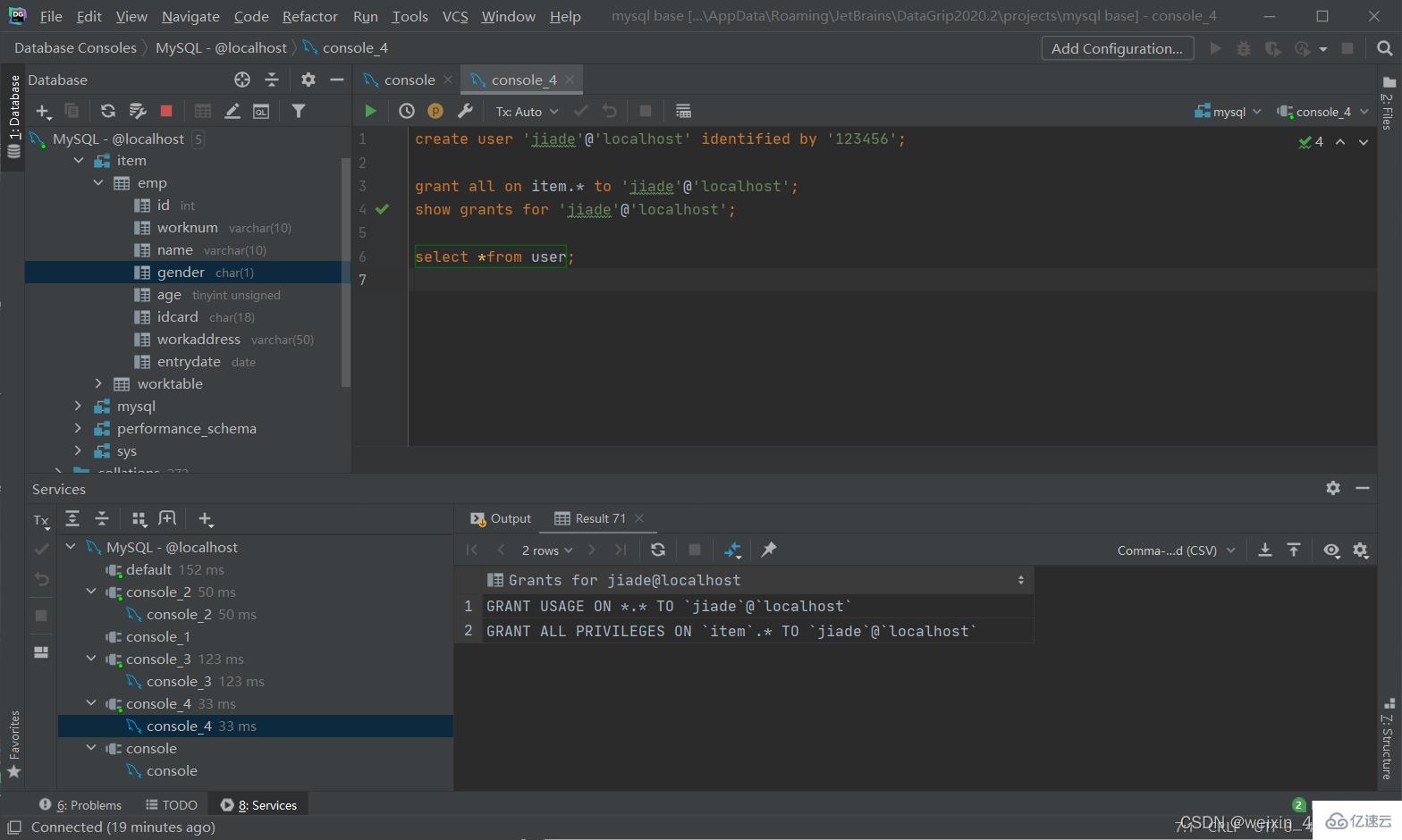
撤銷權限
revoke 權限列表 on 數據庫名.表名 from '用戶名'@'主機名';
[注]:
多個權限之間,使用逗號分割
授權時,數據庫名和表名可以使用 * 進行通配,代表所有
到此,相信大家對“SQL基本語句有哪些及怎么使用”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





