溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了javascript中內存指的是什么的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇javascript中內存指的是什么文章都會有所收獲,下面我們一起來看看吧。
在javascript中,內存通常指的是操作系統從主存中劃分(抽象)出來的內存空間。內存可分為兩類:1、棧內存,是一段連續的內存空間,容量較小,主要用于存放函數調用信息和變量等數據,大量的內存分配操作會導致棧溢出;2、堆內存,是一大片內存空間,堆內存的分配是動態且不連續的,程序可以按需申請堆內存空間,但是訪問速度要比棧內存慢不少。
本教程操作環境:windows7系統、javascript1.8.5版、Dell G3電腦。
JavaScript 誕生于 1995 年,最初被設計用于網頁內的表單驗證。
這些年來 JavaScript 成長飛速,生態圈日益壯大,成為了最受程序員歡迎的開發語言之一。并且現在的 JavaScript 不再局限于網頁端,已經擴展到了桌面端、移動端以及服務端。
隨著大前端時代的到來,使用 JavaScript 的開發者越來越多,但是許多開發者都只停留在“會用”這個層面,而對于這門語言并沒有更多的了解。
如果想要成為一名更好的 JavaScript 開發者,理解內存是一個不可忽略的關鍵點。
本文主要包含兩大部分:
JavaScript 內存詳解
JavaScript 內存分析指南
相信大家都對內存有一定的了解,我就不從盤古開天辟地開始講了,稍微提一下。
首先,任何應用程序想要運行都離不開內存。
另外,我們提到的內存在不同的層面上有著不同的含義。
硬件層面(Hardware)
在硬件層面上,內存指的是隨機存取存儲器。
內存是計算機重要組成部分,用來儲存應用運行所需要的各種數據,CPU 能夠直接與內存交換數據,保證應用能夠流暢運行。
一般來說,在計算機的組成中主要有兩種隨機存取存儲器:高速緩存(Cache)和主存儲器(Main memory)。
高速緩存通常直接集成在 CPU 內部,離我們比較遠,所以更多時候我們提到的(硬件)內存都是主存儲器。
? 隨機存取存儲器(Random Access Memory,RAM)
隨機存取存儲器分為靜態隨機存取存儲器(Static Random Access Memory,SRAM)和動態隨機存取存儲器(Dynamic Random Access Memory,DRAM)兩大類。
在速度上 SRAM 要遠快于 DRAM,而 SRAM 的速度僅次于 CPU 內部的寄存器。
在現代計算機中,高速緩存使用的是 SRAM,而主存儲器使用的是 DRAM。
? 主存儲器(Main memory,主存)
雖然高速緩存的速度很快,但是其存儲容量很小,小到幾 KB 最大也才幾十 MB,根本不足以儲存應用運行的數據。
我們需要一種存儲容量與速度適中的存儲部件,讓我們在保證性能的情況下,能夠同時運行幾十甚至上百個應用,這也就是主存的作用。
計算機中的主存其實就是我們平時說的內存條(硬件)。
硬件內存不是我們今天的主題,所以就說這么多,想要深入了解的話可以根據上面提到關鍵詞進行搜索。
軟件層面(Software)
在軟件層面上,內存通常指的是操作系統從主存中劃分(抽象)出來的內存空間。
此時內存又可以分為兩類:棧內存和堆內存。
接下來我將圍繞 JavaScript 這門語言來對內存進行講解。
在后面的文章中所提到的內存均指軟件層面上的內存。
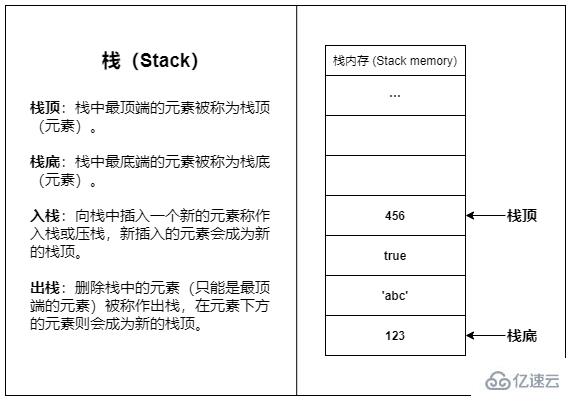
? 棧(Stack)
棧是一種常見的數據結構,棧只允許在結構的一端操作數據,所有數據都遵循后進先出(Last-In First-Out,LIFO)的原則。
現實生活中最貼切的的例子就是羽毛球桶,通常我們只通過球桶的一側來進行存取,最先放進去的羽毛球只能最后被取出,而最后放進去的則會最先被取出。
棧內存之所以叫做棧內存,是因為棧內存使用了棧的結構。
棧內存是一段連續的內存空間,得益于棧結構的簡單直接,棧內存的訪問和操作速度都非常快。
棧內存的容量較小,主要用于存放函數調用信息和變量等數據,大量的內存分配操作會導致棧溢出(Stack overflow)。
棧內存的數據儲存基本都是臨時性的,數據會在使用完之后立即被回收(如函數內創建的局部變量在函數返回后就會被回收)。
簡單來說:棧內存適合存放生命周期短、占用空間小且固定的數據。
? 棧內存的大小
棧內存由操作系統直接管理,所以棧內存的大小也由操作系統決定。
通常來說,每一條線程(Thread)都會有獨立的棧內存空間,Windows 給每條線程分配的棧內存默認大小為 1MB。
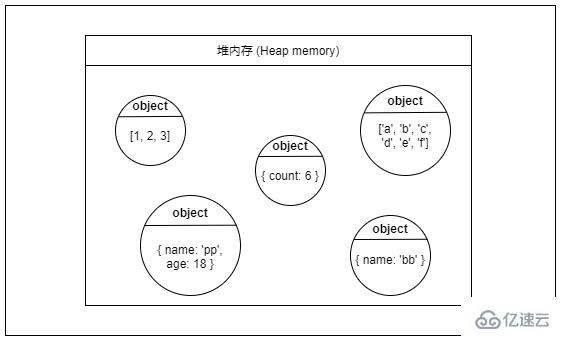
? 堆(Heap)
堆也是一種常見的數據結構,但是不在本文討論范圍內,就不多說了。
堆內存雖然名字里有個“堆”字,但是它和數據結構中的堆沒半毛錢關系,就只是撞了名罷了。
堆內存是一大片內存空間,堆內存的分配是動態且不連續的,程序可以按需申請堆內存空間,但是訪問速度要比棧內存慢不少。
堆內存里的數據可以長時間存在,無用的數據需要程序主動去回收,如果大量無用數據占用內存就會造成內存泄露(Memory leak)。
簡單來說:堆內存適合存放生命周期長,占用空間較大或占用空間不固定的數據。
? 堆內存的上限
在 Node.js 中,堆內存默認上限在 64 位系統中約為 1.4 GB,在 32 位系統中約為 0.7 GB。
而在 Chrome 瀏覽器中,每個標簽頁的內存上限約為 4 GB(64 位系統)和 1 GB(32 位系統)。
? 進程、線程與堆內存
通常來說,一個進程(Process)只會有一個堆內存,同一進程下的多個線程會共享同一個堆內存。
在 Chrome 瀏覽器中,一般情況下每個標簽頁都有單獨的進程,不過在某些情況下也會出現多個標簽頁共享一個進程的情況。
明白了棧內存與堆內存是什么后,現在讓我們看看當一個函數被調用時,棧內存和堆內存會發生什么變化。
當函數被調用時,會將函數推入棧內存中,生成一個棧幀(Stack frame),棧幀可以理解為由函數的返回地址、參數和局部變量組成的一個塊;當函數調用另一個函數時,又會將另一個函數也推入棧內存中,周而復始;直到最后一個函數返回,便從棧頂開始將棧內存中的元素逐個彈出,直到棧內存中不再有元素時則此次調用結束。
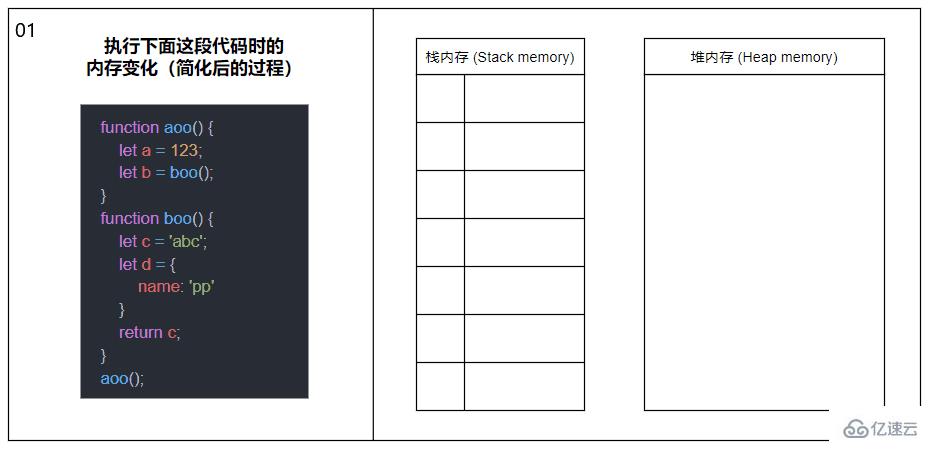
上圖中的內容經過了簡化,剝離了棧幀和各種指針的概念,主要展示函數調用以及內存分配的大概過程。
在同一線程下(JavaScript 是單線程的),所有被執行的函數以及函數的參數和局部變量都會被推入到同一個棧內存中,這也就是大量遞歸會導致棧溢出(Stack overflow)的原因。
關于圖中涉及到的函數內部變量內存分配的詳情請接著往下看。
當 JavaScript 程序運行時,在非全局作用域中產生的局部變量均儲存在棧內存中。
但是,只有原始類型的變量是真正地把值儲存在棧內存中。
而引用類型的變量只在棧內存中儲存一個引用(reference),這個引用指向堆內存里的真正的值。
? 原始類型(Primitive type)
原始類型又稱基本類型,包括
string、number、bigint、boolean、undefined、null和symbol(ES6 新增)。原始類型的值被稱為原始值(Primitive value)。
補充:雖然
typeof null返回的是'object',但是null真的不是對象,會出現這樣的結果其實是 JavaScript 的一個 Bug~
? 引用類型(Reference type)
除了原始類型外,其余類型都屬于引用類型,包括
Object、Array、Function、Date、RegExp、String、Number、Boolean等等…實際上
Object是最基本的引用類型,其他引用類型均繼承自Object。也就是說,所有引用類型的值實際上都是對象。引用類型的值被稱為引用值(Reference value)。
? 簡單來說
在多數情況下,原始類型的數據儲存在棧內存,而引用類型的數據(對象)則儲存在堆內存。
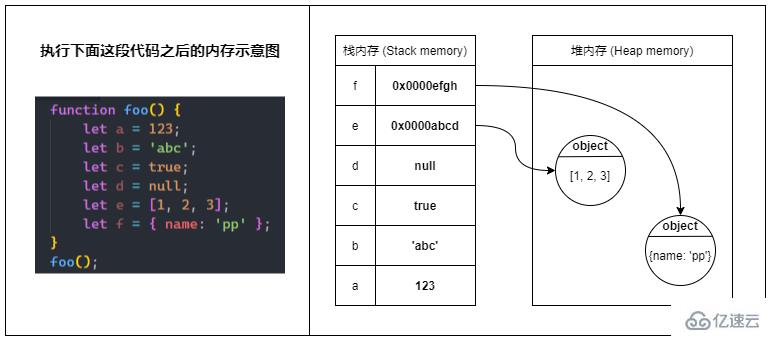
全局變量以及被閉包引用的變量(即使是原始類型)均儲存在堆內存中。
? 全局變量(Global variables)
在全局作用域下創建的所有變量都會成為全局對象(如 window 對象)的屬性,也就是全局變量。
而全局對象儲存在堆內存中,所以全局變量必然也會儲存在堆內存中。
不要問我為什么全局對象儲存在堆內存中,一會我翻臉了啊!
? 閉包(Closures)
在函數(局部作用域)內創建的變量均為局部變量。
當一個局部變量被當前函數之外的其他函數所引用(也就是發生了逃逸),此時這個局部變量就不能隨著當前函數的返回而被回收,那么這個變量就必須儲存在堆內存中。
而這里的“其他函數”就是我們說的閉包,就如下面這個例子:
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一個閉包函數
// 變量 count 發生了逃逸
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3閉包是一個非常重要且常用的概念,許多編程語言里都有閉包這個概念。這里就不詳細介紹了,貼一篇阮一峰大佬的文章。
學習 JavaScript 閉包:http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
? 逃逸分析(Escape Analysis)
實際上,JavaScript 引擎會通過逃逸分析來決定變量是要儲存在棧內存還是堆內存中。
簡單來說,逃逸分析是一種用來分析變量的作用域的機制。
棧內存中會儲存兩種變量數據:原始值和對象引用。
不僅類型不同,它們在棧內存中的具體表現也不太一樣。
? Primitive values are immutable!
前面有說到:原始類型的數據(原始值)直接儲存在棧內存中。
⑴ 當我們定義一個原始類型變量的時候,JavaScript 會在棧內存中激活一塊內存來儲存變量的值(原始值)。
⑵ 當我們更改原始類型變量的值時,實際上會再激活一塊新的內存來儲存新的值,并將變量指向新的內存空間,而不是改變原來那塊內存里的值。
⑶ 當我們將一個原始類型變量賦值給另一個新的變量(也就是復制變量)時,也是會再激活一塊新的內存,并將源變量內存里的值復制一份到新的內存里。
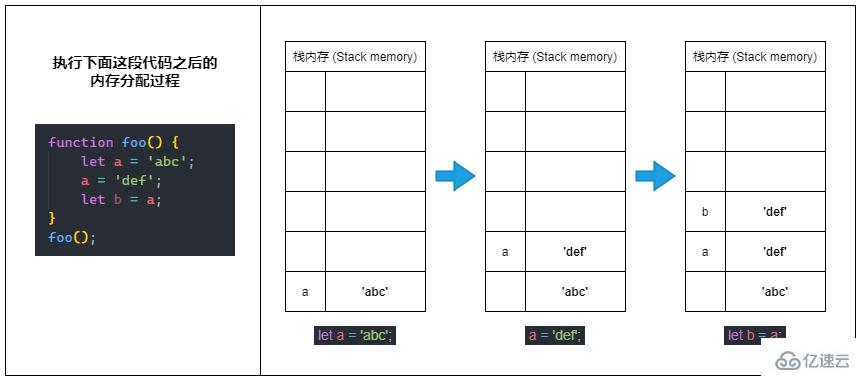
? 總之就是:棧內存中的原始值一旦確定就不能被更改(不可變的)。
當我們比較原始類型的變量時,會直接比較棧內存中的值,只要值相等那么它們就相等。
let a = '123'; let b = '123'; let c = '110'; let d = 123; console.log(a === b); // true console.log(a === c); // false console.log(a === d); // false
? Object references are mutable!
前面也有說到:引用類型的變量在棧內存中儲存的只是一個指向堆內存的引用。
⑴ 當我們定義一個引用類型的變量時,JavaScript 會先在堆內存中找到一塊合適的地方來儲存對象,并激活一塊棧內存來儲存對象的引用(堆內存地址),最后將變量指向這塊棧內存。
? 所以當我們通過變量訪問對象時,實際的訪問過程應該是:
變量 -> 棧內存中的引用 -> 堆內存中的值
⑵ 當我們把引用類型變量賦值給另一個變量時,會將源變量指向的棧內存中的對象引用復制到新變量的棧內存中,所以實際上只是復制了個對象引用,并沒有在堆內存中生成一份新的對象。
⑶ 而當我們給引用類型變量分配為一個新的對象時,則會直接修改變量指向的棧內存中的引用,新的引用指向堆內存中新的對象。
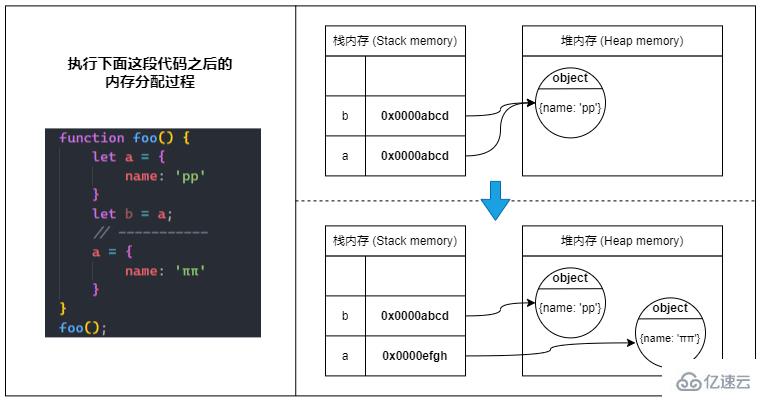
? 總之就是:棧內存中的對象引用是可以被更改的(可變的)。
所有引用類型的值實際上都是對象。
當我們比較引用類型的變量時,實際上是在比較棧內存中的引用,只有引用相同時變量才相等。
即使是看起來完全一樣的兩個引用類型變量,只要他們的引用的不是同一個值,那么他們就是不一樣。
// 兩個變量指向的是兩個不同的引用
// 雖然這兩個對象看起來完全一樣
// 但它們確確實實是不同的對象實例
let a = { name: 'pp' }
let b = { name: 'pp' }
console.log(a === b); // false
// 直接賦值的方式復制的是對象的引用
let c = a;
console.log(a === c); // true當我們搞明白引用類型變量在內存中的表現時,就能清楚地理解為什么淺拷貝對象是不可靠的。
在淺拷貝中,簡單的賦值只會復制對象的引用,實際上新變量和源變量引用的都是同一個對象,修改時也是修改的同一個對象,這顯然不是我們想要的。
想要真正的復制一個對象,就必須新建一個對象,將源對象的屬性復制過去;如果遇到引用類型的屬性,那就再新建一個對象,繼續復制…
此時我們就需要借助遞歸來實現多層次對象的復制,這也就是我們說的深拷貝。
對于任何引用類型的變量,都應該使用深拷貝來復制,除非你很確定你的目的就是復制一個引用。
通常來說,所有應用程序的內存生命周期都是基本一致的:
分配 -> 使用 -> 釋放
當我們使用高級語言編寫程序時,往往不會涉及到內存的分配與釋放操作,因為分配與釋放均已經在底層語言中實現了。
對于 JavaScript 程序來說,內存的分配與釋放是由 JavaScript 引擎自動完成的(目前的 JavaScript 引擎基本都是使用 C++ 或 C 編寫的)。
但是這不意味著我們就不需要在乎內存管理,了解內存的更多細節可以幫助我們寫出性能更好,穩定性更高的代碼。
垃圾回收即我們常說的 GC(Garbage collection),也就是清除內存中不再需要的數據,釋放內存空間。
由于棧內存由操作系統直接管理,所以當我們提到 GC 時指的都是堆內存的垃圾回收。
基本上現在的瀏覽器的 JavaScript 引擎(如 V8 和 SpiderMonkey)都實現了垃圾回收機制,引擎中的垃圾回收器(Garbage collector)會定期進行垃圾回收。
? 緊急補課
在我們繼續之前,必須先了解“可達性”和“內存泄露”這兩個概念:
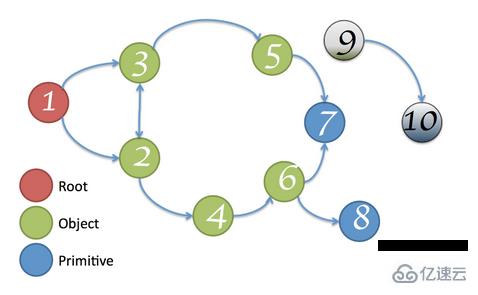
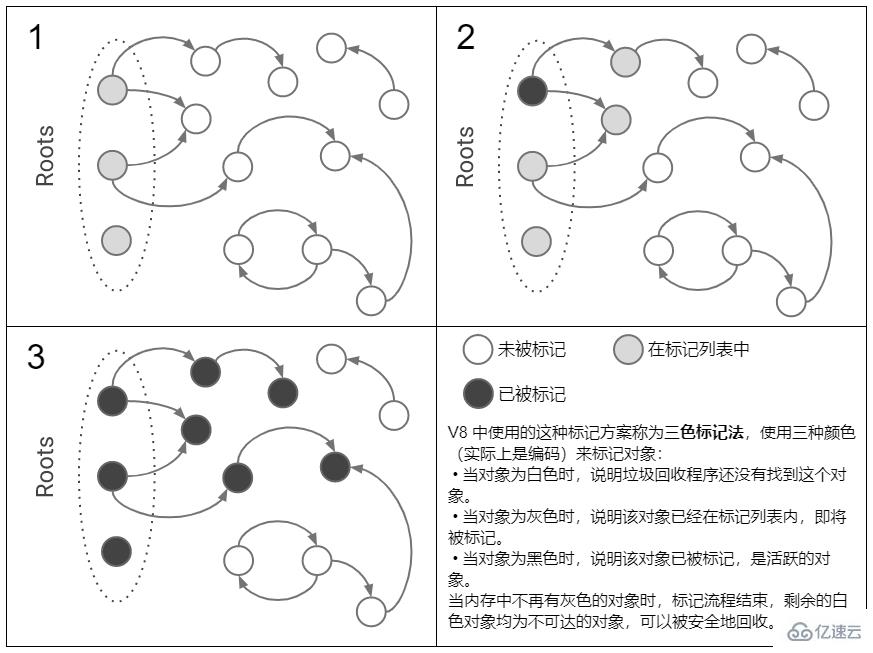
? 可達性(Reachability)
在 JavaScript 中,可達性指的是一個變量是否能夠直接或間接通過全局對象訪問到,如果可以那么該變量就是可達的(Reachable),否則就是不可達的(Unreachable)。
上圖中的節點 9 和節點 10 均無法通過節點 1(根節點)直接或間接訪問,所以它們都是不可達的,可以被安全地回收。
? 內存泄漏(Memory leak)
內存泄露指的是程序運行時由于某種原因未能釋放那些不再使用的內存,造成內存空間的浪費。
輕微的內存泄漏或許不太會對程序造成什么影響,但是一旦泄露變嚴重,就會開始影響程序的性能,甚至導致程序的崩潰。
垃圾回收的基本思路很簡單:確定哪個變量不會再使用,然后釋放它占用的內存。
實際上,在回收過程中想要確定一個變量是否還有用并不簡單。
直到現在也還沒有一個真正完美的垃圾回收算法,接下來介紹 3 種最廣為人知的垃圾回收算法。
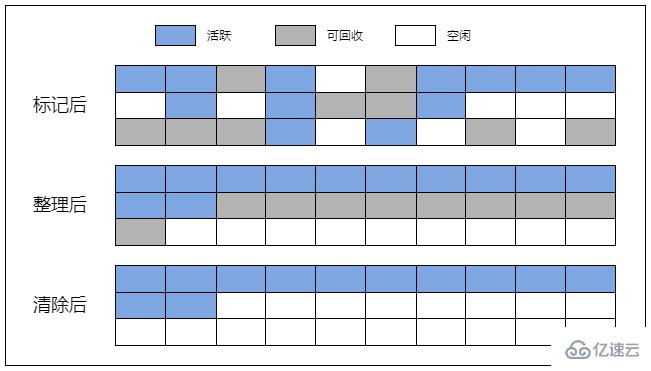
標記清除算法是目前最常用的垃圾收集算法之一。
從該算法的名字上就可以看出,算法的關鍵就是標記與清除。
標記指的是標記變量的狀態的過程,標記變量的具體方法有很多種,但是基本理念是相似的。
對于標記算法我們不需要知道所有細節,只需明白標記的基本原理即可。
需要注意的是,這個算法的效率不算高,同時會引起內存碎片化的問題。
? 舉個栗子
當一個變量進入執行上下文時,它就會被標記為“處于上下文中”;而當變量離開執行上下文時,則會被標記為“已離開上下文”。
? 執行上下文(Execution context)
執行上下文是 JavaScript 中非常重要的概念,簡單來說的是代碼執行的環境。
如果你現在對于執行上下文還不是很了解,我強烈建議你抽空專門去學習下!!!
垃圾回收器將定期掃描內存中的所有變量,將處于上下文中以及被處于上下文中的變量引用的變量的標記去除,將其余變量標記為“待刪除”。
隨后,垃圾回收器會清除所有帶有“待刪除”標記的變量,并釋放它們所占用的內存。
準確來說,Compact 應譯為緊湊、壓縮,但是在這里我覺得用“整理”更為貼切。
標記整理算法也是常用的垃圾收集算法之一。
使用標記整理算法可以解決內存碎片化的問題(通過整理),提高內存空間的可用性。
但是,該算法的標記階段比較耗時,可能會堵塞主線程,導致程序長時間處于無響應狀態。
雖然算法的名字上只有標記和整理,但這個算法通常有 3 個階段,即標記、整理與清除。
? 以 V8 的標記整理算法為例
① 首先,在標記階段,垃圾回收器會從全局對象(根)開始,一層一層往下查詢,直到標記完所有活躍的對象,那么剩下的未被標記的對象就是不可達的了。
② 然后是整理階段(碎片整理),垃圾回收器會將活躍的(被標記了的)對象往內存空間的一端移動,這個過程可能會改變內存中的對象的內存地址。
③ 最后來到清除階段,垃圾回收器會將邊界后面(也就是最后一個活躍的對象后面)的對象清除,并釋放它們占用的內存空間。
引用計數算法是基于“引用計數”實現的垃圾回收算法,這是最初級但已經被棄用的垃圾回收算法。
引用計數算法需要 JavaScript 引擎在程序運行時記錄每個變量被引用的次數,隨后根據引用的次數來判斷變量是否能夠被回收。
雖然垃圾回收已不再使用引用計數算法,但是引用計數技術仍非常有用!
? 舉個栗子
注意:垃圾回收不是即使生效的!但是在下面的例子中我們將假設回收是立即生效的,這樣會更好理解~
// 下面我將 name 屬性為 ππ 的對象簡稱為 ππ
// 而 name 屬性為 pp 的對象則簡稱為 pp
// ππ 的引用:1,pp 的引用:1
let a = {
name: 'ππ',
z: {
name: 'pp'
}
}
// b 和 a 都指向 ππ
// ππ 的引用:2,pp 的引用:1
let b = a;
// x 和 a.z 都指向 pp
// ππ 的引用:2,pp 的引用:2
let x = a.z;
// 現在只有 b 還指向 ππ
// ππ 的引用:1,pp 的引用:2
a = null;
// 現在 ππ 沒有任何引用了,可以被回收了
// 在 ππ 被回收后,pp 的引用也會相應減少
// ππ 的引用:0,pp 的引用:1
b = null;
// 現在 pp 也可以被回收了
// ππ 的引用:0,pp 的引用:0
x = null;
// 哦豁,這下全完了!? 循環引用(Circular references)
引用計數算法看似很美好,但是它有一個致命的缺點,就是無法處理循環引用的情況。
在下方的例子中,當 foo() 函數執行完畢之后,對象 a 與 b 都已經離開了作用域,理論上它們都應該能夠被回收才對。
但是由于它們互相引用了對方,所以垃圾回收器就認為他們都還在被引用著,導致它們哥倆永遠都不會被回收,這就造成了內存泄露。
function foo() {
let a = { o: null };
let b = { o: null };
a.o = b;
b.o = a;
}
foo();
// 即使 foo 函數已經執行完畢
// 對象 a 和 b 均已離開函數作用域
// 但是 a 和 b 還在互相引用
// 那么它們這輩子都不會被回收了
// Oops!內存泄露了!8?? V8
V8 是一個由 Google 開源的用 C++ 編寫的高性能 JavaScript 引擎。
V8 是目前最流行的 JavaScript 引擎之一,我們熟知的 Chrome 瀏覽器和 Node.js 等軟件都在使用 V8。
在 V8 的內存管理機制中,把堆內存(Heap memory)劃分成了多個區域。
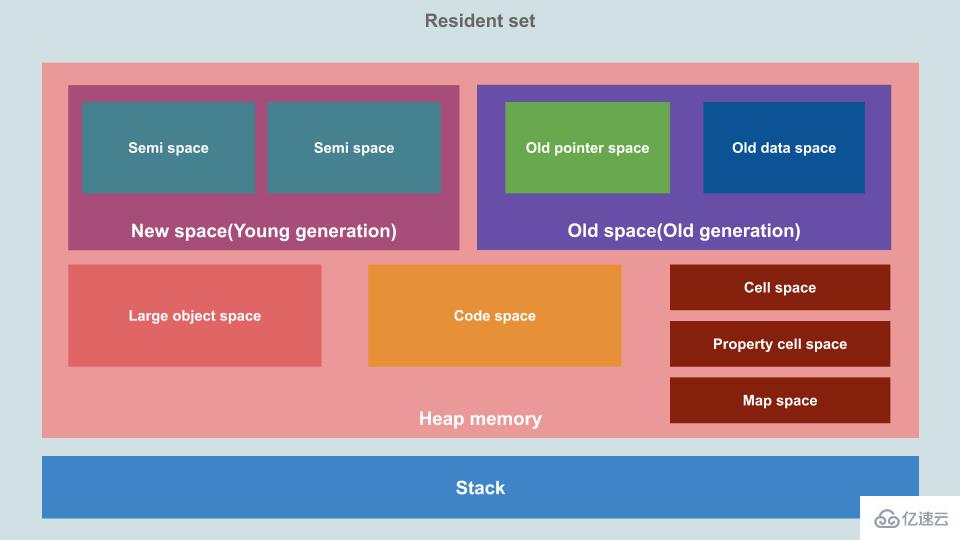
這里我們只關注這兩個區域:
New Space(新空間):又稱 Young generation(新世代),用于儲存新生成的對象,由 Minor GC 進行管理。
Old Space(舊空間):又稱 Old generation(舊世代),用于儲存那些在兩次 GC 后仍然存活的對象,由 Major GC 進行管理。
也就是說,只要 New Space 里的對象熬過了兩次 GC,就會被轉移到 Old Space,變成老油條。
? 雙管齊下
V8 內部實現了兩個垃圾回收器:
Minor GC(副 GC):它還有個名字叫做 Scavenger(清道夫),具體使用的是 Cheney’s Algorithm(Cheney 算法)。
Major GC(主 GC):使用的是文章前面提到的 Mark-Compact Algorithm(標記-整理算法)。
儲存在 New Space 里的新生對象大多都只是臨時使用的,而且 New Space 的容量比較小,為了保持內存的可用率,Minor GC 會頻繁地運行。
而 Old Space 里的對象存活時間都比較長,所以 Major GC 沒那么勤快,這一定程度地降低了頻繁 GC 帶來的性能損耗。
? 加點魔法
我們在上方的“標記整理算法”中有提到這個算法的標記過程非常耗時,所以很容易導致應用長時間無響應。
為了提升用戶體驗,V8 還實現了一個名為增量標記(Incremental marking)的特性。
增量標記的要點就是把標記工作分成多個小段,夾雜在主線程(Main thread)的 JavaScript 邏輯中,這樣就不會長時間阻塞主線程了。
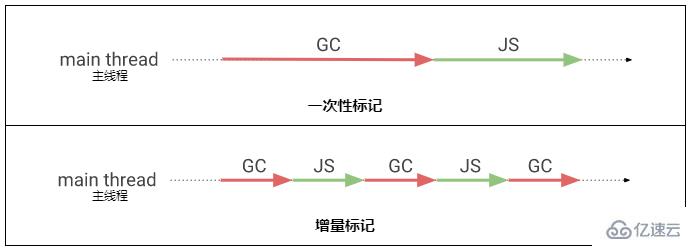
當然增量標記也有代價的,在增量標記過程中所有對象的變化都需要通知垃圾回收器,好讓垃圾回收器能夠正確地標記那些對象,這里的“通知”也是需要成本的。
另外 V8 中還有使用工作線程(Worker thread)實現的平行標記(Parallel marking)和并行標記(Concurrent marking),這里我就不再細說了~
? 總結一下
為了提升性能和用戶體驗,V8 內部做了非常非常多的“騷操作”,本文提到的都只是冰山一角,但足以讓我五體投地佩服連連!
總之就是非常 Amazing 啊~
或者說是:內存優化(Memory optimization)?
雖然我們寫代碼的時候一般不會直接接觸內存管理,但是有一些注意事項可以讓我們避免引起內存問題,甚至提升代碼的性能。
全局變量的訪問速度遠不及局部變量,應盡量避免定義非必要的全局變量。
在我們實際的項目開發中,難免會需要去定義一些全局變量,但是我們必須謹慎使用全局變量。
因為全局變量永遠都是可達的,所以全局變量永遠不會被回收。
? 還記得“可達性”這個概念嗎?
因為全局變量直接掛載在全局對象上,也就是說全局變量永遠都可以通過全局對象直接訪問。
所以全局變量永遠都是可達的,而可達的變量永遠都不會被回收。
? 應該怎么做?
當一個全局變量不再需要用到時,記得解除其引用(置空),好讓垃圾回收器可以釋放這部分內存。
// 全局變量不會被回收
window.me = {
name: '吳彥祖',
speak: function() {
console.log(`我是${this.name}`);
}
};
window.me.speak();
// 解除引用后才可以被回收
window.me = null;實際上的隱藏類遠比本文所提到的復雜,但是今天的主角不是它,所以我們點到為止。
在 V8 內部有一個叫做“隱藏類”的機制,主要用于提升對象(Object)的性能。
V8 里的每一個 JS 對象(JS Objects)都會關聯一個隱藏類,隱藏類里面儲存了對象的形狀(特征)和屬性名稱到屬性的映射等信息。
隱藏類內記錄了每個屬性的內存偏移(Memory offset),后續訪問屬性的時候就可以快速定位到對應屬性的內存位置,從而提升對象屬性的訪問速度。
在我們創建對象時,擁有完全相同的特征(相同屬性且相同順序)的對象可以共享同一個隱藏類。
? 再想象一下
我們可以把隱藏類想象成工業生產中使用的模具,有了模具之后,產品的生產效率得到了很大的提升。
但是如果我們更改了產品的形狀,那么原來的模具就不能用了,又需要制作新的模具才行。
? 舉個栗子
在 Chrome 瀏覽器 Devtools 的 Console 面板中執行以下代碼:
// 對象 A
let objectA = {
id: 'A',
name: '吳彥祖'
};
// 對象 B
let objectB = {
id: 'B',
name: '彭于晏'
};
// 對象 C
let objectC = {
id: 'C',
name: '劉德華',
gender: '男'
};
// 對象 A 和 B 擁有完全相同的特征
// 所以它們可以使用同一個隱藏類
// good!隨后在 Memory 面板打一個堆快照,通過堆快照中的 Comparison 視圖可以快速找到上面創建的 3 個對象:
注:關于如何查看內存中的對象將會在文章的第二大部分中進行講解,現在讓我們專注于隱藏類。
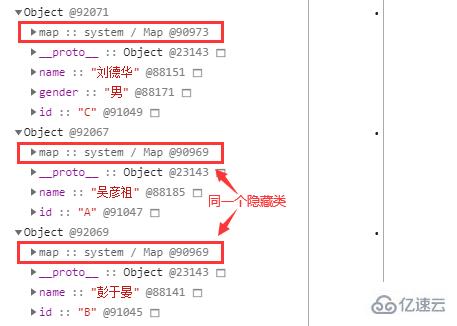
在上圖中可以很清楚地看到對象 A 和 B 確實使用了同一個隱藏類。
而對象 C 因為多了一個 gender 屬性,所以不能和前面兩個對象共享隱藏類。
? 動態增刪對象屬性
一般情況下,當我們動態修改對象的特征(增刪屬性)時,V8 會為該對象分配一個能用的隱藏類或者創建一個新的隱藏類(新的分支)。
例如動態地給對象增加一個新的屬性:
注:這種操作被稱為“先創建再補充(ready-fire-aim)”。
// 增加 gender 屬性 objectB.gender = '男'; // 對象 B 的特征發生了變化 // 多了一個原本沒有的 gender 屬性 // 導致對象 B 不能再與 A 共享隱藏類 // bad!
動態刪除(delete)對象的屬性也會導致同樣的結果:
// 刪除 name 屬性 delete objectB.name; // A:我們不一樣! // bad!
不過,添加數組索引屬性(Array-indexed properties)并不會有影響:
其實就是用整數作為屬性名,此時 V8 會另外處理。
// 增加 1 屬性 objectB[1] = '數字組引屬性'; // 不影響共享隱藏類 // so far so good!
? 那問題來了
說了這么多,隱藏類看起來確實可以提升性能,那它和內存又有什么關系呢?
實際上,隱藏類也需要占用內存空間,這其實就是一種用空間換時間的機制。
如果由于動態增刪對象屬性而創建了大量隱藏類和分支,結果就是會浪費不少內存空間。
? 舉個栗子
創建 1000 個擁有相同屬性的對象,內存中只會多出 1 個隱藏類。
而創建 1000 個屬性信息完全不同的對象,內存中就會多出 1000 個隱藏類。
? 應該怎么做?
所以,我們要盡量避免動態增刪對象屬性操作,應該在構造函數內就一次性聲明所有需要用到的屬性。
如果確實不再需要某個屬性,我們可以將屬性的值設為 null,如下:
// 將 age 屬性置空 objectB.age = null; // still good!
另外,相同名稱的屬性盡量按照相同的順序來聲明,可以盡可能地讓更多對象共享相同的隱藏類。
即使遇到不能共享隱藏類的情況,也至少可以減少隱藏類分支的產生。
其實動態增刪對象屬性所引起的性能問題更為關鍵,但因本文篇幅有限,就不再展開了。
前面有提到:被閉包引用的變量儲存在堆內存中。
這里我們再重點關注一下閉包中的內存問題,還是前面的例子:
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一個閉包函數
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3現在只要我們一直持有變量(函數) closure,那么變量 count 就不會被釋放。
或許你還沒有發現風險所在,不如讓我們試想變量 count 不是一個數字,而是一個巨大的數組,一但這樣的閉包多了,那對于內存來說就是災難。
// 我將這個作品稱為:閉包炸彈
function closureBomb() {
const handsomeBoys = [];
setInterval(() => {
for (let i = 0; i < 100; i++) {
handsomeBoys.push(
{ name: '陳皮皮', rank: 0 },
{ name: ' 你 ', rank: 1 },
{ name: '吳彥祖', rank: 2 },
{ name: '彭于晏', rank: 3 },
{ name: '劉德華', rank: 4 },
{ name: '郭富城', rank: 5 }
);
}
}, 100);
}
closureBomb();
// 即將毀滅世界
// ? ? ? ?? 應該怎么做?
所以,我們必須避免濫用閉包,并且謹慎使用閉包!
當不再需要時記得解除閉包函數的引用,讓閉包函數以及引用的變量能夠被回收。
closure = null; // 變量 count 終于得救了
說了這么多,那我們應該如何查看并分析程序運行時的內存情況呢?
“工欲善其事,必先利其器。”
對于 Web 前端項目來說,分析內存的最佳工具非 Memory 莫屬!
這里的 Memory 指的是 DevTools 中的一個工具,為了避免混淆,下面我會用“Memory 面板”或”內存面板“代稱。
? DevTools(開發者工具)
DevTools 是瀏覽器里內置的一套用于 Web 開發和調試的工具。
使用 Chromuim 內核的瀏覽器都帶有 DevTools,個人推薦使用 Chrome 或者 Edge(新)。
在我們切換到 Memory 面板后,會看到以下界面(注意標注):
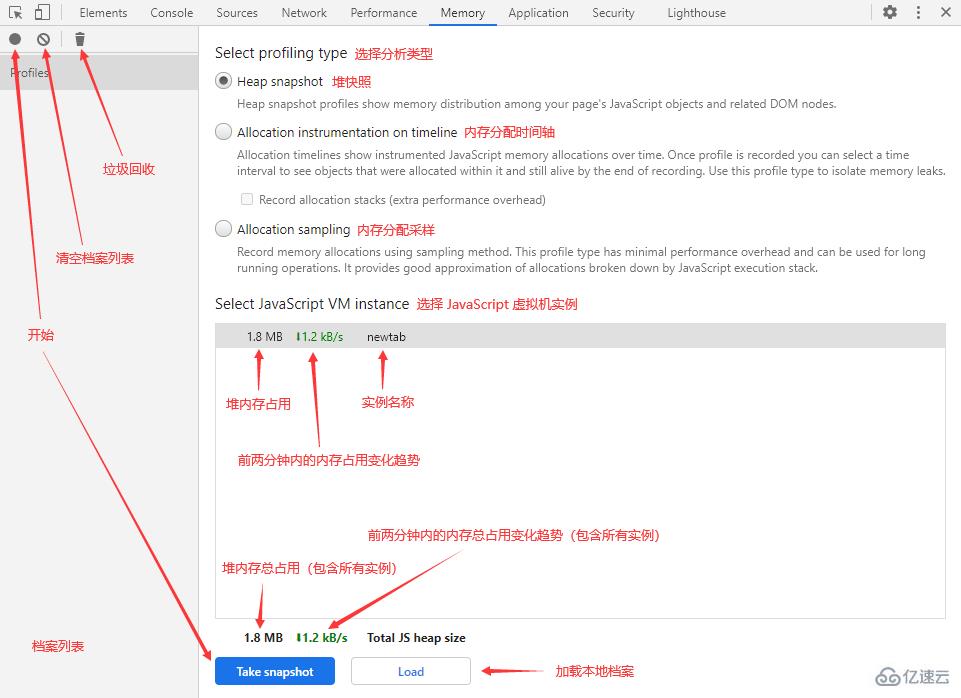
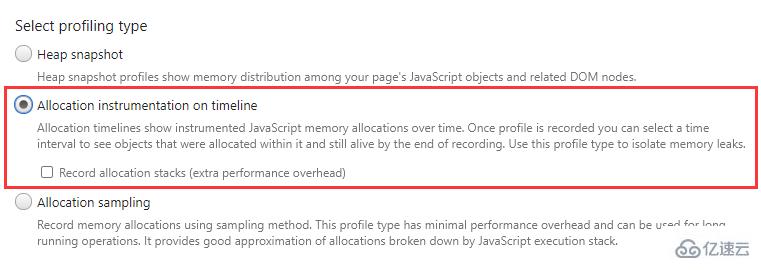
在這個面板中,我們可以通過 3 種方式來記錄內存情況:
Heap snapshot:堆快照
Allocation instrumentation on timeline:內存分配時間軸
Allocation sampling:內存分配采樣
小貼士:點擊面板左上角的 Collect garbage 按鈕(垃圾桶圖標)可以主動觸發垃圾回收。
? 在正式開始分析內存之前,讓我們先學習幾個重要的概念:
? Shallow Size(淺層大小)
淺層大小指的是當前對象自身占用的內存大小。
淺層大小不包含自身引用的對象。
? Retained Size(保留大小)
保留大小指的是當前對象被 GC 回收后總共能夠釋放的內存大小。
換句話說,也就是當前對象自身大小加上對象直接或間接引用的其他對象的大小總和。
需要注意的是,保留大小不包含那些除了被當前對象引用之外還被全局對象直接或間接引用的對象。
堆快照可以記錄頁面當前時刻的 JS 對象以及 DOM 節點的內存分配情況。
? 如何開始
點擊頁面底部的 Take snapshot 按鈕或者左上角的 ? 按鈕即可打一個堆快照,片刻之后就會自動展示結果。
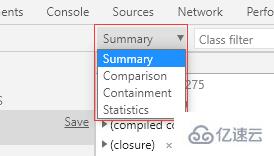
在堆快照結果頁面中,我們可以使用 4 種不同的視圖來觀察內存情況:
Summary:摘要視圖
Comparison:比較視圖
Containment:包含視圖
Statistics:統計視圖
默認顯示 Summary 視圖。
摘要視圖根據 Constructor(構造函數)來將對象進行分組,我們可以在 Class filter(類過濾器)中輸入構造函數名稱來快速篩選對象。
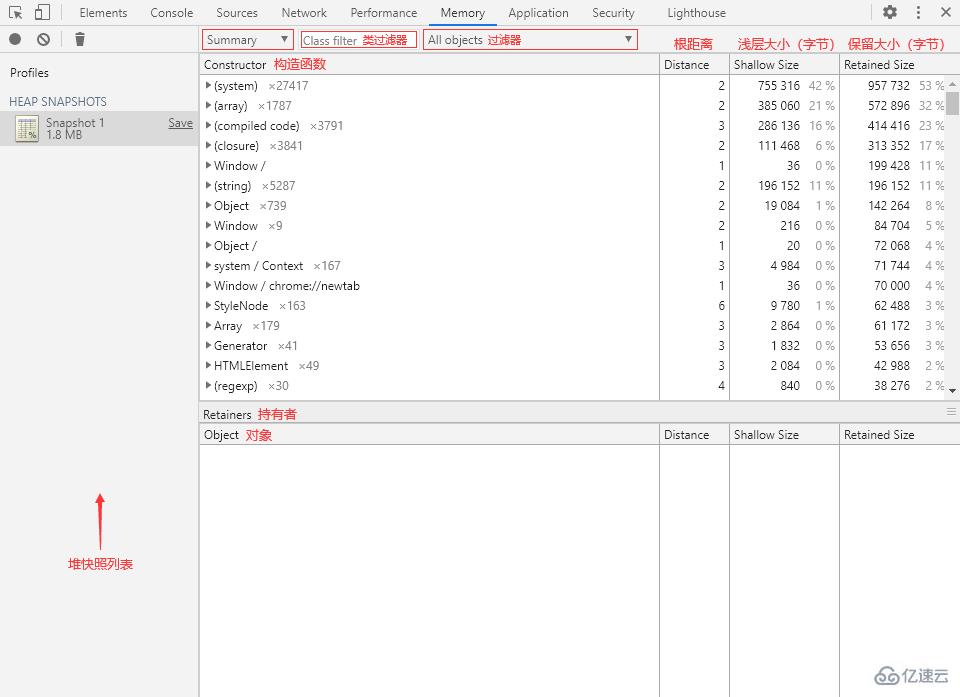
頁面中的幾個關鍵詞:
Constructor:構造函數。
Distance:(根)距離,對象與 GC 根之間的最短距離。
Shallow Size:淺層大小,單位:Bytes(字節)。
Retained Size:保留大小,單位:Bytes(字節)。
Retainers:持有者,也就是直接引用目標對象的變量。
? Retainers(持有者)
Retainers 欄在舊版的 Devtools 里叫做 Object’s retaining tree(對象保留樹)。
Retainers 下的對象也展開為樹形結構,方便我們進行引用溯源。
在視圖中的構造函數列表中,有一些用“()”包裹的條目:
(compiled code):已編譯的代碼。
(closure):閉包函數。
(array, string, number, symbol, regexp):對應類型(Array、String、Number、Symbol、RegExp)的數據。
(concatenated string):使用 concat() 函數拼接而成的字符串。
(sliced string):使用 slice()、substring() 等函數進行邊緣切割的字符串。
(system):系統(引擎)產生的對象,如 V8 創建的 HiddenClasses(隱藏類)和 DescriptorArrays(描述符數組)等數據。
? DescriptorArrays(描述符數組)
描述符數組主要包含對象的屬性名信息,是隱藏類的重要組成部分。
不過描述符數組內不會包含整數索引屬性。
而其余沒有用“()”包裹的則為全局屬性和 GC 根。
另外,每個對象后面都會有一串“@”開頭的數字,這是對象在內存中的唯一 ID。
小貼士:按下快捷鍵 Ctrl/Command + F 展示搜索欄,輸入名稱或 ID 即可快速查找目標對象。
? 實踐一下:實例化一個對象
① 切換到 Console 面板,執行以下代碼來實例化一個對象:
function TestClass() {
this.number = 123;
this.string = 'abc';
this.boolean = true;
this.symbol = Symbol('test');
this.undefined = undefined;
this.null = null;
this.object = { name: 'pp' };
this.array = [1, 2, 3];
this.getSet = {
_value: 0,
get value() {
return this._value;
},
set value(v) {
this._value = v;
}
};
}
let testObject = new TestClass();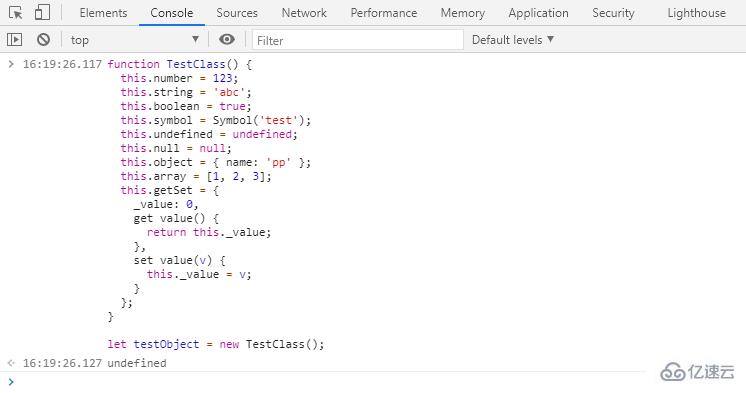
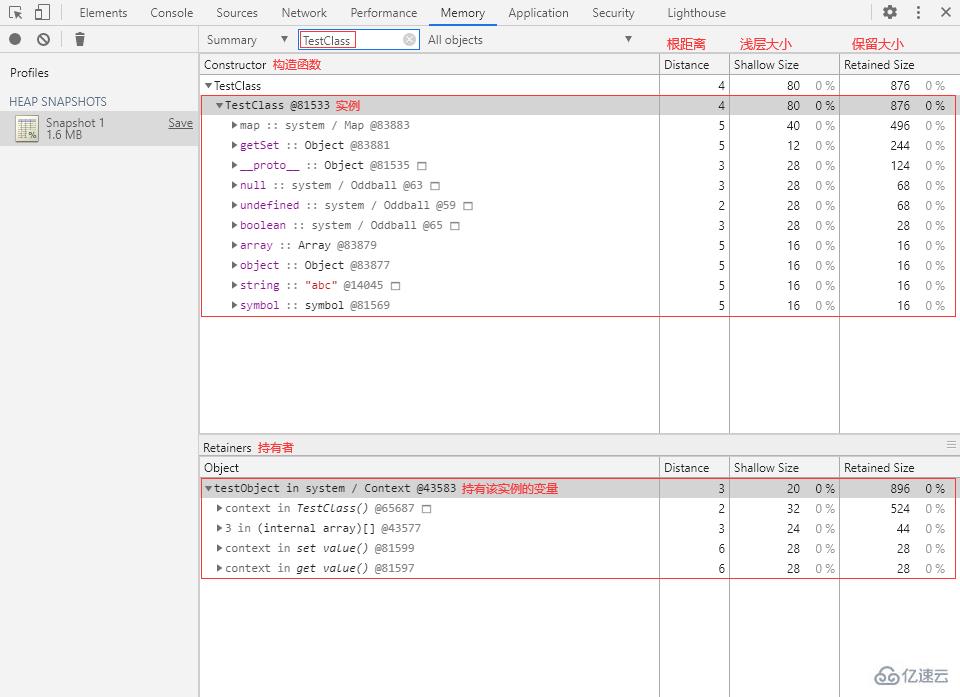
② 回到 Memory 面板,打一個堆快照,在 Class filter 中輸入“TestClass”:
可以看到內存中有一個 TestClass 的實例,該實例的淺層大小為 80 字節,保留大小為 876 字節。
? 注意到了嗎?
堆快照中的
TestClass實例的屬性中少了一個名為number屬性,這是因為堆快照不會捕捉數字屬性。
? 實踐一下:創建一個字符串
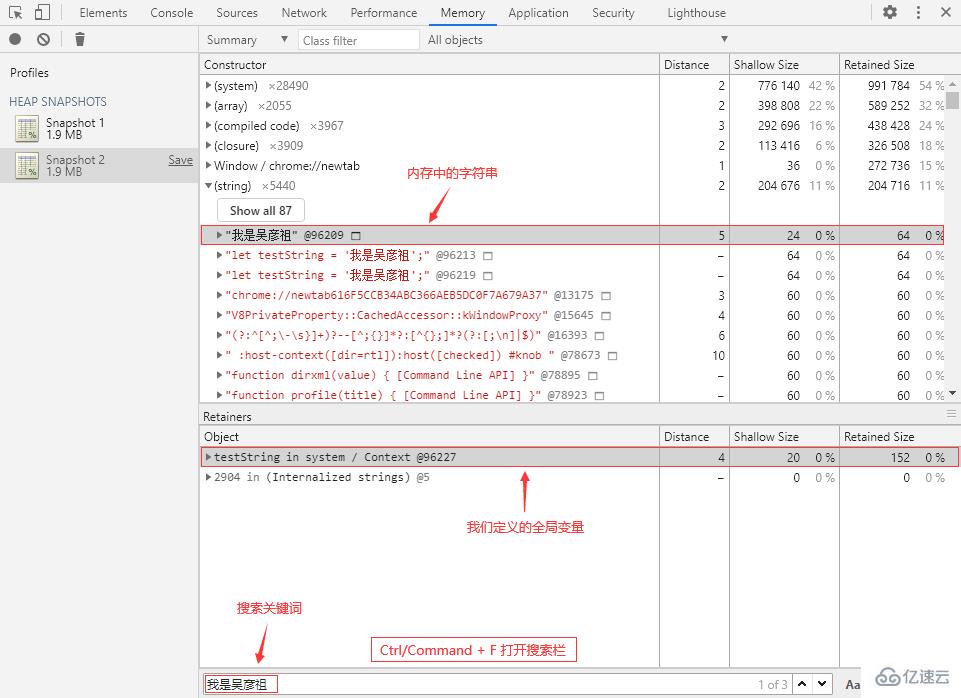
① 切換到 Console 面板,執行以下代碼來創建一個字符串:
// 這是一個全局變量 let testString = '我是吳彥祖';
② 回到 Memory 面板,打一個堆快照,打開搜索欄(Ctrl/Command + F)并輸入“我是吳彥祖”:
只有同時存在 2 個或以上的堆快照時才會出現 Comparison 選項。
比較視圖用于展示兩個堆快照之間的差異。
使用比較視圖可以讓我們快速得知在執行某個操作后的內存變化情況(如新增或減少對象)。
通過多個快照的對比還可以讓我們快速判斷并定位內存泄漏。
文章前面提到隱藏類的時候,就是使用了比較視圖來快速查找新創建的對象。
? 實踐一下
① 新建一個無痕(匿名)標簽頁并切換到 Memory 面板,打一個堆快照 Snapshot 1。
? 為什么是無痕標簽頁?
普通標簽頁會受到瀏覽器擴展或者其他腳本影響,內存占用不穩定。
使用無痕窗口的標簽頁可以保證頁面的內存相對純凈且穩定,有利于我們進行對比。
另外,建議打開窗口一段之間之后再開始測試,這樣內存會比較穩定(控制變量)。
② 切換到 Console 面板,執行以下代碼來實例化一個 Foo 對象:
function Foo() {
this.name = 'pp';
this.age = 18;
}
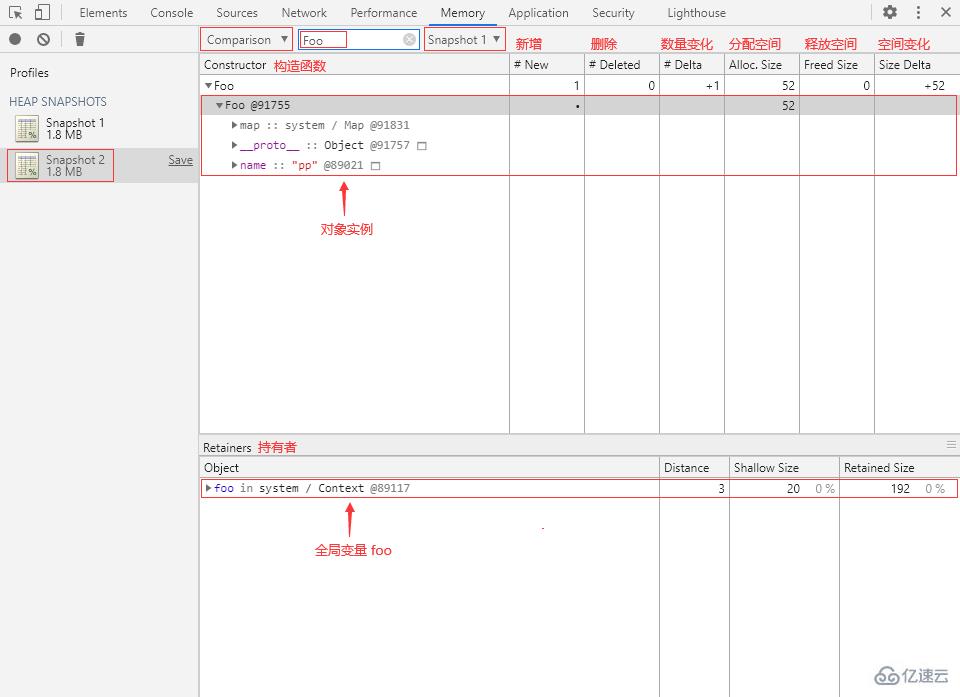
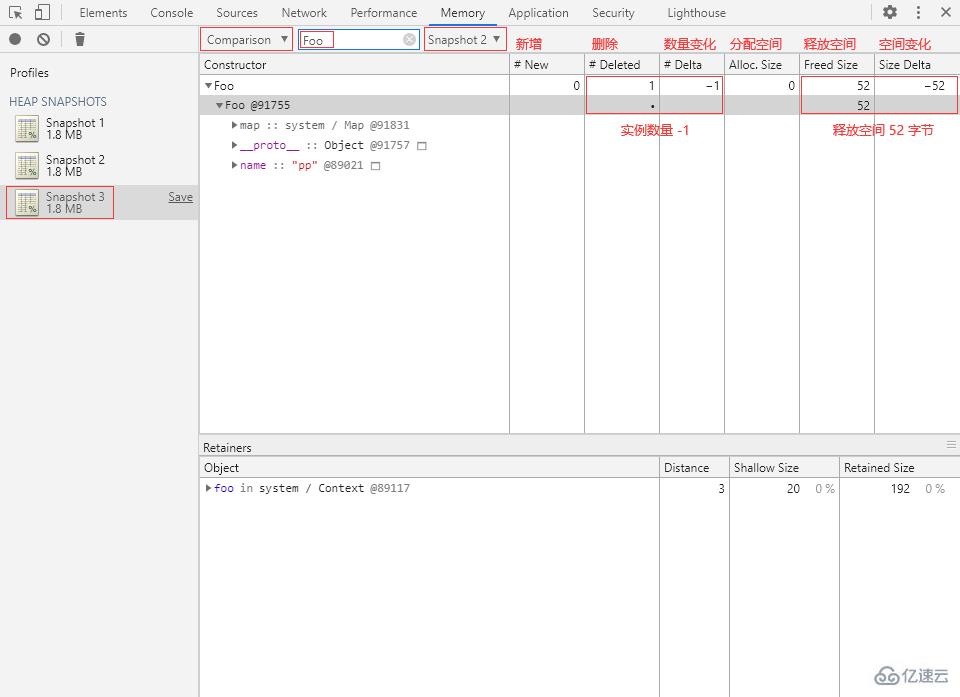
let foo = new Foo();③ 回到 Memory 面板,再打一個堆快照 Snapshot 2,切換到 Comparison 視圖,選擇 Snapshot 1 作為 Base snapshot(基本快照),在 Class filter 中輸入“Foo”:
可以看到內存中新增了一個 Foo 對象實例,分配了 52 字節內存空間,該實例的引用持有者為變量 foo。
④ 再次切換到 Console 面板,執行以下代碼來解除變量 foo 的引用:
// 解除對象的引用 foo = null;
⑤ 再回到 Memory 面板,打一個堆快照 Snapshot 3,選擇 Snapshot 2 作為 Base snapshot,在 Class filter 中輸入“Foo”:
內存中的 Foo 對象實例已經被刪除,釋放了 52 字節的內存空間。
包含視圖就是程序對象結構的“鳥瞰圖(Bird’s eye view)”,允許我們通過全局對象出發,一層一層往下探索,從而了解內存的詳細情況。
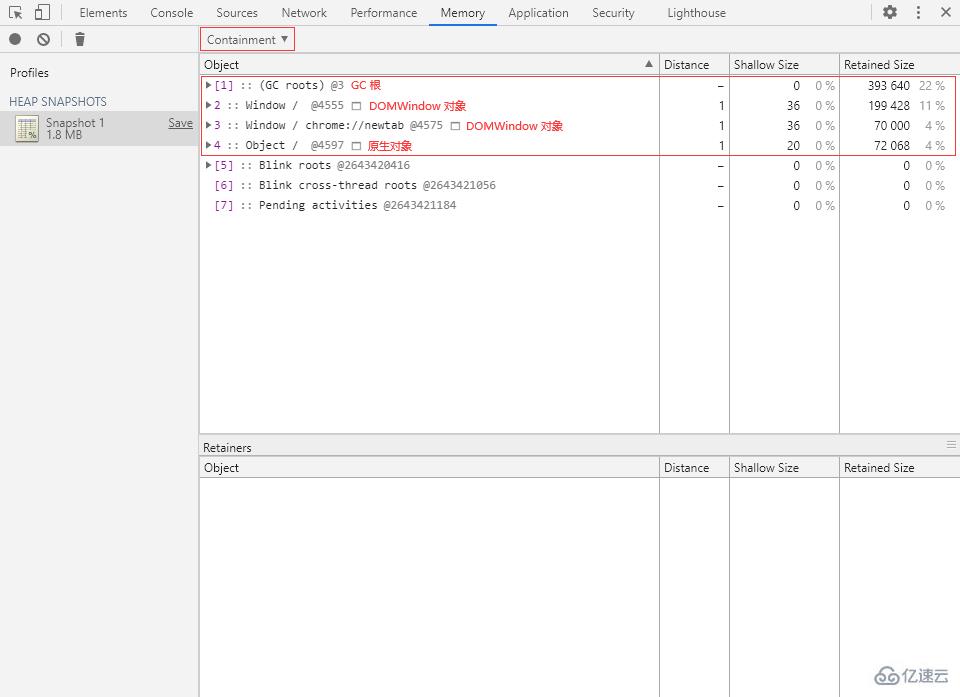
包含視圖中有以下幾種全局對象:
GC roots(GC 根)
GC roots 就是 JavaScript 虛擬機的垃圾回收中實際使用的根節點。
GC 根可以由 Built-in object maps(內置對象映射)、Symbol tables(符號表)、VM thread stacks(VM 線程堆棧)、Compilation caches(編譯緩存)、Handle scopes(句柄作用域)和 Global handles(全局句柄)等組成。
DOMWindow objects(DOMWindow 對象)
DOMWindow objects 指的是由宿主環境(瀏覽器)提供的頂級對象,也就是 JavaScript 代碼中的全局對象 window,每個標簽頁都有自己的 window 對象(即使是同一窗口)。
Native objects(原生對象)
Native objects 指的是那些基于 ECMAScript 標準實現的內置對象,包括 Object、Function、Array、String、Boolean、Number、Date、RegExp、Math 等對象。
? 實踐一下
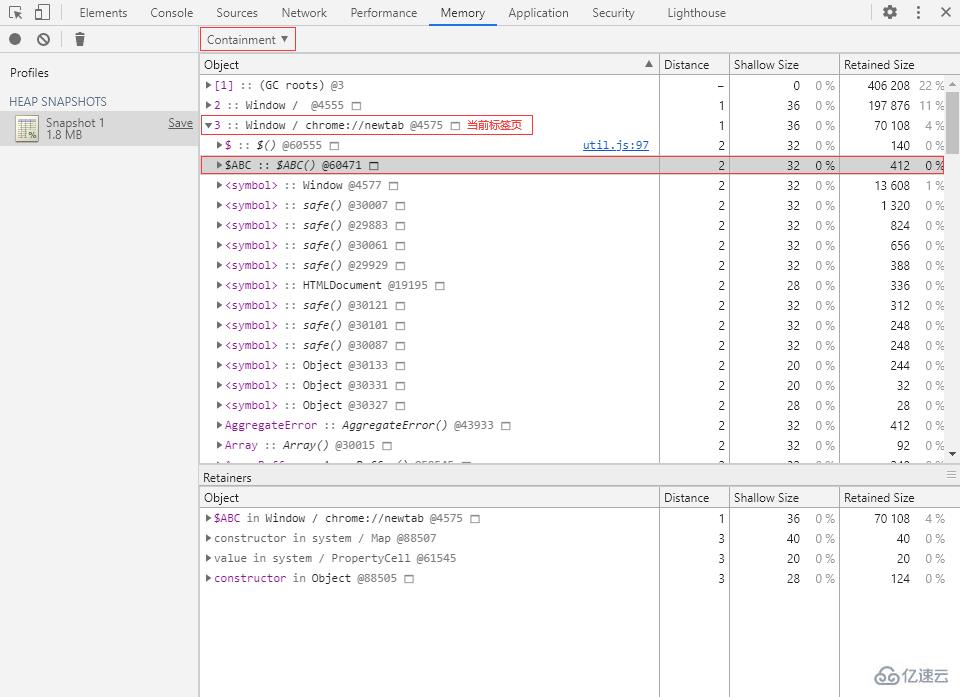
① 切換到 Console 面板,執行以下代碼來創建一個構造函數 $ABC:
構造函數命名前面加個 $ 是因為這樣排序的時候可以排在前面,方便找。
function $ABC() {
this.name = 'pp';
}② 切換到 Memory 面板,打一個堆快照,切換為 Containment 視圖:
在當前標簽頁的全局對象下就可以找到我們剛剛創建的構造函數 $ABC。
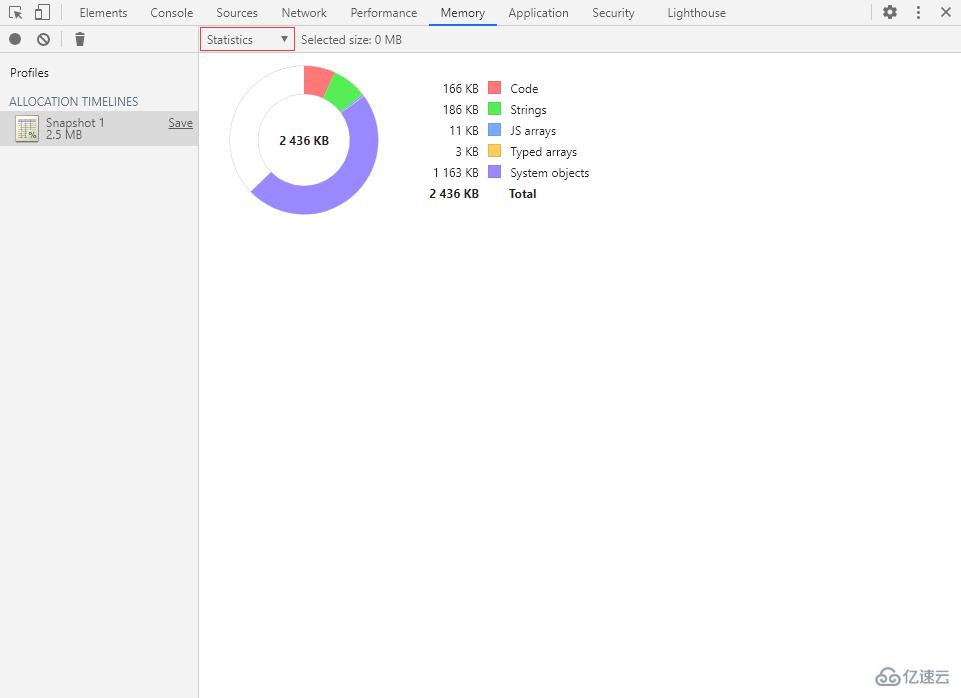
統計視圖可以很直觀地展示內存整體分配情況。
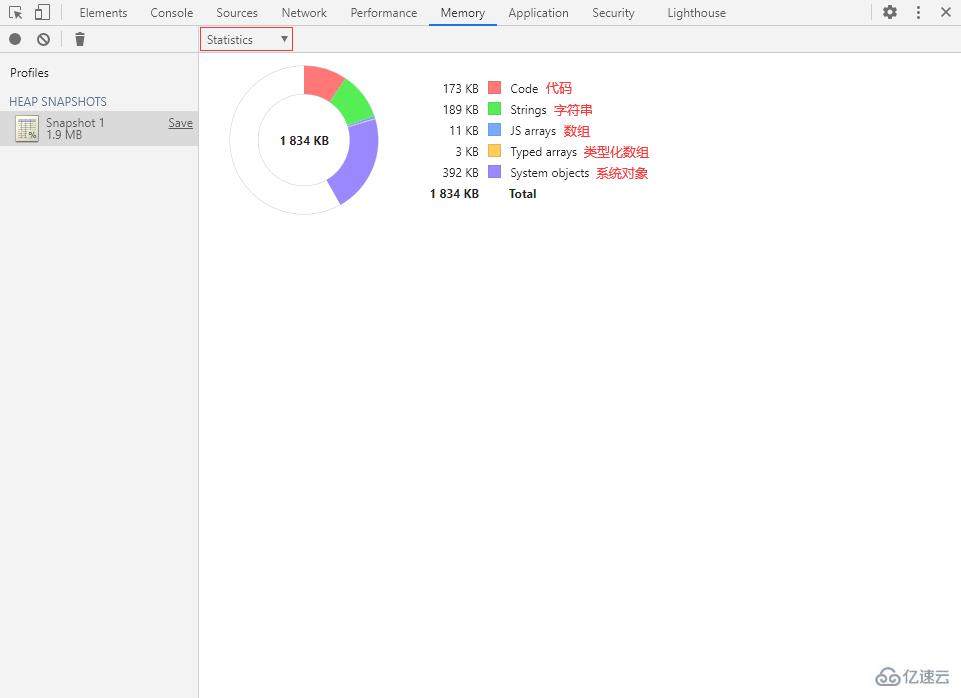
在該視圖里的空心餅圖中共有 6 種顏色,各含義分別為:
紅色:Code(代碼)
綠色:Strings(字符串)
藍色:JS arrays(數組)
橙色:Typed arrays(類型化數組)
紫色:System objects(系統對象)
白色:空閑內存
在一段時間內持續地記錄內存分配(約每 50 毫秒打一張堆快照),記錄完成后可以選擇查看任意時間段的內存分配詳情。
另外還可以勾選同時記錄分配堆棧(Allocation stacks),也就是記錄調用堆棧,不過這會產生額外的性能消耗。
? 如何開始
點擊頁面底部的 Start 按鈕或者左上角的 ? 按鈕即可開始記錄,記錄過程中點擊左上角的 ? 按鈕來結束記錄,片刻之后就會自動展示結果。
? 操作一下
① 打開 Memory 面板,開始記錄分配時間軸。
② 切換到 Console 面板,執行以下代碼:
代碼效果:每隔 1 秒鐘創建 100 個對象,共創建 1000 個對象。
console.log('測試開始');
let objects = [];
let handler = setInterval(() => {
// 每秒創建 100 個對象
for (let i = 0; i < 100; i++) {
const name = `n${objects.length}`;
const value = `v${objects.length}`;
objects.push({ [name]: value});
}
console.log(`對象數量:${objects.length}`);
// 達到 1000 個后停止
if (objects.length >= 1000) {
clearInterval(handler);
console.log('測試結束');
}
}, 1000);? 又是一個細節
不知道你有沒有發現,在上面的代碼中,我干了一件壞事。
在 for 循環創建對象時,會根據對象數組當前長度生成一個唯一的屬性名和屬性值。
這樣一來 V8 就無法對這些對象進行優化,方便我們進行測試。
另外,如果直接使用對象數組的長度作為屬性名會有驚喜~
③ 靜靜等待 10 秒鐘,控制臺會打印出“測試結束”。
④ 切換回 Memory 面板,停止記錄,片刻之后會自動進入結果頁面。
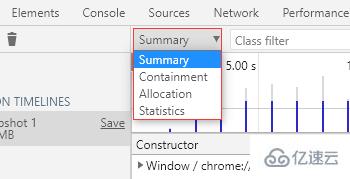
分配時間軸結果頁有 4 種視圖:
Summary:摘要視圖
Containment:包含視圖
Allocation:分配視圖
Statistics:統計視圖
默認顯示 Summary 視圖。
看起來和堆快照的摘要視圖很相似,主要是頁面上方多了一條橫向的時間軸(Timeline)。
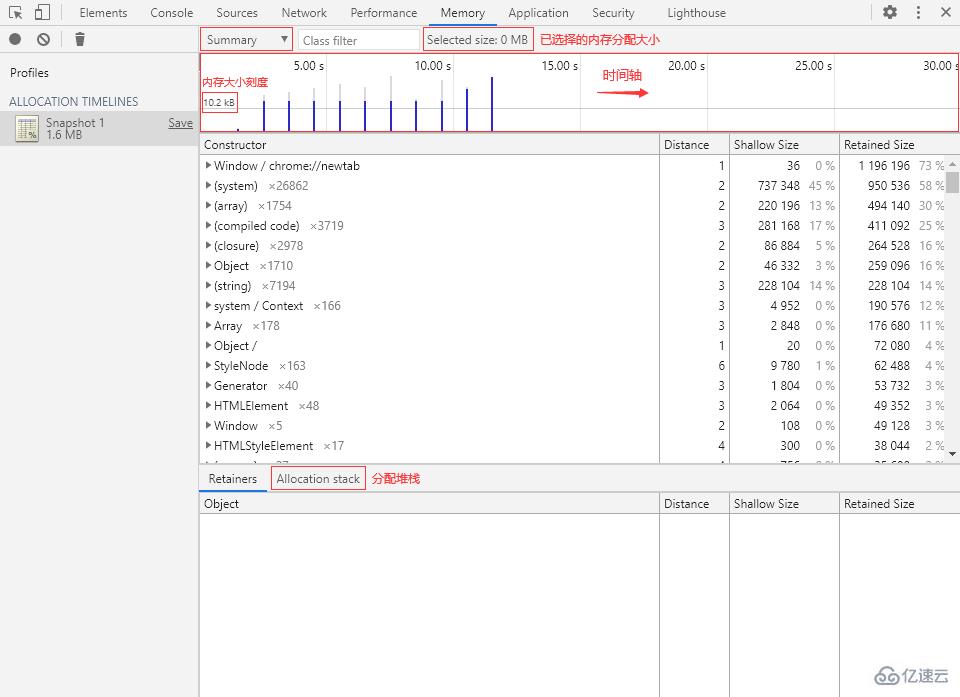
? 時間軸
時間軸中主要的 3 種線:
細橫線:內存分配大小刻度線
藍色豎線:表示內存在對應時刻被分配,最后仍然活躍
灰色豎線:表示內存在對應時刻被分配,但最后被回收
時間軸的幾個操作:
鼠標移動到時間軸內任意位置,點擊左鍵或長按左鍵并拖動即可選擇一段時間
鼠標拖動時間段框上方的方塊可以對已選擇的時間段進行調整
鼠標移到已選擇的時間段框內部,滑動滾輪可以調整時間范圍
鼠標移到已選擇的時間段框兩旁,滑動滾輪即可調整時間段
雙擊鼠標左鍵即可取消選擇

在時間軸中選擇要查看的時間段,即可得到該段時間的內存分配詳情。
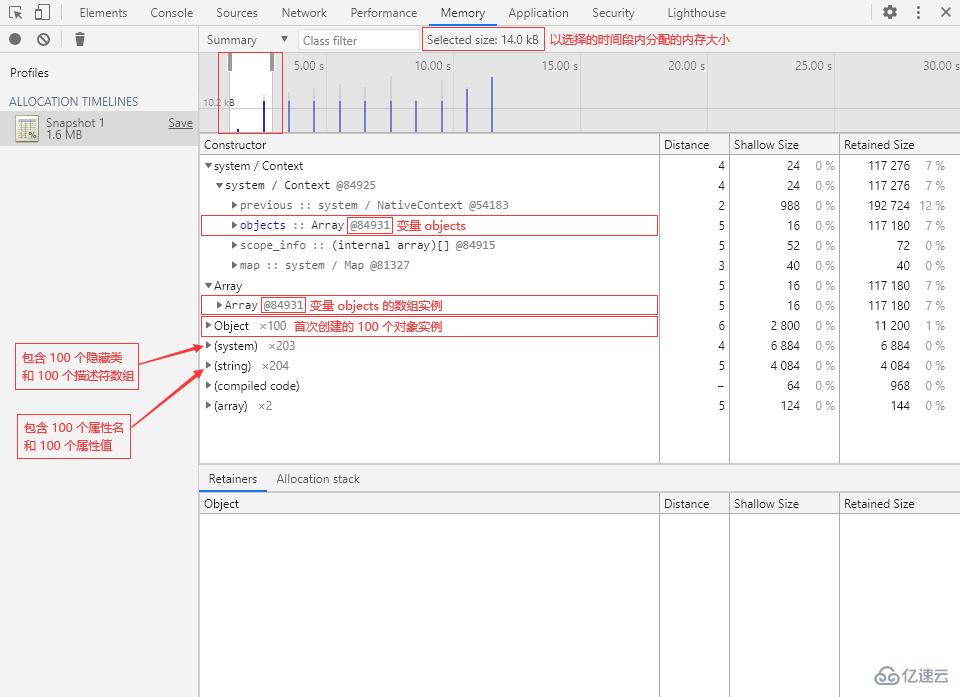
分配時間軸的包含視圖與堆快照的包含視圖是一樣的,這里就不再重復介紹了。
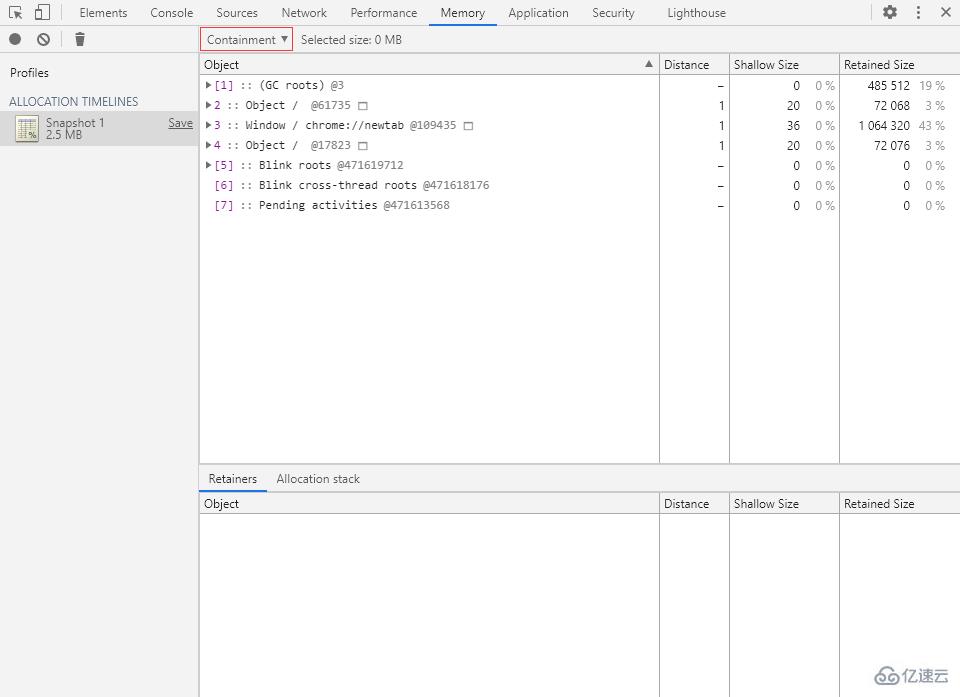
對不起各位,這玩意兒我也不知道有啥用…
打開就直接報錯,我:喵喵喵?
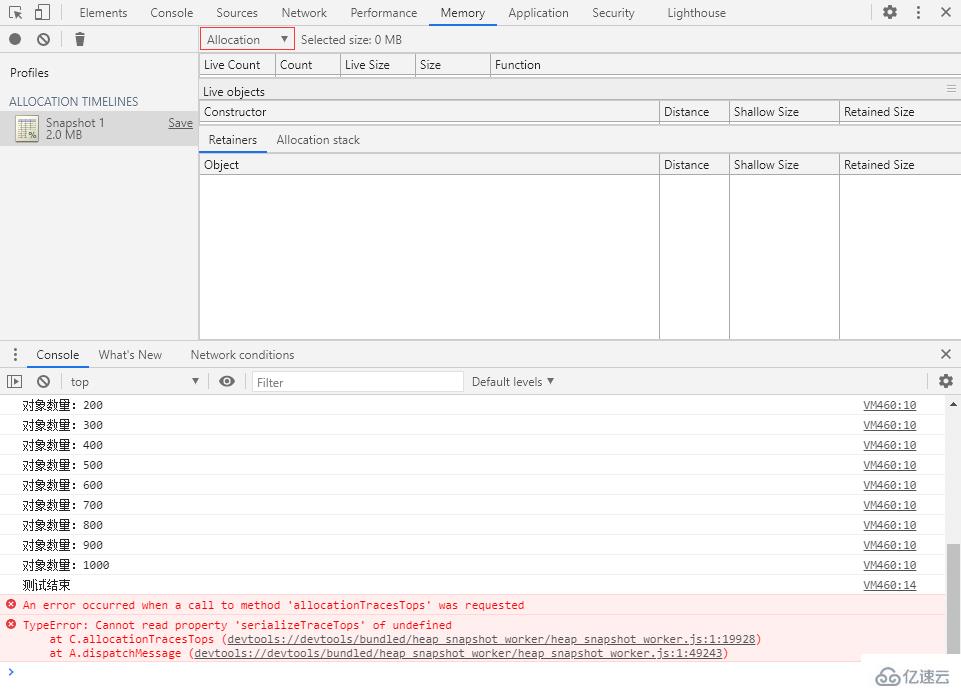
是不是因為沒人用這玩意兒,所以沒人發現有問題…
分配時間軸的統計視圖與堆快照的統計視圖也是一樣的,不再贅述。
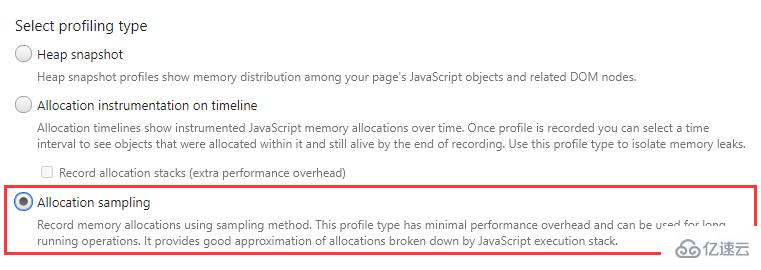
Memory 面板上的簡介:使用采樣方法記錄內存分配。這種分析方式的性能開銷最小,可以用于長時間的記錄。
好家伙,這個簡介有夠模糊,說了跟沒說似的,很有精神!
我在官方文檔里沒有找到任何關于分配采樣的介紹,Google 上也幾乎沒有與之有關的信息。所以以下內容僅為個人實踐得出的結果,如有不對的地方歡迎各位指出!
簡單來說,通過分配采樣我們可以很直觀地看到代碼中的每個函數(API)所分配的內存大小。
由于是采樣的方式,所以結果并非百分百準確,即使每次執行相同的操作也可能會有不同的結果,但是足以讓我們了解內存分配的大體情況。
? 如何開始
點擊頁面底部的 Start 按鈕或者左上角的 ? 按鈕即可開始記錄,記錄過程中點擊左上角的 ? 按鈕來結束記錄,片刻之后就會自動展示結果。
? 操作一下
① 打開 Memory 面板,開始記錄分配采樣。
② 切換到 Console 面板,執行以下代碼:
代碼看起來有點長,其實就是 4 個函數分別以不同的方式往數組里面添加對象。
// 普通單層調用
let array_a = [];
function aoo1() {
for (let i = 0; i < 10000; i++) {
array_a.push({ a: 'pp' });
}
}
aoo1();
// 兩層嵌套調用
let array_b = [];
function boo1() {
function boo2() {
for (let i = 0; i < 20000; i++) {
array_b.push({ b: 'pp' });
}
}
boo2();
}
boo1();
// 三層嵌套調用
let array_c = [];
function coo1() {
function coo2() {
function coo3() {
for (let i = 0; i < 30000; i++) {
array_c.push({ c: 'pp' });
}
}
coo3();
}
coo2();
}
coo1();
// 兩層嵌套多個調用
let array_d = [];
function doo1() {
function doo2_1() {
for (let i = 0; i < 20000; i++) {
array_d.push({ d: 'pp' });
}
}
doo2_1();
function doo2_2() {
for (let i = 0; i < 20000; i++) {
array_d.push({ d: 'pp' });
}
}
doo2_2();
}
doo1();③ 切換回 Memory 面板,停止記錄,片刻之后會自動進入結果頁面。
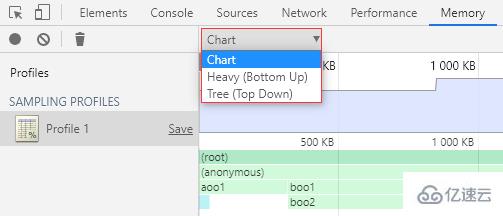
分配采樣結果頁有 3 種視圖可選:
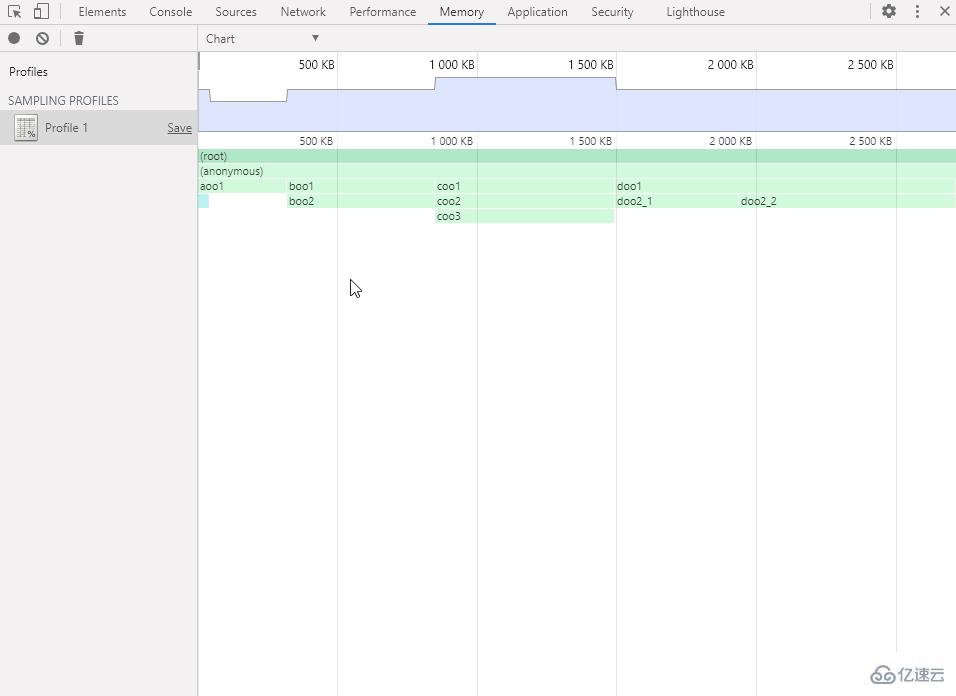
Chart:圖表視圖
Heavy (Bottom Up):扁平視圖(調用層級自下而上)
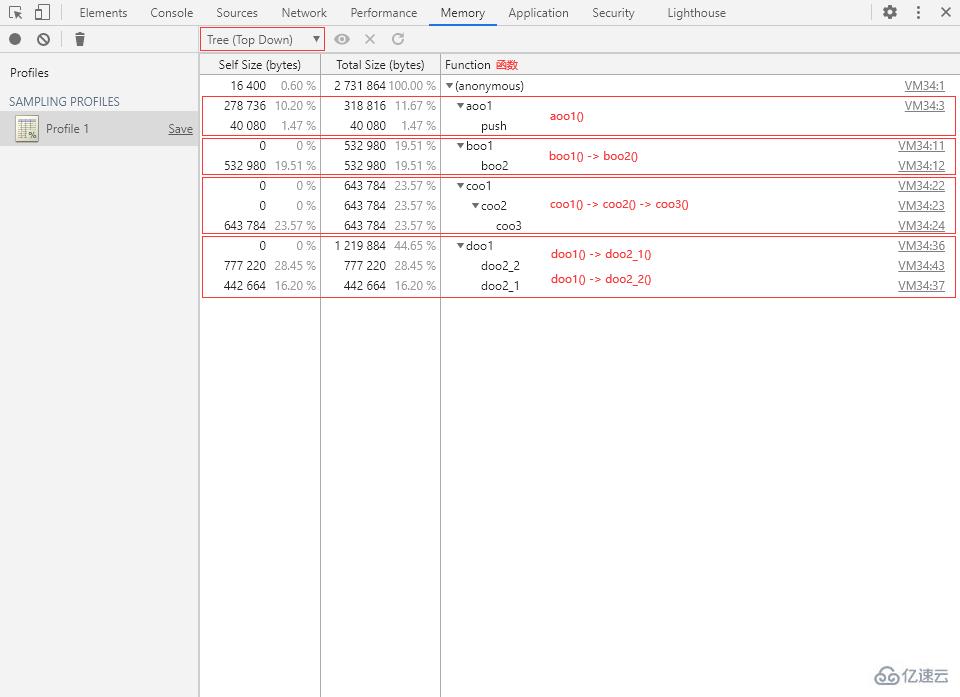
Tree (Top Down):樹狀視圖(調用層級自上而下)
這個 Heavy 我真的不知道該怎么翻譯,所以我就按照具體表現來命名了。
默認會顯示 Chart 視圖。
Chart 視圖以圖形化的表格形式展現各個函數的內存分配詳情,可以選擇精確到內存分配的不同階段(以內存分配的大小為軸)。
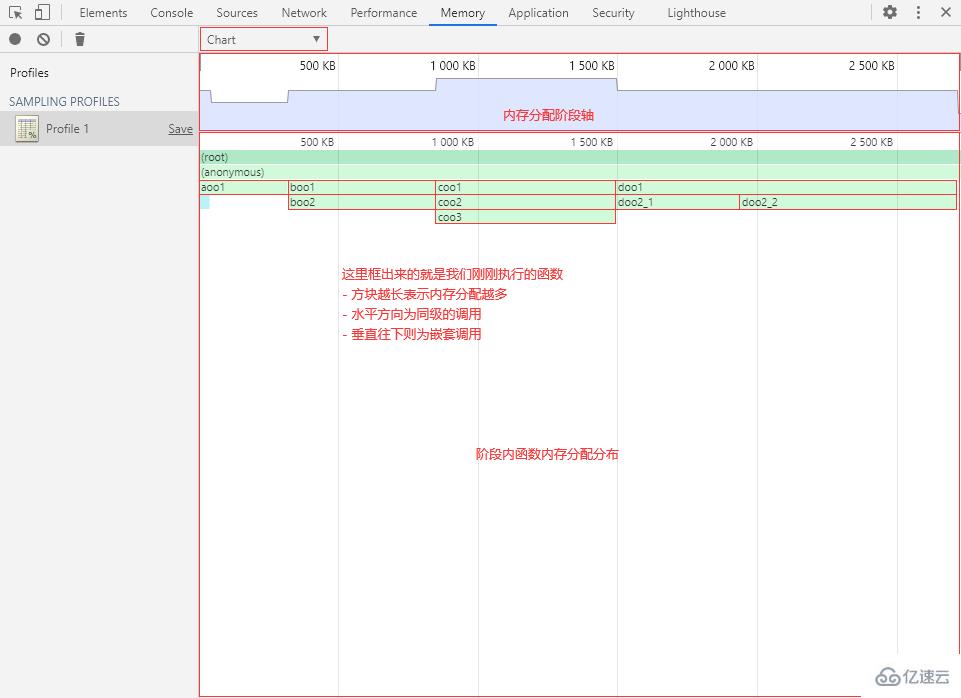
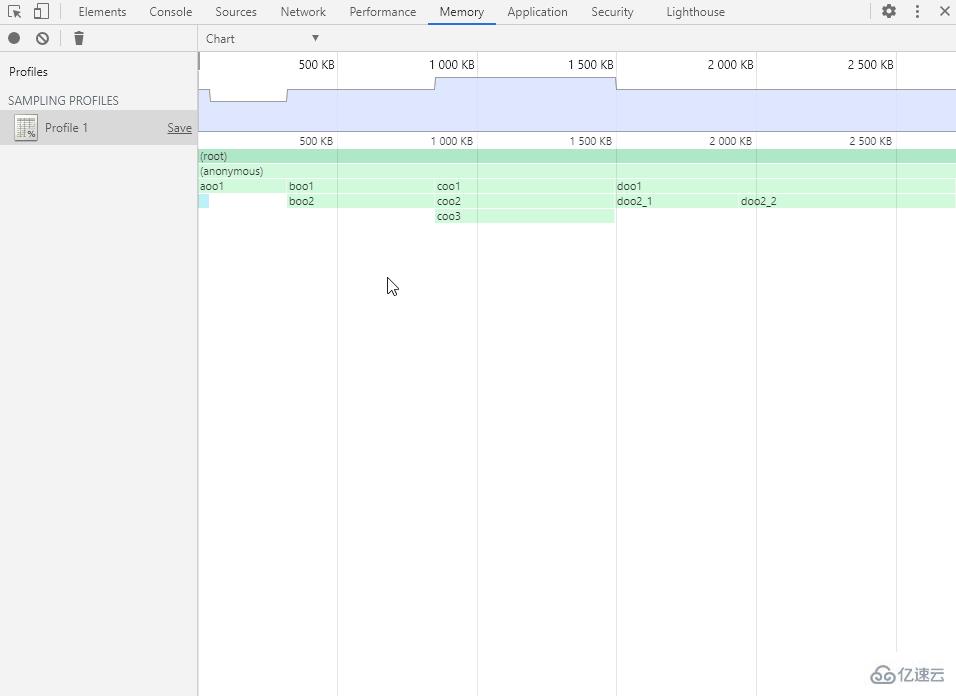
鼠標左鍵點擊、拖動和雙擊以操作內存分配階段軸(和時間軸一樣),選擇要查看的階段范圍。
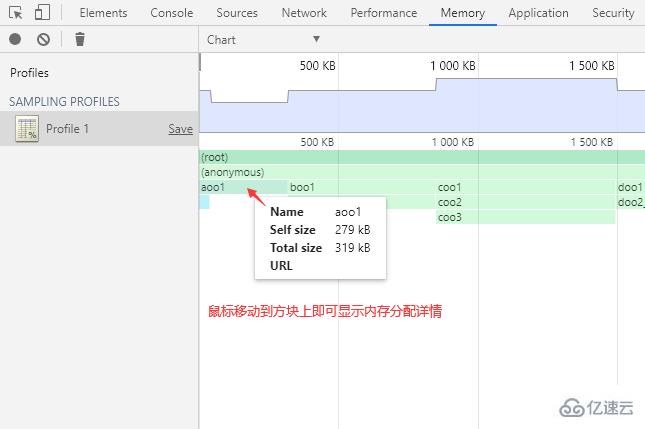
將鼠標移動到函數方塊上會顯示函數的內存分配詳情。
鼠標左鍵點擊函數方塊可以跳轉到相應代碼。
Heavy 視圖將函數調用層級壓平,函數將以獨立的個體形式展現。另外也可以展開調用層級,不過是自下而上的結構,也就是一個反向的函數調用過程。
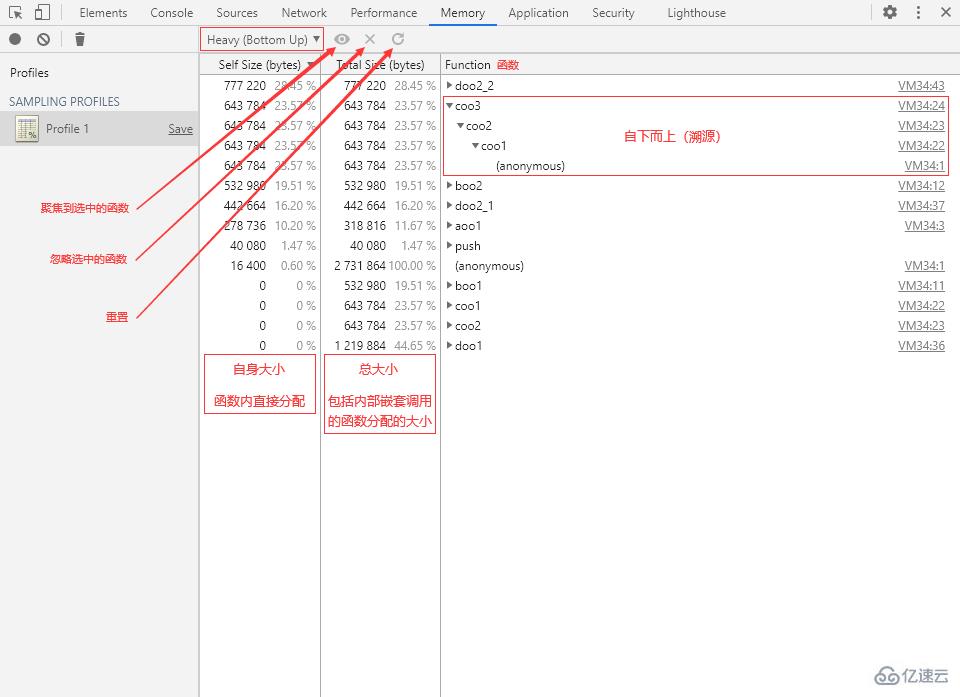
視圖中的兩種 Size(大小):
Self Size:自身大小,指的是在函數內部直接分配的內存空間大小。
Total Size:總大小,指的是函數總共分配的內存空間大小,也就是包括函數內部嵌套調用的其他函數所分配的大小。
Tree 視圖以樹形結構展現函數調用層級。我們可以從代碼執行的源頭開始自上而下逐層展開,呈現一個完整的正向的函數調用過程。
關于“javascript中內存指的是什么”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“javascript中內存指的是什么”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。