溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python操作pdf pdfplumber讀取PDF寫入Exce”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python操作pdf pdfplumber讀取PDF寫入Exce”吧!
安裝pdfplumber:
pip install pdfplumber
pdfplumber.PDF類
pdfplumber.PDF類表示單個PDF ,并具有兩個主要屬性:
| 屬性 | 說明 |
|---|---|
| pdf.metadata | 從PDF的Info中獲取元數據鍵/值對字典。通常包括"CreationDate,“ModDater","Producer"等 |
| pdf.pages | 返回一個包含pdfplumber. Page實例的列表,每一一個實例代表PDF每一頁的信息 |
pdfplumber.Page類
pdfplumber.Page類常用屬性
| 屬性page_ number | 說明 |
|---|---|
| .page_ number | 順序頁碼,從1第一頁開始,從第二頁開始2 ,依此類推 |
| .width | 頁面的寬度 |
| .height | 頁面的高度 |
| .objects/ . chars/ .lines/ .rects/ . curves/ .figures/ . images | 這些屬性中的每一個都是一 個列表, 每個列表包含一個字典 ,用于嵌入頁面上的每個此類對象,有關詳細信息,請參閱下面的“對象”。 |
常用方法:
| 方法名 | 說明 |
|---|---|
| .extract_ text( ) | 用來提頁面中的文本,將頁面的所有字符對象整理為的那個字符串 |
| .extract_ words( ) | 返回的是所有的單詞及其相關信息 |
| . extract_ tables() | 提取頁面的表格 |
| .to_ _image() | 用于可視化調試時,返回Pagelmage類的一個實例 |
| .close() | 默認情況下, Page對象緩存其布局和對象信息,以避免重新處理它, 但是在解析大型PDF時,這些緩存的屬性可能需要大量內存。您可以使用此方法刷新緩存并釋放內存。 |
PDF是Portable Document Format的縮寫,這類文件通常使用.pdf作為其擴展名。在日常開發工作中,最容易遇到的就是從PDF中讀取文本內容以及用已有的內容生成PDF文檔這兩個任務。
1.讀取pdf文檔信息
2.輸出總頁數
3.讀取第一頁寬度、高度等信息
4.讀取文本第一頁
加載pdf:
pdfplumber.open( "路徑/文件名. pdf".pas sword="test "laparams={ "line_ _overlap'”0.7 })
password : 要加載受密碼保護的PDF ,請傳遞password關鍵字參數
laparams :要將布局分析參數設置為pdfminer. six的布局引擎,請傳遞laparams關鍵字參數
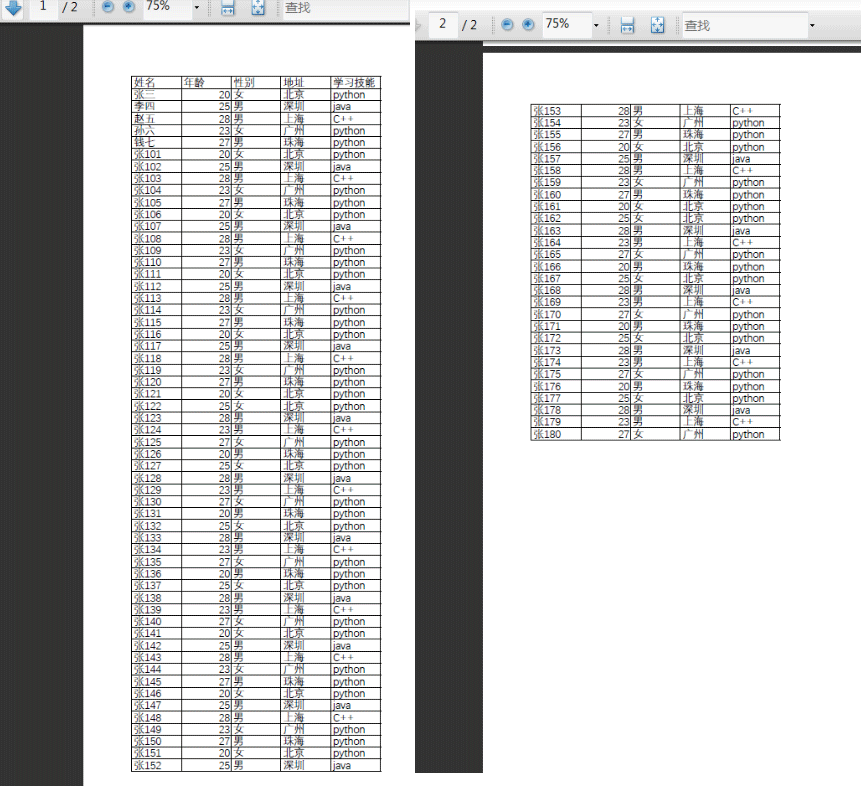
pdf文件如下:
import pdfplumber
# 加載pdf
path = "C:/Users/Administrator/Desktop/test08/test11 - 多頁.pdf"
with pdfplumber.open(path) as pdf:
print(pdf)
print(type(pdf))
# 讀取pdf文檔信息
print("pdf文檔信息:", pdf.metadata)
# 輸出總頁數
print("pdf文檔總頁數:", len(pdf.pages))
# 1.讀取第一頁寬度、高度等信息
first_page = pdf.pages[0] # pdfplumber.Page對象第一頁
# 查看頁碼
print('pdf頁碼:', first_page.page_number)
# 查看頁寬
print('pdf頁寬:', first_page.width)
# 查看頁高
print('pdf頁高:', first_page.height)
# 2.讀取文本第一頁
first_page = pdf.pages[0] # pdfplumber.Page對象第一頁
text = first_page.extract_text()
print(text)執行結果:
"D:\Program Files1\Python\python.exe" D:/Pycharm-work/pythonTest/打卡/0811讀取pdf.py
<pdfplumber.pdf.PDF object at 0x0000000002846278>
<class 'pdfplumber.pdf.PDF'>
pdf文檔信息: {'Author': '', 'Comments': '', 'Company': '', 'CreationDate': "D:20220812102327+02'23'", 'Creator': 'WPS 表格', 'Keywords': '', 'ModDate': "D:20220812102327+02'23'", 'Producer': '', 'SourceModified': "D:20220812102327+02'23'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
pdf文檔總頁數: 2
pdf頁碼: 1
pdf頁寬: 595.25
pdf頁高: 841.85
姓名 年齡 性別 地址 學習技能
張三 20 女 北京 python
李四 25 男 深圳 java
趙五 28 男 上海 C++
孫六 23 女 廣州 python
錢七 27 男 珠海 python
張101 20 女 北京 python
.......
.......
張150 27 男 珠海 python
張151 20 女 北京 python
張152 25 男 深圳 javaProcess finished with exit code 0
import pdfplumber
import xlwt
# 加載pdf
path = "C:/Users/Administrator/Desktop/test08/test11 - 多頁.pdf"
with pdfplumber.open(path) as pdf:
page_1 = pdf.pages[0] # pdf第一頁
table_1 = page_1.extract_table() # 讀取表格數據
print(table_1)
# 1.創建Excel對象
workbook = xlwt.Workbook(encoding='utf8')
# 2.新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3.自定義列名
clo1 = table_1[0]
# 4.將列表元組clo1寫入sheet表單中的第一行
for i in range(0, len(clo1)):
worksheet.write(0, i, clo1[i])
# 5.將數據寫進sheet表單中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(clo1)):
worksheet.write(i + 1, j, data[j])
# 保存Excel文件分兩種
workbook.save('test88.xls')執行結果:
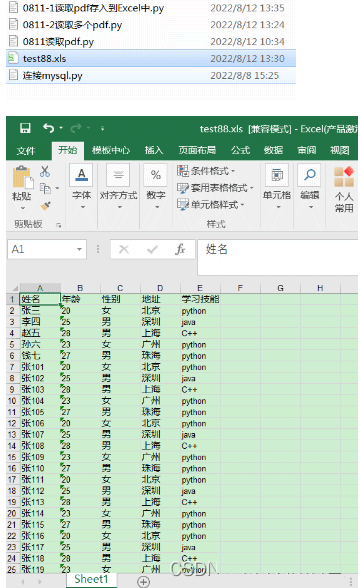
感謝各位的閱讀,以上就是“Python操作pdf pdfplumber讀取PDF寫入Exce”的內容了,經過本文的學習后,相信大家對Python操作pdf pdfplumber讀取PDF寫入Exce這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





