溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“RabbitMQ集群原理是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“RabbitMQ集群原理是什么”吧!
RabbitMQ 本身是基于 Erlang 編寫的,Erlang 語言本質上是分布式的(通過同步 Erlang 集群各個節點的 erlang.cookie 來實現)。因此,RabbitMQ 自然支持集群。集群是保證可靠性的一種方式,同時可以橫向擴展,達到提高消息吞吐量的目的。
下圖顯示了一個集群示例:
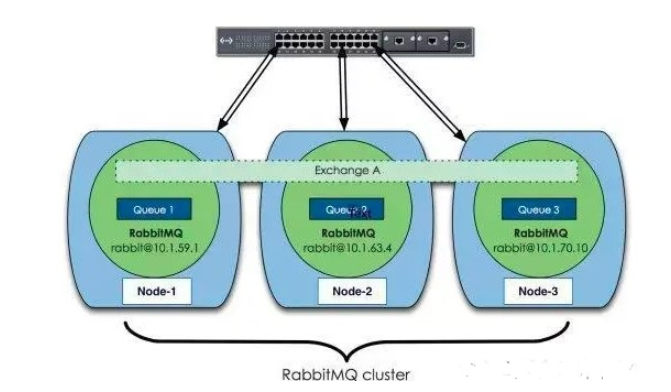
上面圖中采用三個節點組成了一個RabbitMQ的集群,Exchange A(交換器)的元數據信息在所有節點上是一致的,而Queue(存放消息的隊列)的完整數據則只會存在于它所創建的那個節點上。,其他節點只知道這個queue的metadata信息和一個指向queue的owner node的指針。
RabbitMQ集群元數據的同步
RabbitMQ集群會始終同步四種類型的內部元數據:
a. 隊列元數據:隊列名稱和它的屬性
b. 交換器元數據:交換器名稱、類型和屬性
c. 綁定元數據:一張簡單的表格展示了如何將消息路由到隊列
d. vhost元數據:為vhost內的隊列、交換器和綁定提供命名空間和安全屬性
因此,當用戶訪問其中任何一個RabbitMQ節點時,通過rabbitmqctl查詢到的queue/user/exchange/vhost等信息都是相同的。
為什么 RabbitMQ 集群只使用元數據同步?
(1)存儲空間。如果每個集群節點都有所有Queue的完整數據副本,那么每個節點的存儲空間會非常大,集群的消息積壓能力會很弱(消息積壓能力無法通過擴容來提升)集群節點);
(2)性能。消息的發布者需要將消息復制到每個集群節點。對于持久化消息,網絡和磁盤同步復制的開銷會顯著增加。
RabbitMQ集群工作原理圖如下:

客戶端直接連接隊列所在節點
如果消息生產者或消息消費者通過amqp-client的客戶端連接到節點1發布或訂閱消息,那么此時集群中的消息發送和接收只與節點1相關。
客戶端連接到非隊列數據所在節點
如果消息生產者連接到節點2或節點3,隊列1的完整數據不在這兩個節點上,那么這兩個節點在發送消息的過程中主要起到路由轉發的作用,根據這兩個節點上的元數據被轉發到節點1,最終發送的消息仍然會存儲在節點1的隊列1中。同樣,如果消息消費者連接的節點2或節點3,這兩個節點也會充當路由節點轉發消息,消息會從節點1的隊列1中拉取消費。
集群節點類型
磁盤節點:在磁盤上存儲配置信息和元信息(單節點系統必須是磁盤節點,否則每次重啟RabbitMQ都會丟失所有系統配置信息)。
內存節點:在內存中存儲配置信息和元信息。性能優于磁盤節點。
RabbitMQ 要求集群中至少有一個磁盤節點。當節點加入和離開集群時,必須通知磁盤節點(如果集群中唯一的磁盤節點崩潰,則不能創建隊列、創建交換機、創建綁定、添加用戶、更改權限、添加和刪除集群節點)。簡而言之,如果唯一磁盤的磁盤節點崩潰,集群可以繼續運行,但什么都不能改變。因此,建議在集群中設置兩個磁盤節點,只要一個可用,就可以正常運行。
概括
普通集群模式不保證隊列的高可用。雖然交換機和綁定可以復制到集群中的任何節點,但不會復制隊列的內容。這種模式雖然解決了一個項目組的節點壓力,但是隊列節點的宕機直接導致隊列不可用,只能等待重啟。因此,如果要在隊列節點宕機或故障時正常工作,必須將隊列的內容復制到集群中的各個節點,并且必須創建鏡像隊列。
鏡像隊列是在普通集群模式的基礎上,再加入一些策略。所以必須先配置普通集群,然后才能設置鏡像隊列。鏡像隊列存在于多個節點上。要實現鏡像模式,需要先搭建一個普通的集群模式,然后在這個模式的基礎上配置鏡像模式,實現高可用。
鏡像隊列的結構

鏡像隊列基本上就是一個特殊的BackingQueue,它包裝了一個普通的BackingQueue,用于本地消息持久化處理,并在此基礎上增加了復制消息和確認所有鏡像的功能。mirror_queue_master 上的所有操作都會通過可靠的多播 GM 同步到各個從節點。GM負責消息的廣播,mirror_queue_slave負責回調處理,master上的回調處理由coordinator完成。mirror_queue_slave包含了普通的BackingQueue用于消息存儲,主節點的BackingQueue包含在mirror_queue_master中,被AMQQueue調用。
消息的發布(Basic.Publish除外)和消費都是通過主節點完成的。主節點在處理消息的同時,通過 GM 將消息的處理動作廣播給所有從節點。slave節點的GM收到消息后,通過回調將消息交還給mirror_queue_slave進行實際處理。
對于 Basic.Publish,消息同時發送到主服務器和所有從服務器。如果此時master宕機了,消息也會發給slave,這樣slave提升為master時消息就不會丟失。
GM(保證組播)
GM模塊實現的一種可靠的組播通信協議,可以保證組播消息的原子性,即保證組內所有存活的節點都收到或不收到消息。
其實現大致如下:
所有節點組成一個循環鏈表,每個節點都會監控自己左右兩邊的節點。當添加一個節點時,相鄰節點保證將當前廣播消息復制到新節點;當某個節點發生故障時,相鄰節點將接管,以確保將廣播消息復制到所有節點。主節點和從節點上的這些gm組成一個組,組的信息(gm_group)會記錄在mnesia中。不同的鏡像隊列形成不同的組。消息從主節點發送到gm后,沿著鏈表依次傳遞給所有節點。由于所有節點形成一個循環鏈表,主節點對應的gm最終會收到自己發送的消息。此時,主節點將知道消息已發送。復制到所有從節點。
新節點
新節點的加入流程如下圖所示:
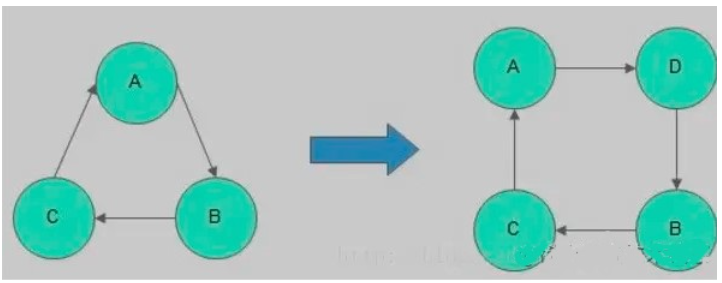
每當節點加入或重新加入(例如從網絡分區恢復)鏡像隊列時,之前保存的隊列內容將被清除。
在現有鏡像隊列中添加新節點時,默認ha-sync-mode=manual,除非顯式調用同步命令,否則鏡像隊列中的消息不會主動同步到新節點。當調用同步命令時,隊列開始阻塞,直到同步完成才能操作。
當 ha-sync-mode=automatic 時,添加新節點時默認同步已知鏡像隊列。由于同步過程的限制,不建議在生產消費隊列中操作。
節點故障
如果一個從站發生故障,系統除了記錄之外幾乎什么都不做。master還是master,client不需要做任何動作,也不需要通知slave的失敗。如果主站失敗,則必須選擇其中一個從站作為主站。被選為新master的slave通常是最老的,因為最老的slave和之前的master之間的同步狀態應該是最好的。但是需要注意的是,如果沒有slave與master完全同步,那么之前master中未同步的消息就會丟失。
概括
鏡像節點在集群中的其他節點上擁有從屬隊列的副本。一旦主節點不可用,最舊的從隊列將被選為新的主隊列。但是鏡像隊列不能用作負載均衡器,因為每個操作都必須在所有節點上完成。這種模式的副作用也很明顯。除了降低系統性能外,如果鏡像隊列過多,大量消息進入,集群內部的網絡帶寬也會被這種同步通信大大消耗。因此,適用于對可靠性要求較高的場合。
感謝各位的閱讀,以上就是“RabbitMQ集群原理是什么”的內容了,經過本文的學習后,相信大家對RabbitMQ集群原理是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





