溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么用Python實現自動化處理Word文檔”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
使用Python實現Word文檔的自動化處理,包括批量生成Word文檔、在Word文檔中批量進行查找和替換、將Word文檔批量轉換成PDF等。
安裝openpyxl模塊
pip install openpyxl
安裝python-docx模塊
pip install python-docx
openpyxl模塊可以讀寫擴展名為.xlsx/.xlsm/.xltx/.xltm的Excel文件。
python-docx模塊可以讀寫擴展名為.docx的Word文檔,但不能處理擴展名為.doc的Word文檔。
import re
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT, WD_TABLE_ALIGNMENT
from openpyxl import load_workbook
from docx import Document
def info_update(doc, old_info, new_info):
"""
文檔內容替換
:param doc: Word模板文檔
:param old_info: 源文本
:param new_info: 新文本
:return:
"""
# 遍歷Word文檔中的所有段落
for para in doc.paragraphs:
# 遍歷每個段落中的run對象
for run in para.runs:
# 替換run對象的文本內容
# run.text = run.text.replace(r'《'+old_info+'》', new_info)
run.text = run.text.replace(old_info, new_info)
run.text = re.sub(r'[《》]', '', run.text)
# 遍歷Word文檔中的所有表格
for table in doc.tables:
# 遍歷表格中的所有行
for row in table.rows:
# 遍歷行中的所有單元格
for cell in row.cells:
# 替換單元格內容
cell.text = cell.text.replace('《' + old_info + '》', new_info)
# 設置表格中的內容居中顯示
# 計算表格的rows和cols的長度
rows = len(table.rows)
cols = len(table.columns)
# 循環將每一行,每一列都設置為居中
for r in range(rows):
for c in range(cols):
table.cell(r, c).vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER # 垂直居中
table.cell(r, c).paragraphs[0].paragraph_format.alignment = WD_TABLE_ALIGNMENT.CENTER # 水平居中
wb = load_workbook('學生成績表.xlsx') # 打開工作簿
ws = wb.active # 激活工作簿中的工作表
# 遍歷工作表的行,從第2行開始
for row in range(2, ws.max_row + 1):
doc = Document('成績通知書.docx') # 創建文檔對象
# 遍歷工作表的列
for col in range(1, ws.max_column + 1):
# 讀取當前列的第一行,即列標題,單元格的值轉換成字符串
old_info = str(ws.cell(row=1, column=col).value)
# 讀取當前列的數據,單元格的值需要轉換成字符串
new_info = str(ws.cell(row=row, column=col).value)
# 進行內容替換
info_update(doc, old_info, new_info)
student_name = str(ws.cell(row=row, column=1).value)
doc.save(f'scores\\成績單--致{student_name}.docx')測試文件:

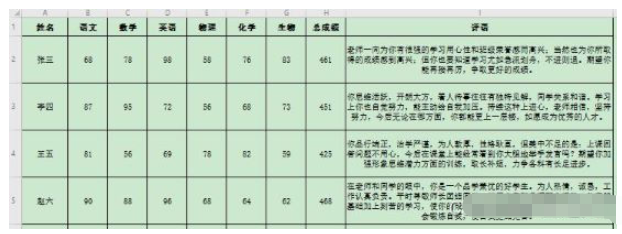
測試效果:
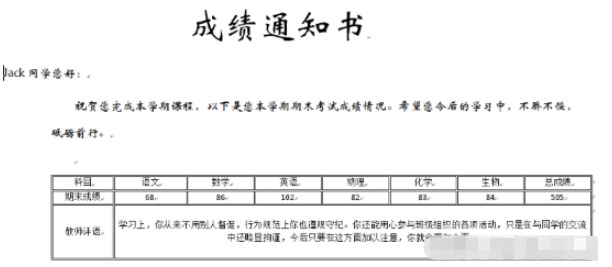
安裝pywin32模塊
pip install pywin32
from pathlib import Path
from win32com.client import constants, gencache
# 創建Path對象
# 路徑要使用絕對路徑
src_folder = Path(r'E:\pythonProject\python辦公自動化\第5章 自動化處理Word文檔\scores')
output_folder = Path(r'E:\pythonProject\python辦公自動化\第5章 自動化處理Word文檔\PDF')
# 判斷輸出目錄是否存在
if not output_folder.exists():
# 不存在則創建
output_folder.mkdir(parents=True)
file_list = list(src_folder.glob('*[.docx|.doc]')) # 獲得要轉換的Word文檔的路徑列表
word = gencache.EnsureDispatch('Word.Application') # 創建Word程序對象
# word = win32com.client.Dispatch('Word.Application')
for word_path in file_list:
# 生成轉換后的PDF文件的保存路徑
pdf_path = output_folder / word_path.with_suffix('.pdf').name # with_suffix()返回文件后綴已更改的新路徑
# 判斷pdf文件路徑是否已存在
if pdf_path.exists():
continue
else:
# 路徑需要是絕對路徑,否則會報錯
doc = word.Documents.Open(str(word_path), ReadOnly=1) # 打開Word文檔
# 設置導出格式為pdf
doc.ExportAsFixedFormat(str(pdf_path), constants.wdExportFormatPDF) # 將打開的Word文檔另存為PDF文件,保存到給定的路徑
doc.Close() # 關閉Word文檔
word.Quit() # 關閉Word程序窗口測試文件:
測試效果:
import win32com.client as win32
# 路徑要使用絕對路徑
input_file = r'E:\pythonProject\python辦公自動化\第5章 自動化處理Word文檔\勞動合同.docx'
output_file = r'E:\pythonProject\python辦公自動化\第5章 自動化處理Word文檔\勞動合同1.docx'
word = win32.gencache.EnsureDispatch('Word.Application') # 打開一個Word程序窗口
word.Visible = False # 設置窗口為隱藏狀態,即在后臺運行
cs = win32.constants # 導入Word開發接口提供的預設常量集合
doc = word.Documents.Open(input_file) # 打開要處理的Word文檔
# 設置要標記的關鍵詞列表
keyword_list = ['報酬', '保險', '培訓', '解除', '終止']
# 設置每個關鍵詞的突出顯示顏色
color_list = [cs.wdYellow, 14, cs.wdGreen, cs.wdRed, 13]
"""
值--顏色常量--含義:
1--wdBlack--黑色
2--wdBlue--藍色
3--wdTurquoise--青綠色
4--wdBrightGreen--鮮綠色
5--wdPink--粉紅色
6--wdRed--紅色
7--wdYellow--黃色
8--wdWhite--白色
9--wdDarkBlue--深藍色
10--wdTeal--青色
11--wdGreen--綠色
12--wdViolet--紫羅蘭色
13--wdDarkRed--深紅色
14--wdDarkYellow--深黃色
15--wdGray50--50%灰色
16--wdGray25--25%灰色
"""
for w, c in zip(keyword_list, color_list): # 使用zip()函數將關鍵詞列表和標記顏色列表中的元素一一配對分別賦給w和c
word.Options.DefaultHighlightColorIndex = c # 設置突出顯示的顏色
findObj = word.Selection.Find # 創建Find對象
findObj.ClearFormatting() # 清除查找文本的格式,表示查找文本時不限制文本格式
findObj.Text = w # 設置查找文本
findObj.Replacement.ClearFormatting() # 清除替換文本的格式設置
findObj.Replacement.Text = w # 將替換文本設置為與查找文本相同的值
findObj.Replacement.Font.Bold = True # 設置替換文本的格式為加粗
findObj.Replacement.Font.Italic = True # 設置替換文本的格式為斜體
findObj.Replacement.Font.Underline = cs.wdUnderlineDouble # 設置替換文本加雙下劃線
findObj.Replacement.Highlight = True # 設置替換時對文本做突出顯示
findObj.Execute(Replace=cs.wdReplaceAll) # 執行查找和替換,wdReplaceAll表示全部替換
# 將處理后的word文檔以新的文件名另存
doc.SaveAs(output_file)
# 關閉Word文檔
doc.Close()
# 關閉Word程序窗口
word.Quit()測試效果:

from pathlib import Path
import win32com.client as win32
# 創建Path對象
src_folder = Path(r'E:\pythonProject\python辦公自動化\第5章 自動化處理Word文檔\Files')
output_folder = Path(r'E:\pythonProject\python辦公自動化\第5章 自動化處理Word文檔\output_files')
# 判斷輸出文件夾是否存在
if not output_folder.exists():
# 創建文件夾
output_folder.mkdir(parents=True)
file_list = list(src_folder.glob('*.docx')) # 獲得給定文件的word文檔路徑列表
# 以替換前的關鍵詞作為建,以替換后的內容作為值,建立字典
replace_dict = {'確定': '確認', '訂立': '簽訂', '執行': '履行'}
word = win32.gencache.EnsureDispatch('Word.Application') # 打開Word程序窗口
word.Visible = False # 設置窗口隱藏
cs = win32.constants # 導入Word開發接口提供的預設常量集合
for file in file_list:
doc = word.Documents.Open(str(file)) # 打開Word文檔
print(file.name)
for old_txt, new_txt in replace_dict.items():
findObj = word.Selection.Find # 創建Find對象
findObj.ClearFormatting() # 清除查找文本的格式,表示查找文本時不限制文本格式
findObj.Text = old_txt # 設置查找文本
findObj.Replacement.ClearFormatting() # 清除替換文本的格式設置
findObj.Replacement.Text = new_txt # 設置替換文本
# 判斷Find對象的Execute()函數在文檔中是否找到關鍵詞
if findObj.Execute(Replace=cs.wdReplaceAll): # 執行查找和替換,wdReplaceAll表示全部替換
print(f'{old_txt}-->{new_txt}')
new_file = output_folder / file.name # 生成輸出文件的路徑
doc.SaveAs(str(new_file)) # # 將處理后的word文檔以新的文件名另存
doc.Close() # 關閉Word文檔
word.Quit() # 關閉Word程序窗口測試效果:


“怎么用Python實現自動化處理Word文檔”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





