溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Java Valhalla Project項目代碼分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Oracle的Java語言架構師Brian Goetz在一次演講中說,Valhalla項目的主要動機之一是希望使Java語言和運行時適應現代硬件。當Java語言誕生時(大約25年前撰寫本文時),獲取內存和算術運算的成本大致相同。
如今,這種情況已經發生了變化,內存提取操作的成本是算術操作的200到1000倍。就語言設計而言,這意味著導致指針提取的間接操作會對整體性能產生不利影響。
由于應用程序中的大多數Java數據結構都是對象,因此我們可以將Java視為指針密集型語言(盡管我們通常不會直接看到或操作它們)。這種基于指針的對象實現用于啟用對象標識,對象標識本身用于語言特性,如多態性、可變性和鎖定。默認情況下,這些特性適用于每個對象,無論它們是否真的需要。
遵循導致指針的標識鏈和導致間接的指針鏈,間接存在性能缺陷,邏輯上的結論是刪除那些不需要它們的數據結構。這就是值類型value types發揮作用的地方。
值類型的概念是表示純數據聚合。這會刪除常規對象的功能。因此,我們有純數據,沒有身份。當然,這意味著我們也失去了使用對象標識可以實現的功能。因此,平等比較只能基于狀態進行。因此,我們不能使用表示多態性,也不能使用不可變或不可為空的對象。
由于我們不再有對象標識,我們可以放棄指針,改變值類型的一般內存布局,而不是對象。讓我們來比較一下類點和相應的值類型點之間的內存布局。
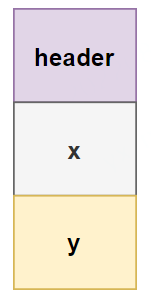
常規Point類的代碼和相應的內存布局為:
final class Point {
final int x;
final int y;
}
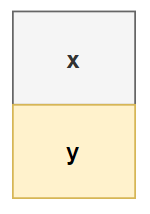
另一方面,值類型Point的代碼和相應的內存布局將是:
value class Point {
int x;
int y
}
這允許JVM將值類型展平為數組和對象,以及其他值類型。
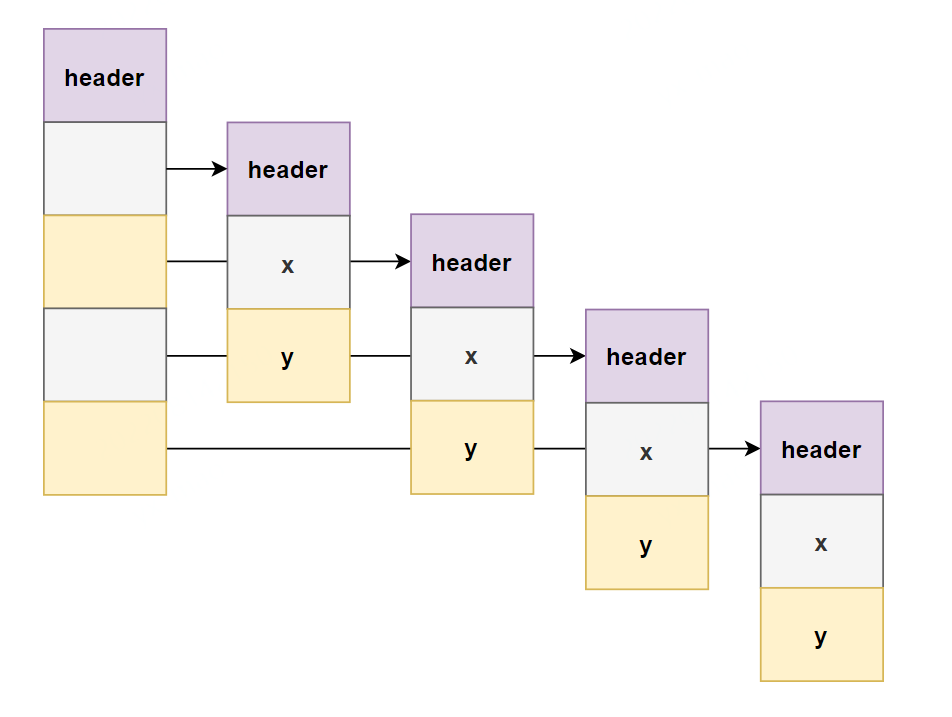
在下圖中,我們展示了在數組中使用Point類時間接的負面影響:
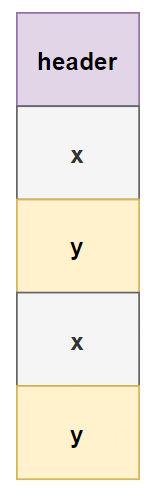
另一方面,這里我們看到值類型Point[]的相應內存結構:
它還使JVM能夠在棧上傳遞值類型,而不必在堆上分配它們。最后,這意味著我們得到的數據聚合具有類似于Java原語的運行時行為,如int或float。
但與原語不同,值類型可以有方法和字段。我們還可以實現接口并將其用作泛型類型。
因此,我們可以從兩個不同的角度來看值類型:
更快的對象
用戶定義原語
作為額外的錦上添花,我們可以使用值類型作為泛型類型,而無需裝箱。這直接將我們引向了另一個大型項目Valhalla的特性:專用泛型。
當我們想對語言原語進行泛化時,我們目前使用裝箱類型,例如整數表示Integer或浮點表示Float。這種裝箱創建了一個額外的間接層,從而首先破壞了使用原語提高性能的目的。
因此,我們在現有的框架和庫中看到了許多針對基元類型的專門化,如IntStream<T>或ToIntFunction<T>。這樣做是為了保持使用原語的性能提高。
因此,專門化泛型是為了消除這些“黑客”的需求。相反,Java語言努力為基本上所有東西啟用泛型類型:對象引用、原語、值類型,甚至可能是void。
“Java Valhalla Project項目代碼分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





