溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“MySQL日志之redo log和undo log的知識點有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

REDO LOG稱為重做日志 ,當MySQL服務器意外崩潰或者宕機后,保證已經提交的事務持久化到磁盤中(持久性)。
InnoDB是以頁為單位去操作記錄的,增刪改查都會加載整個頁到buffer pool中(磁盤->內存),事務中的修改操作并不是直接修改磁盤中的數據,而是先修改內存中buffer pool中的數據,后臺線程每隔一段時間再異步刷新到磁盤中。
buffer pool:可存放索引、數據,可加速讀寫,直接在內存中操作數據頁,有專門的線程去把buffer pool中的臟頁寫入磁盤。
為什么不直接修改磁盤中的數據?
因為直接修改磁盤數據的話,它是隨機IO,修改的數據分布在磁盤中不同的位置,需要來回的查找,所以命中率低,消耗大,而且一個小小的修改就不得不將整個頁刷新到磁盤,利用率低;
與之相對的是順序IO,磁盤的數據分布在磁盤的一塊,所以省去了查找的過程,節省尋道時間。
使用后臺線程以一定的頻率去刷新磁盤可以降低隨機IO的頻率,增加吞吐量,這是使用buffer pool的根本原因。
修改內存再異步同步到磁盤的問題:
因為buffer pool是在內存中的區域,系統意外崩潰的話數據有可能會丟失,有些臟數據可能會來不及刷新到磁盤,事務的持久性得不到保證。因此,引入了redo log。修改數據時,額外記錄一次日志,內容是xx頁xx偏移量發生了xx變化,當系統崩潰時可以根據日志內容進行恢復。
寫日志和直接刷新磁盤的區別是:寫日志是追加寫入,順序IO,速度更快,且寫入的內容相對更小
redo log由兩部分組成:
redo log buffer(內存層面,默認16M,通過innodb_log_buffer_size參數可修改)
redo log file(持久化的,磁盤層面)
修改操作大致過程:
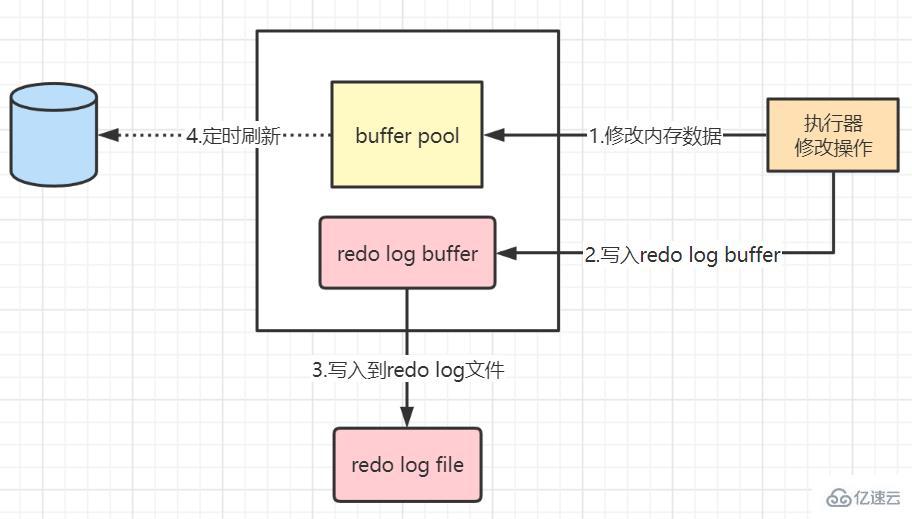
第1步:先將原始數據從磁盤中讀入內存中來,修改數據的內存拷貝,產生臟數據
第2步:生成一條重做日志并寫入redo log buffer,記錄的是數據被修改后的值
第3步:默認在事務提交后將redo log buffer中的內容刷新到redo log file,對redo log file采用追加寫的方式
第4步:定期將內存中修改的數據刷新到磁盤中(這里說的是那些還沒及時被后臺線程刷盤的臟數據)
通常所說的Write-Ahead Log(預先日志持久化)指的是在持久化一個數據頁之前,先將內存中相應的日志頁持久化。
redo log的好處:
減少了磁盤刷新頻率
redo log占用空間小
redo log寫入速度快
redo log一定能保證事務的持久性嗎?
不一定,這要根據redo log的刷盤策略決定,因為redo log buffer同樣是在內存中,如果提交事務之后,redo log buffer還沒來得及將數據刷新到redo log file進行持久化,此時發生宕機照樣會丟失數據。如何解決?刷盤策略。
InnoDB中給出了innodb_flush_log_at_trx_commit參數控制redo log buffer刷新到redo log file時的三種策略:
值為0:開啟一個后臺線程,每1s刷新一次到磁盤中,提交事務時就不需要進行刷新了
值為1:commit時再進行同步刷新(默認值),真正保證數據的持久性
值為2:commit的時候,只是刷新進os的內核緩沖區,具體的刷盤時機不確定
值為0的情況:
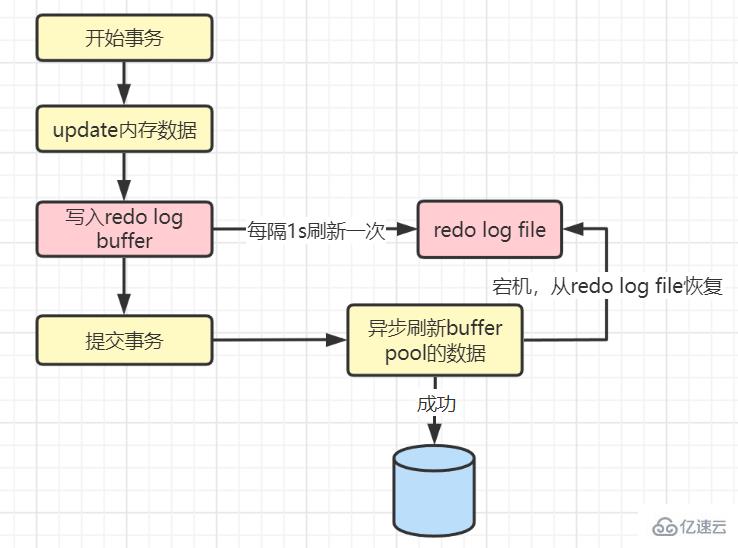
因為有1s的間隔,所以最壞情況下會丟失1秒的數據。
值為1的情況:
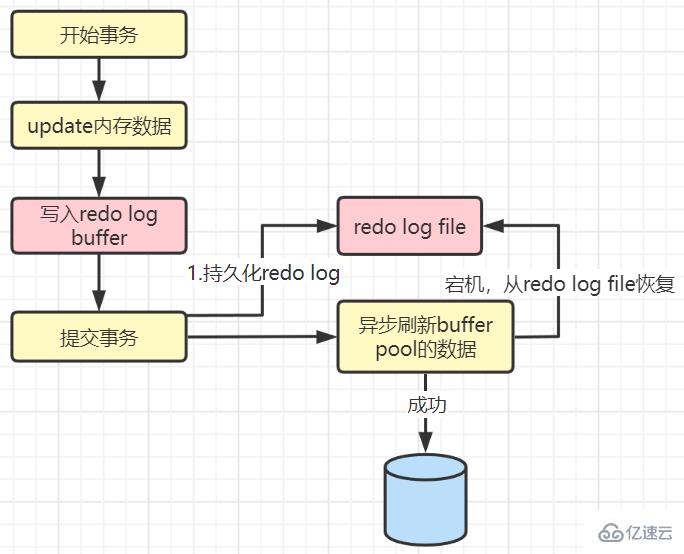
commit時需要先主動刷新redo log buffer到redo log file,如果中途宕機了,事務也就失敗了,不會有任何損失,真正能保證事務的持久性。但是效率最差。
值為2的情況:是根據os決定。
可以調整為0或2提高事務的性能,但是喪失了ACID特性
innodb_log_group_home_dir:指定 redo log文件組所在的路徑,默認值為 ./ ,表示在數據庫的數據目錄下。MySQL的默認數據目錄下默認有兩個名為ib_logfile0和ib_logfile1的文件,log buffer中的日志默認情況下就是刷新到這兩個磁盤文件中。
innodb_log_files_in_group:指明redo log file的個數,命名方式如:ib_logfile0,iblogfile1... iblogfilen。默認2個,最大100個。
innodb_log_file_size:單個 redo log 文件設置大小,默認值為 48M 。
undo log用于保證事務的原子性和一致性。作用有兩個:①提供回滾操作 ②多版本控制MVVC
回滾操作
前面redo log中說過,后臺線程會不定時的去刷新buffer pool中的數據到磁盤,但是如果該事務執行期間出現各種錯誤(宕機)或者執行rollback語句,那么前面刷進去的操作都是需要回滾的,保證原子性,undo log就是提供事務回滾的。
MVVC
當讀取的某一行被其他事務鎖定時,它可以從undo log中分析出該行記錄以前的數據版本是怎樣的,從而讓用戶能夠讀取到當前事務操作之前的數據——快照讀。
快照讀:SQL讀取的數據是歷史版本,不用加鎖,普通的SELECT就是快照讀。
undo log的組成部分:
當insert記錄的時候,必須將該記錄的主鍵值記錄下來,這樣才可以回滾時刪除該數據。
當update記錄的時候,必須將修改的舊值全部記錄下來,回滾時更新為舊值即可。
當delete的時候,必須將所有的記錄都記錄下來,回滾時再重新插入該內容的記錄。
select操作不會產生undo log
在InnoDB存儲引擎中,undo log使用rollback segment回滾段進行存儲,每隔回滾段包含了1024個undo log segment。 MySQL5.5之后,一共有128個回滾段。即總共可以記錄128 * 1024個undo操作。
每個事務只會使用一個回滾段,一個回滾段在同一時刻可能會服務于多個事務。
事務提交后不能立即刪除該undo log,可能有些事務會想要讀取之前的數據版本(快照讀)。所以事務提交時將undo log放入一個鏈表中,稱為版本鏈,undo log的刪除與否由一個稱為purge的線程判斷。
undo log分為:
insert undo log
因為insert操作的記錄,只對事務本身可見,對其他事務不可見(這是事務隔離性的要求),故該undo log可以在事務提交后直接刪除。不需要進行purge操作。
update undo log
update undo log記錄的是對delete和update操作產生的undo log。該undo log可能需要提供MVCC機制,因此不能在事務提交時就進行刪除。提交時放入undo log鏈表,等待purge線程進行最后的刪除。
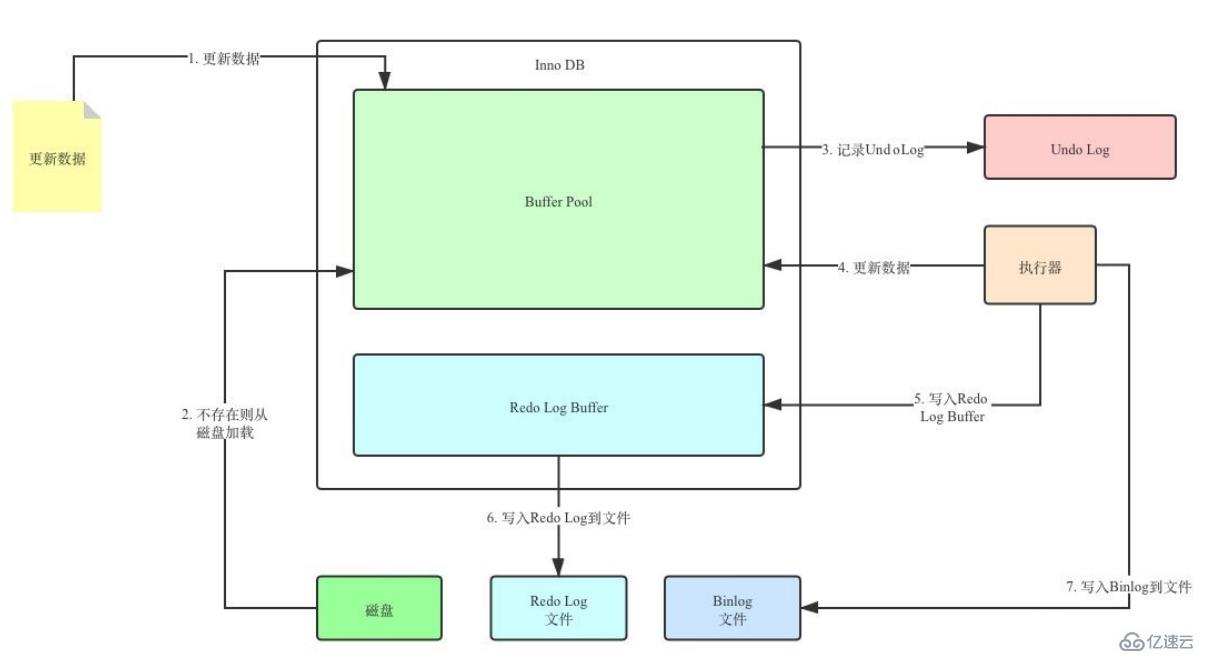
假設有2個數值,分別為A=1和B=2,然后某個事務將A修改為3,B修改為4,修改過程可簡化為:
1.begin
2.記錄A=1到undo log
3.update A=3
4.記錄A=3到redo log
5.記錄B=2到undo log
6.update B=4
7.記錄B=4到redo log
8.將redo log刷新到磁盤
9.commit
在1-8步驟的任意一步系統宕機,事務未提交,該事務就不會對磁盤上的數據做任何影響。
如果在8-9之間宕機,恢復之后可以選擇回滾,也可以選擇繼續完成事務提交,因為此時redo log已經持久化。
若在9之后系統宕機,內存映射中變更的數據還來不及刷回磁盤,那么系統恢復之后,可以根據redo log把數據刷回磁盤。
對于InnoDB引擎來說,每個行記錄除了記錄本身的數據之外,還有幾個隱藏的列:
DB_ROW_ID∶記錄的主鍵id。
DB_TRX_ID:事務ID,當對某條記錄發生修改時,就會將這個事務的Id記錄其中。
DB_ROLL_PTR︰回滾指針,版本鏈中的指針。

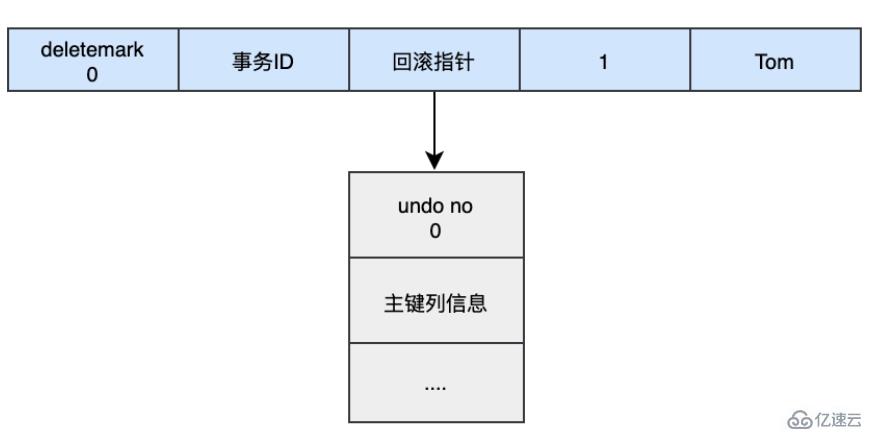
當我們執行INSERT時:
begin;
INSERT INTO user (name) VALUES ('tom');插入的數據都會生成一條insert undo log,并且數據的回滾指針會指向它。undo log會記錄undo log的序號、插入主鍵的列和值...,那么在進行rollback的時候,通過主鍵直接把對應的數據刪除即可。
當我們執行UPDATE時:
對于更新的操作會產生update undo log,并且會分更新主鍵的和不更新主鍵的,假設現在執行:
UPDATE user SET name='Sun' WHERE id=1;
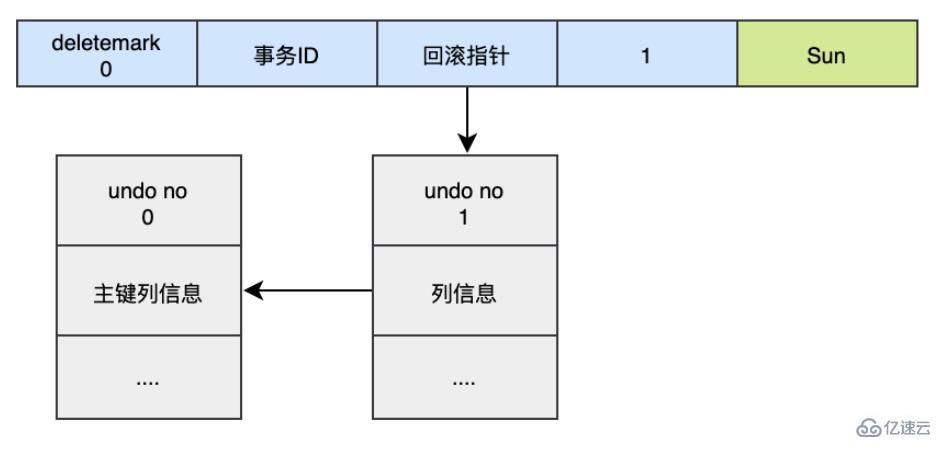
這時會把新的undo log記錄加入到版本鏈中,它的undo no是1,并且新的undo log的回滾指針會指向老的undo log (undo no=0)。
假設現在執行:
UPDATE user SET id=2 WHERE id=1;
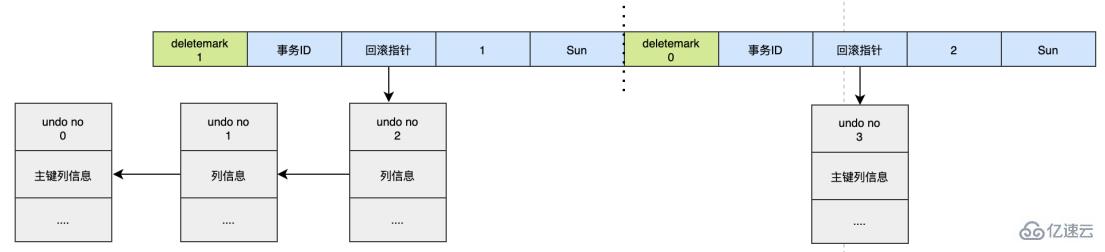
對于更新主鍵的操作,會先把原來的數據deletemark標識打開,這時并沒有真正的刪除數據,真正的刪除會交給清理線程去判斷,然后在后面插入一條新的數據,新的數據也會產生undo log,并且undo log的序號會遞增。
可以發現每次對數據的變更都會產生一個undo log,當一條記錄被變更多次時,那么就會產生多條undo log,undo log記錄的是變更前的日志,并且每個undo log的序號是遞增的,那么當要回滾的時候,按照序號依次向前推,就可以找到我們的原始數據了。
以上面的例子來說,假設執行rollback,那么對應的流程應該是這樣:
1. 通過undo no=3的日志把id=2的數據刪除
2. 通過undo no=2的日志把id=1的數據的deletemark還原成0
3. 通過undo no=1的日志把id=1的數據的name還原成Tom
4. 通過undo no=0的日志把id=1的數據刪除
MySQL MVVC多版本并發控制
binlog即binary log,二進制日志文件,也叫作變更日志(update log)。它記錄了數據庫所有執行的更新語句。
binlog主要應用場景:
數據恢復:如果MySQL意外停止,可以通過該日志進行恢復、備份
數據復制:master把它的二進制日志傳遞給slaves來達到master-slave數據的一致性
show variables like '%log_bin%';
查看bin log日志:
mysqlbinlog -v "/var/lib/mysql/binlog/xxx.000002"
使用日志恢復數據:
mysqlbinlog [option] filename|mysql –uuser -ppass;
刪除二進制日志:
PURGE {MASTER | BINARY} LOGS TO ‘指定日志文件名'
PURGE {MASTER | BINARY} LOGS BEFORE ‘指定日期'事務執行過程中,先把日志寫到bin log cache ,事務提交的時候,再把binlog cache寫到binlog文件中。因為一個事務的binlog不能被拆開,無論這個事務多大,也要確保一次性寫入,所以系統會給每個線程分配一個塊內存作為binlog cache。
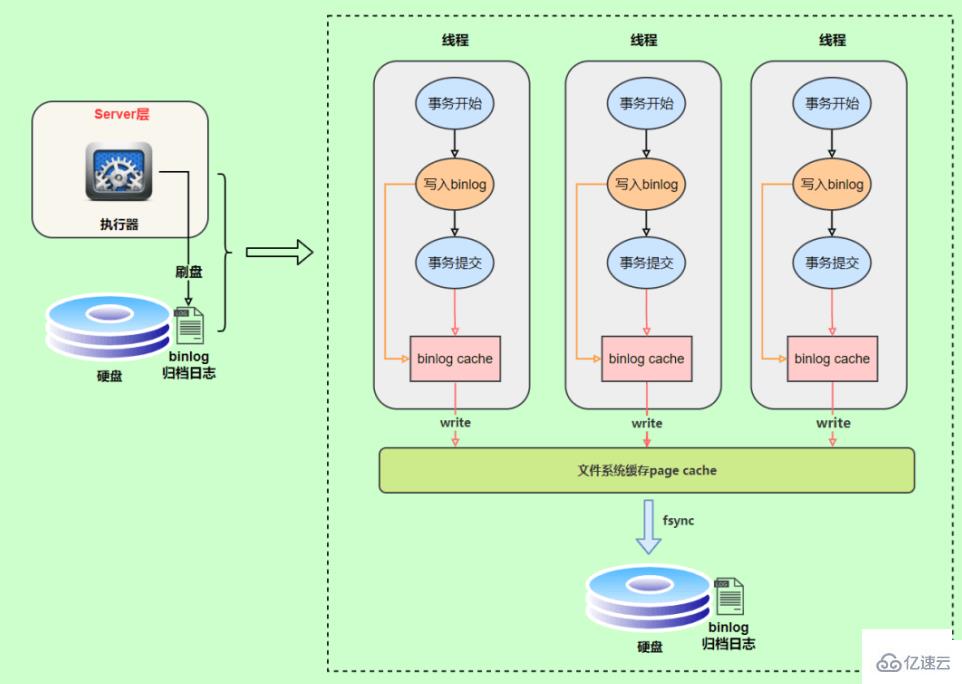
redo log是物理日志,記錄內容是“在xx數據頁做了xx修改”,屬于InnoDB存儲引擎層產生的。
而binlog是邏輯日志,記錄內容是語句的原始邏輯,類似于給ID=2這一行的c字段加1,屬于服務層。
兩個側重點也不同, redo log讓InnoDB有了崩潰恢復的能力,binlog保證了MySQL集群架構的數據一致性。
在執行更新語句過程,會記錄redo log與binlog兩塊日志,以基本的事務為單位,redo log在事務執行過程中可以不斷寫入,而binlog只有在提交事務時才寫入,所以redo log與binlog的寫入時機不一樣。

redo log與binlog兩份日志之間的邏輯不一致,會出現什么問題?
以update語句為例,假設id=2的記錄,字段c值是0,把字段c值更新成1,SQL語句為update T set c=1 where id=2。
假設執行過程中寫完redo log日志后,binlog日志寫期間發生了異常,會出現什么情況呢?
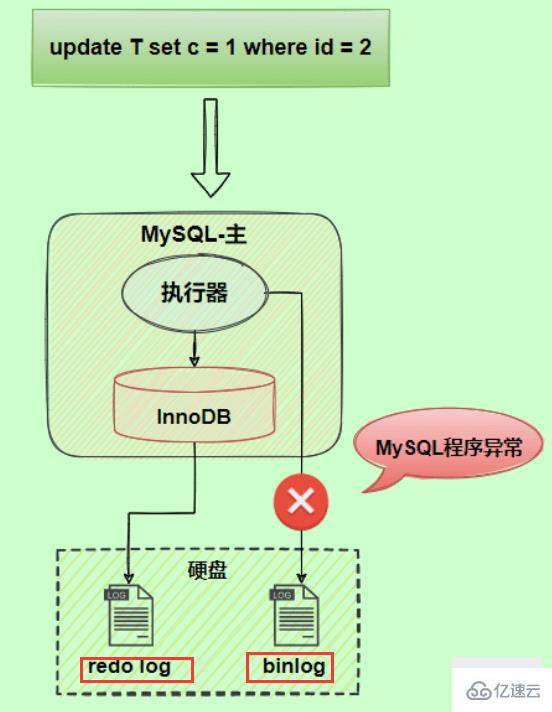
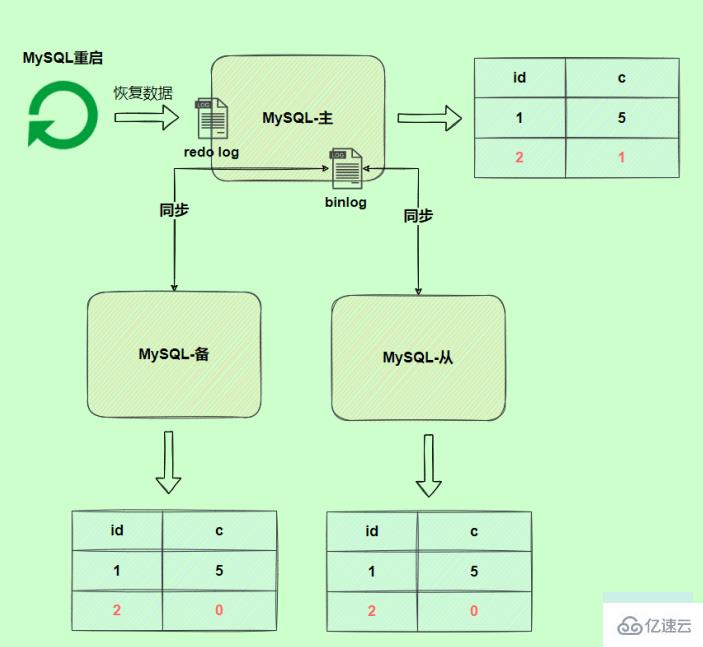
由于binlog沒寫完就異常,這時候binlog里面沒有對應的修改記錄。因此,之后用binlog日志恢復數據或者slave讀取master的binlog時,就會少這一次更新,恢復出來的這一行c值是0,而原庫因為redo log日志恢復,這一行c值是1,最終數據不一致。
為了解決兩份日志之間的邏輯一致問題,InnoDB存儲引擎使用兩階段提交方案。將redo log拆成了兩個步驟prepare和commit,這就是兩階段提交。
讓redo log和bin log最終的提交綁定到一起,前面說過的,事務commit時默認需要讓redo log先同步完才算commit成功,所以如果綁定到一起的話,bin log也具有該特性了,就保證了數據不會丟失。
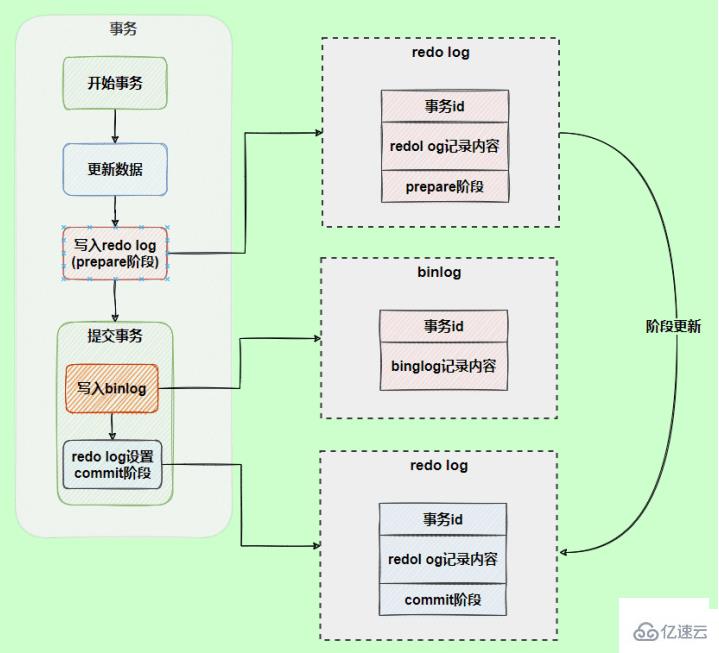
使用兩階段提交后,寫入binlog時發生異常也不會有影響,因為MySQL根據redo log日志恢復數據時發現redo log還處于prepare階段,并且沒有對應binlog日志,就會提交失敗,回滾數據。
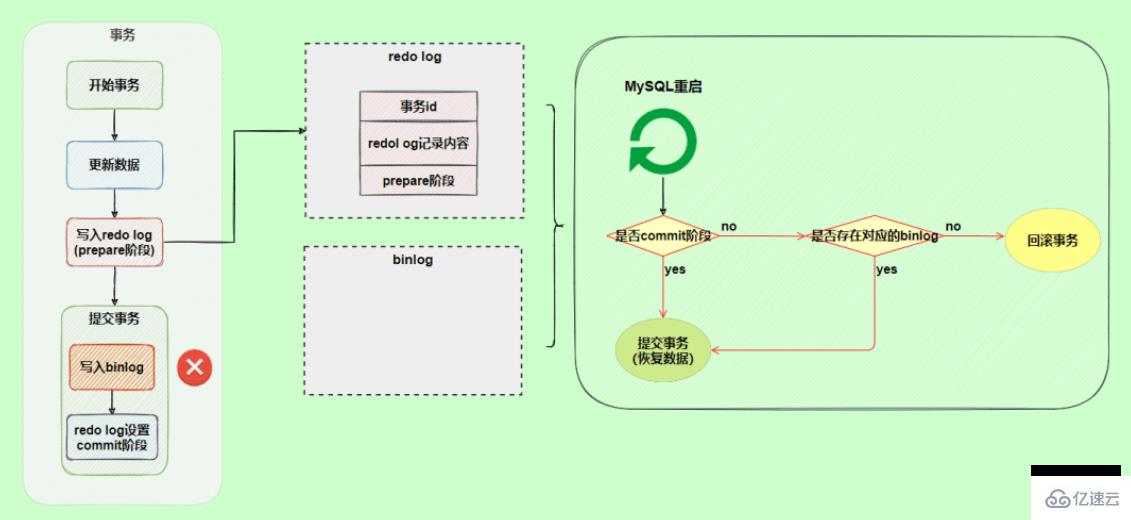
另一個場景,redo log的commit階段發生異常,那會不會回滾事務呢?
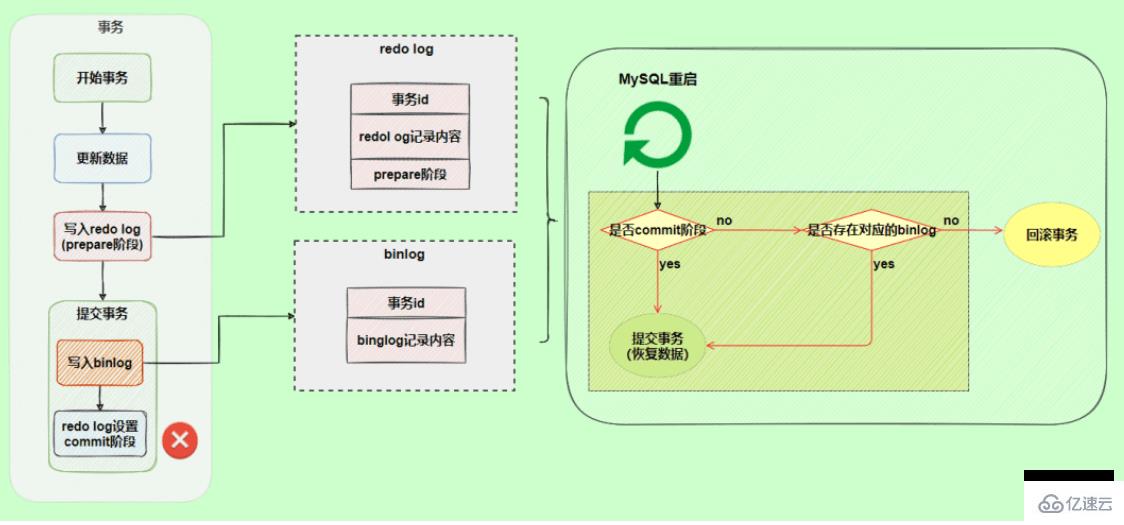
并不會回滾事務,它會執行上圖框住的邏輯,雖然redo log是處于prepare階段,但是能通過事務id找到對應的binlog日志,所以MySQL認為是完整的,就會提交事務恢復數據。
“MySQL日志之redo log和undo log的知識點有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





